什么是hive
hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL 查询功能。
FaceBook公司在使用Hadoop实现数据分析的时候,发现有个毛病:会做分析的人如业务人员、数据分析师,会用SQL ;会用Hadoop实现分布式开发是开发人员
方案一:让开发人员教业务写代码,成本比较高
方案二:让开发人员对Hadoop做一层封装,开发一个新的程序,封装以后新的程序提供SQL 接口,在新的程序中用SQL 进行开发,这个程序底层自动将SQL 转为MapReduce程序提交给YARN去运行。最早的Hive就诞生了
hive主要是用来做海量数据的分析和计算。
hive是一个Hadoop客户端,用于将HQL(hive SQL )转化成mapreduce程序。
hive中每张表的数据都存储在hdfs。
hive分析数据底层的实现是mapreduce(也可配置为spark或者tez,tez是一个大数据框架)
hive执行程序运行在yarn上。
Hive特点
Hive 通过类 SQL 来分析大数据,而避免了写 MapReduce 程序来分析数据,这样使得分析数据更容易
Hive 是将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库上(比如 MySQL)
Hive 本身并不提供数据的存储功能,数据一般都是存储在 HDFS 上的(对数据完整性、格式要求并不严格)
Hive 很容易扩展自己的存储能力和计算能力,这个是继承自 hadoop 的(适用于大规模的并行计算)
Hive 是专为 OLAP (在线分析处理) 设计,不支持事务。补充:OLTP (Online transaction processing):在线事务处理,支持事务。
hive架构
hive底层架构是Hadoop
hive执行组件分为metastore和hiveserver2
metastore提供元数据访问接口。只负责提供元数据接口,不负责存储。通常存储在MySQL数据库或者derby数据库中。推荐MySQL
hiveserver2提供jdbc或者ODBC访问接口,提供用户认证的相关功能。
hive客户端hive client分为CLI或者jdbc/ODBC
安装了hive的机器可以使用命令行客户端CLI,其他机器使用jdbc协议或者ODBC协议访问。
hive执行流程简介
1. 用户创建table ,create table
2. metastore会把表保存到元数据中,记录对应表的路径。
3. 用户建表指定了hdfs文件路径,跟metastore形成映射关系。
4. 用户根据业务需要编写SQL 执行查询。调用driver驱动编译SQL 。如果使用的命令行客户端,则driver运行在CLI中。如果使用的是jdbc或者ODBC,则driver运行在jdbc/ ODBC上。driver的主要作用就是将SQL 编译成最终的mapreduce程序。需注意编译过程中需要用到元数据信息。
5. 编译完成后,driver就会将mapreduce程序提交到yarn上运行,还可以提交到tez/ spark等计算引擎,如果是插入语句,将计算结果写到hdfs目标路径。如果是查询语句,将结果返回给hive client客户端。
driver具体工作(词法分析和语法分析)
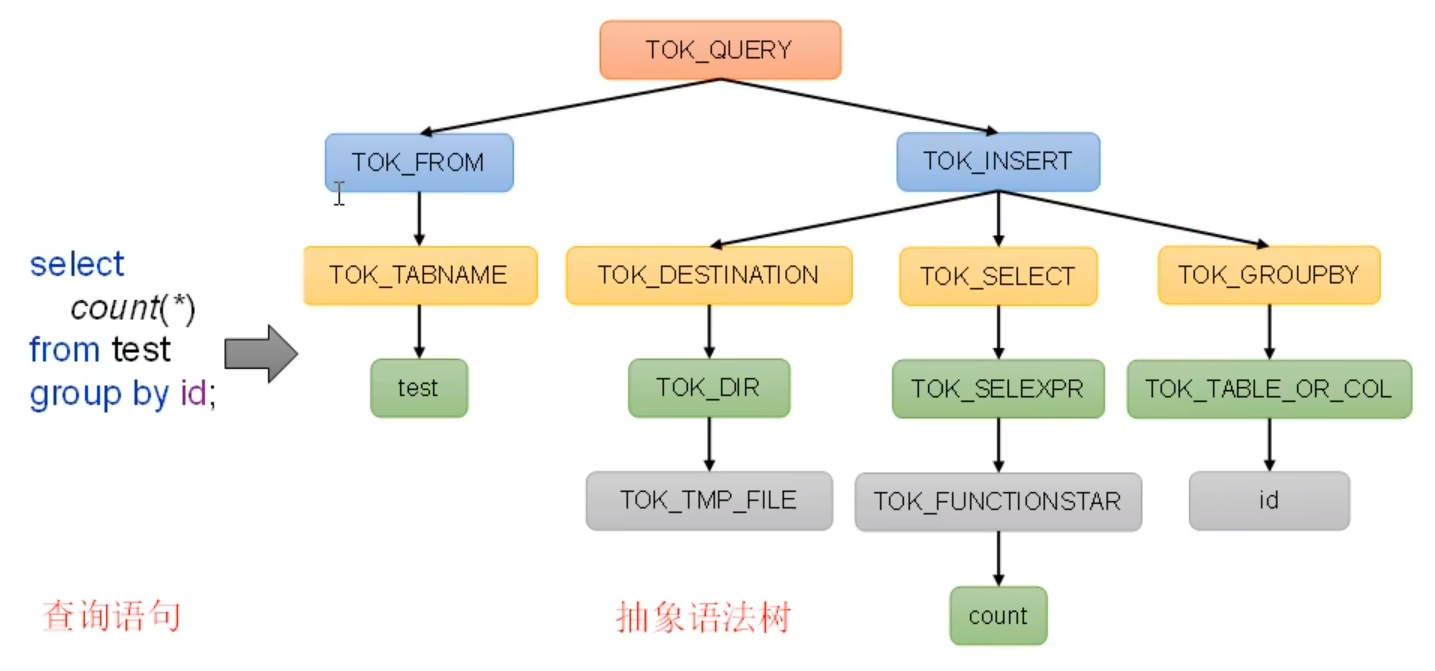
1. 解析器sqlParser:将SQL 字符转换成抽象语法树AST。分为词法分析器和语法分析器。词法分析器主要对字符串进行扫描,识别关键字形成token,比如select ,where 等token。语法分析器对前面的token进行进一步分析,根据预先设置的规则将token组成短句,比如将where 条件组合成表达式,where name= value 。然后将表达式组成完整语句,无论写程序还是SQL 往往都是分成一层一层的,通常这些分层的树状结构称作抽象语法树。
2. 语义分析semantic analyzer:将AST进一步划分为queryblock。将语法树解析成查询单元,可以理解为一个个子查询。除此之外还会获得元数据信息赋给每一个查询单元,如查询表的hdfs路径等。如果查询语句比较简单只有一句SQL ,那就只有一个query block;
3. 逻辑计划生成器logic plan gen:将语法树生成逻辑执行计划。
4. 逻辑优化器logical optimizer:对逻辑计划进行优化。举例:谓词下推,将整个执行计划中的filter 操作往前移。这个操作在逻辑优化器中完成。谓词就是返回boolean 值即true 和false 的函数,或是隐式转换为bool的函数。SQL 中的谓词主要有 LKIE、BETWEEN 、IS NULL 、IS NOT NULL 、IN 、EXISTS 其结果为布尔值,即true 或false 。谓词的使用场景:在SELECT 语句的WHERE 子句或HAVING 子句中,确定哪些行与特定查询相关。
5. 物理计划生成器physical plan gen:根据优化后的逻辑计划生成物理计划。
6. 物理优化器physical optimizer:对物理计划进行优化。map join 操作,
7. 执行器execution:执行该计划,得到查询结果并返回客户端。将最终生成的物理执行计划提交到yarn资源管理器上执行。
小表:能够缓存在给定的内存当中的表叫做小表。
hive建表可以指定hdfs路径,如果没指定会使用默认路径,/ user / hive/ warehouse/ tmp
hive自带了derby数据库可以用来保存元数据。路径存在hive/ metastore_db中。
只能有一个hive进程使用metastore_db。如果存在已经运行的hive进程占用了metastore_db,再启动hive会报错。
hive安装
1 .创建元数据库。生产环境下hive元数据存储在MySQL中。安装MySQL,创建名为metastore的数据库。用来存储元数据。
2 . 放入驱动需要将MySQL的jdbc驱动放到hive的lib目录下,
3 . 配置文件,需要在conf目录下创建hive-site.xml文件,指定jdbc连接信息url,password,工作目录等。
4 . 初始化hive元数据库bin/schematool -dbType mysql -initSchema -verbose。
5 . 验证是否安装成功 bin/hive。
6 . 查看MySQL中的元数据。登录MySQL,mysql -uroot -p 123456
show databases
hive服务部署
hive的hiveserver2服务的作用是提供jdbc/ODBC 接口,为用户提供远程访问hive数据的功能。
远程访问hive数据时,客户端并未直接访问Hadoop 集群,而是由hiveserver2代理访问。
jps -ml可查看进程详细信息。
后台启动不保存日志,1 表示进程描述符输出,0 表示输入,2 表示标准错误。表示将标准输出,标准错误都写入到/dev/null 黑洞中。 nohup bin/hiveserver2 1 >/dev/ null 2 >/dev/ null &
hive语法
hive - e可以执行SQL 命令。 hive - e " insert into stu values(1,'aa')";
hive - f可以执行文件内的SQL 。将上述插入语句放入一个文件中,vim stu.sql 写入如下SQL insert into stu values (1 ,'aa' )
保存推出,然后执行hive - f stu.sql。效果等同于hive - e 执行SQL
hive - hiveconf 可以在命令行添加hive参数。如hive - hiveconf mapreduce.job.reduces= 10 ;
hive 进入客户端,使用set 配置客户端参数,set mapreduce.job.reduces= 5 ;
hive建表语法
普通建表
create [temporary] [external] table [if not exits]
[dbname.] table
[(col_name data_type [comment col_comment] ,...)]
[comment table_comment]
[partitioned by (col_name data_type [comment col comment] ,...)]
[cluster by (col_name)]
[sort by (col_name [asc] [desc] ,...) into num_buckets buckets ]
[row format row_format]
[stored as file_format]
[location hdfs_path]
[tblproperties (property_name=property_value,...)]
关键字说明:
temporary :临时表,会话结束表会删除。
external :外部表,意味着hive 只接管元数据,不完全接管hdfs 中的数据。与之对应的是内部表(管理表),意味着hive 完全接管该表,包括元数据和hdfs 中的数据。
data_type :字段类型。多种详情百度。注意类型转换,隐式转换和显示转换。显示:cast (expr as <type>)
partitioned by :创建分区表。把一张表的数据,按照指定的分区字段,将数据分到不同的路径中。一个路径对应的就是hive 的一个分区
cluster by ... sorted by ...into ...buckets :创建分桶表。将hive 一张表的数据,分散的存储到多个文件中,通过cluster by 指定一个字段,into 指定多少个桶,sorted by 指定的字段在每一个分桶里面进行排序。
row format :指定serde ,是serializer and deserializer 的简写。hive 使用serde 序列化和反序列化每行数据。
CTAS 建表,create table as select 语法
该语法利用查询结果建表,结构与查询的结果表结构一致,包含查询结果。
create [temporary] table [if not exists] table_name
[comment table_comment]
[row format row_format]
[stored_as file_format]
[location hdfs _path]
[tblproperties (property_name = property_value,..)]
[as select_statement]
create table teacher1 as select * from teacher ;
CTL 建表,create table like 语法
该语法允许用户复刻一张已经存在的表结构,与CTAS 不同,不包含数据。
create [temporary] table [if not exists] table_name
[dbname.] table
[like exist_table_name]
[row format row_format]
[stored_as file_format]
[location hdfs _path]
[tblproperties (property_name = property_value,..)]
create table teacher2 like teacher ;
删除表
drop table table_name;如果是外部表,则只会删除元数据,需要手动删除hdfs上的数据。
truncate [table ] table_name;truncate 只能清空管理表(内部表),无法清空外部表数据。只清空数据,保留数据表结构。
load
load语句将文件导入到hive表中。
load data [local ] inpath 'filepath' [overwrite] into table tablename [partition (col1 = val1,col2= val2,...)];
local :表示从本地加载数据到hive表,相当于hadoop fs put操作;否则从hdfs加载数据到hive表。
overwrite:表示覆盖表中一有数据,否则表示追加。
partition :表示上传到指定分区,若目标是分区表,需要指定分区。
insert
1. 将查询结果插入表中。语法:insert (into | overwrite) table tablename [partition (col1 = val1,col2= val2,...)] select_statement;
into 追加。overwrite覆盖。
注意区分load和insert 的语法。load覆盖是在into 前加上overwrite,而insert 是将into 替换成overwrite。
2. 将给定values 插入表中。
insert (into | overwrite) table tablename [partition (col1 = val1,col2= val2,...)] values valuse_row[,valuse_row...];
3. 将查询结果写入目标路径。
insert overwrite [local ] directory 'directory' [row_format row_format] [stored as file_format] select_statement;
export && import
export 导出语句可将表的数据和元数据信息一并导出到hdfs路径,
import 可将export 导出的内容导入hive,表的数据和元数据信息都会恢复。
export 和import 可用于两个hive实例之间的数据迁移。(两个hive实例表示两个不同的Hadoop集群)
语法示例:
export table default .student to '/user/hive/warehouse/export /student';
import table default .studept2 from '/user/hive/warehouse/export /student';
查询
基本语法:
select [all | distinct ] select_expr,select_expr,...
from table_reference
[where ]
[group by ]
[having ]
[order by ]排序
[cluster by ]
[distribute by ]
[sort by ]
[limit number]
join
join 是对两个表或者多个表进行横向的拼接。
hive支持通常的SQL join 语句,支持等值连接,在2.2 版本之后支持非等值连接。
等值连接& 不等值连接:
select * from a join b on a.num = b.num;等值连接
select * from a join b on a.num > b.num;< ,!= 不等值连接,不常见。
内连接:交集。inner join 和只写join 都表示内连接,只有连接的两个表中都存在条件相匹配的数据才会被保留下来。返回结果行数是两个表都匹配的行。
左外连接:left join 和left outer join 都表示左外连接,以左表为准。返回结果行数跟左表相同,包含左表所有列和右表所有列。
右外连接:right join 和right outer join 都表示右外连接,以右表为准。返回结果行数跟右表相同,包含右表所有列和左表所有列。
满外连接:full join 和full outer join 都表示满外连接。左表和右表的所有行和所有列。
多个表连接:第一种写法,先连接前两个表,再用连接结果跟第三个表连接。
select * from emp
join detp
on emp.deptno = dept.deptno
join location
on dept.loc = location.loc;
第二种写法,将前两个表查询嵌套起来,再跟第三个表连接。
select * from (
select * from emp
join dept
on emp.deptno = dept.deptno
)t1
join location
on t1.loc = location.loc;
笛卡尔积,a表m行,b表n行。a表的每一行都会跟b表的每一行连接。返回结果m* n行。
什么时候会产生笛卡尔积?
不写连接条件时就会产生。如只写个内连接,没有连接条件或者连接条件无效,结果就会产生笛卡尔积。
select * from a join b;
select * from a join b on true ;
select * from a,b;
union && union all
union 将两张表或者多张表进行纵向拼接。要求上下两张表字段个数必须一致。上下两张表字段类型必须一致。
select * from emp
where deptno = 30
union
select * from emp
where deptno = 40 ;
注意:union 连接的是两个或者多个select 查询语句。不能直接连接表。
union all 不会对相同结果去重。union 会对上下两个结果进行去重。上下两个结果完全相同才会去重。
order by
asc升序,默认升序。
desc降序。
select * from a order by id desc limit 100 ;
在hive中使用order by 比较高危。底层执行计划也是通过一个MapReduce来完成计算的,在执行 order by 是全局排序,尽量加上limit。
distribute by
指定分区字段。MapReduce的字段
sort by
指定排序字段,map到reduce的字段
cluster by
当distribute by 和sort by 字段相同时,可以使用cluster by 方式,顶替distribute by 和 sort by 作用。兼具这两者功能。
order by 与sort by 区别是什么?
order by 是全局排序,只有一个reduce。对于大规模的数据集不需要全局排序,所以使用sort by 局部排序,为每个reduce产生一个排序文件,每个reduce内部进行排序,对全局结果来说不是排序。
练习sort by ,先设置reduce个数
set mapreduce.job.reduces=3
select * from emp sort by deptno desc;
insert overwrite local directory '/data/bigdata/database/erp/sortby-result' select * from emp sort by deptno desc
函数
hive会将常用的逻辑封装成函数给用户使用,类似于Java中的函数。
hive函数可分为:单行函数,聚合函数,炸裂函数,窗口函数。
查看所有内置函数: show functions;
查看内置函数用法:desc function upper;
查看内置函数详细信息:desc function extended upper;
单行函数:
算术运算符函数:
+-*/% &按位取与|按位取或^按位取异或~按位取反
数值函数:
round(num[,d])四舍五入,可选保留几位小数,不选的话默认整数。round(-1.5 )结果为-2 。round(3.3 ,2 )结果为3.30 ;
ceil向上取整。floor向下取整。
字符串函数:
substring(str,begin[,end]);select substring ('zzzssskkk' ,-4 'zzz' ,'z' ,'Z' )。替换,select replace ('zsk' ,'z' ,'Z' 'zzz-123-zzz' ,'[0-9]' ,'*' )。select regexp_replace ('100-200' ,'(\\d+)' ,'num' select 'dfsaaa' regexp 'dfsa+'string A,int n)重复字符串。将字符串重复n遍。
split(string str,string pat)返回一个数组。split('a-b-c' ,'-' )输出["a" ,"b" ,"c" ]
nvl(A,B)替换null 值,若A的值不为null ,则返回A,否则返回B。
concat(string A,string B,...)拼接字符串,返回string 。select concat ('beijing' ,'-' ,'shanghai' shanghai
concat_ws (string A,string B,...| array(string select concat_ws ('-' ,array('a' ,'b' ,'c' ;返回a-b-c
get_json_object (json_string,string value ):解析JSON字符串,返回指定的value 内容。
举例1,获取JSON数组里面的JSON具体内容:select get_json_object ('[{"name":"zzz","sex":"男","age":"25"},{"name":"sss","sex":"男","age":"26"},{"name":"kkk","sex":"男","age":"27"}]' ,'$[0].name' ;输出zzz
举例2 ,获取JSON数组里面的数据:select get_json_object ('[{"name":"zzz","sex":"男","age":"25"},{"name":"sss","sex":"男","age":"26"},{"name":"kkk","sex":"男","age":"27"}]' ,'$[0]' "name" :"zzz" ,"sex" :"男" ,"age" :"25" }
日期函数:
unix_timestamp():返回当前或者指定时间的零时区时间戳。unix时间戳。UTC时间零时区的1970 -01 -01 00 :00 :00 到现在的时间秒数。
select unix_timestamp ('2023/04/01 00-00-00' ,'yyyy/MM/dd HH-mm-ss' string ,date):将时间戳转回时间,零时区。select from_unixtime (1680508156 ,'yyyy/MM/dd HH-mm-ss' select from_utc_timestamp (cast(1680508156 as bigint ) *1000,'GMT+8')1000 后超过了integer的范围,必须转成bigint再*,否则结果不对。
date_format(from_utc_timestamp(cast(1680508156 as bigint) *1000 ,'GMT+8' ),'yyyy/MM/dd HH-mm-ss' );对时间结果进行格式化。
current_date:返回当前日期,只有年月日。select current_date ()select month ('2023-04-04 00:00:00' select datediff ('2023-04-04 01:00:00' ,'2023-04-01 00:00:00' '2023-04-04 01:00:00' ,1 );加一天。返回结果只有日期2023 -04 -05
date_add('2023-04-04 01:00:00' ,-1 );减一天。返回结果只有日期2023 -04 -03
date_sub('2023-04-04 01:00:00' ,1 )减一天。返回结果只有日期2023 -04 -03
流程控制函数:
case
select
id,
case
when id>9 then 10
else id
end
from student;
集合函数:
sort_array(array(3 ,1 ,2 ,5 ,4 ));数组排序,不能自定义排序规则。
array_contains(array(3 ,1 ,2 ,5 ,4 ),2 );是否包含数组。
size(array(3 ,1 ,2 ,5 ,4 ));返回array元素个数。
map(key1,value1,key2,value2,...);根据输入的key和value 键值对构建map类型,select map ('zzz' ,1 ,'sss' ,2 select map_keys (map('zzz' ,1 ,'sss' ,2 ))'zzz' ,'sss' ]
map_values(); 返回所有value ,类型为数组。select map_values (map('zzz' ,1 ,'sss' ,2 ))1 ,2 ]
struct (val1,val2,val3,...);根据输入的参数构建结构体struct 类。select struct ('name' ,'age' ,'weight' "col1" :"name" ,"col2" :"age" ,"col3" :"weight" }
named_struct()声明struct 的属性和值。select named_struct ('name' ,'zzz' ,'sss' ,'18' ,'kkk' ,80 "name" :"zzz" ,"sss" :"18" ,"kkk" :80 }
聚合函数:
count,sum..
高级聚合函数:
collect_list收集并形成list集合,结果不去重。返回数组类型
select sex,collent_list(job) from employee group by sex;
collect_set收集并形成set 集合,结果去重。返回数组类型
select sex,collect_set(job) from employee group by sex;
炸裂函数:UDTF制表函数
UDTF(Table - Generating Functions),接收一行数据,输出一行或多行数据。
常用UDTF——explode(array < T> a),功能:给定一个数组,将数组炸裂成多行。select explode(array (1 ,2 ,3 )) as item;
常用UDTF——explode(Map< k,v> m),给定一个map,将map炸裂成多行键值对。select explode(map("a",1 ,'b' ,2 ,'c' ,3 )) as (key,value ); 去掉别名as (key,value ),默认也是key和value 字段名。
常用UDTF——posexplode(array < T> a),给数组添加角标,返回键值对。select posexplode(array ("a","b","c")) as (pos,item);
常用UDTF——inline(array < struct< f1:t1,...,fn:tn>> a),select inline(array (named_struct('id' ,1 ,'name' ,'z' ),named_struct('id' ,2 ,'name' ,'s' ),named_struct('id' ,3 ,'name' ,'k' ))) as (id,name);
lateral view :通常与UDTF配合使用。lateral view 可以将UDTF应用到源表的每行数据,将每行数据转换为一行或多行,并将源表中每行的输出结果与改行连接起来,形成一个虚拟表。
select id,name,hobbies,hobby from person lateral view explode(hobbies) tmp as hobby;/ / 解释:later view 连接源表内容以及炸裂出来的内容。tmp表示炸裂出来的表别名,as hobby是炸裂出来的字段名。
案例:select cate,
count (* )
from (
select movie,
split(category,',' )category
from movie_info
)t1 lateral view explode(category) tmp as cate
group by cate;
窗口函数:
定义:能为每行数据划分一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行数据。
语法:窗口函数的语法主要包括窗口和函数两部分。窗口用于定义计算范围,函数用于定义计算逻辑。
指定窗口范围的时候一定要声明一个order by 字段,告知窗口按照哪个字段来排序。因为窗口需要有序。如果不声明order by 字段,则窗口中的数据是随机的,不便于计算。
select order_id,order_date,amount,函数(amount)over (窗口范围) total_amount from order_info;
绝大多数的聚合函数都可以配合窗口使用,max(),min(),sum(),count(),avg()等。
select order_id,amount,sum (amount)over (窗口范围)total_amount from drder_info;
窗口范围的定义分为两种类型,一种是基于行的(例如窗口范围是上一行到当前行),一种是基于值的(例如值位于-1 到当前值的范围)。
基于行:
select order_id,
order_date,
amount,
sum (amount) over (order by order_date rows between unbounded preceding and current row ) total_amount
from order_info;/ / 注释:order_date 为声明的排序字段,rows 表示基于行, unbounded preceding and current row 表示负无穷到当前行。
基于值:
select order_id,
order_date,
amount,
sum (amount) over (order by order_date range between unbounded preceding and current row ) total_amount
from order_info;/ / 注释:range 表示基于值的,unbounded preceding and current row 表示负无穷到当前值。
窗口分区:
定义窗口范围时,可以指定分区字段,每个分区单独划分窗口。
select order_id,
order_date,
amount,
sum (amount) over (partition by user_id order by order_date rows between unbounded preceding and current row ) total_amount
from order_info;/ / 可以按照user_id分区计算窗口内的结果。
窗口缺省:
over ()中的三部分内容partition by 、order by 、(rows | range )between...and...均可省略不写。
partition by 省略不写,表示不分区。
order by 省略不写,表示不排序。
(rows | range )between...and...省略不写,则使用默认值。默认值如下:
若over ()中包含order by ,则默认值为range between unbounded preceding and current row / / 有排序,默认值排序
若over ()中不包含order by ,则默认值为rows between unbounded preceding and unbounded following / / 没排序,默认行排序
跨行取值函数:
lead和lag:获取当前行的上/ 下面某行、某个字段值。lead下,lag上。
lag (字段名,偏移量,默认值)上
lead (字段名,偏移量,默认值)下
select order_id,
user_id,
order_date,
amount,
lag (order_date,1 ,'1970-01-01' ) over (partition by user_id order by order_date) last_date,
lead (order_date,1 ,'9999-01-01' ) over (partition by user_id order by order_date) next_date,
from order_info;
first_value和last_value:获取窗口内某一列的第一个值/ 最后一个值。
first_value (字段名,是否跳过null )获取该字段的第一个值
last_value (字段名,是否跳过null )获取该字段的最后一个值
select order_id,
user_id,
order_date,
amount,
first_value (order_date,false ) over (partition by user_id order by order_date) first_date,
last_value (order_date,false ) over (partition by user_id order by order_date) last_date,
from order_info;
排名函数:
rank稀疏排名,dense_rank密集排名,row_numger顺序排名。用于排名,均不支持自定义窗口。
select
stu_id,
course,
score,
rank () over (partition by course order by score desc )rk,
dense_rank () over (partition by course order by score desc ) dense_rk,
row_number () over (partition by course order by score desc ) rn
from score_info;/ / rank稀疏排名,顺序如1 、1 、3 、4 ,dense_rank密集排名,顺序如1 、1 、2 、3 ,row_numger顺序排名,顺序如1 、2 、3 、4 。
自定义函数:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class MyHive extends GenericUDF {
@Override
public ObjectInspector initialize (ObjectInspector[] objectInspectors) throws UDFArgumentException {
if (objectInspectors.length!=1 ){
throw new UDFArgumentException ("只接收一个参数" );
}
ObjectInspector objectInspector = objectInspectors[0 ];
if (ObjectInspector.Category.PRIMITIVE != objectInspector.getCategory()){
throw new UDFArgumentException ("只接收基本数据类型的参数" );
}
PrimitiveObjectInspector category = (PrimitiveObjectInspector) objectInspector;
if (category.getPrimitiveCategory()!= PrimitiveObjectInspector.PrimitiveCategory.STRING){
throw new UDFArgumentException ("只接收String类型的参数" );
}
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
@Override
public Object evaluate (DeferredObject[] deferredObjects) throws HiveException {
DeferredObject deferredObject = deferredObjects[0 ];
Object o = deferredObject.get();
if (o == null ){
return 0 ;
}else {
return o.toString().length();
}
}
@Override
public String getDisplayString (String[] strings) {
return null ;
}
}
创建自定义临时函数:
1. 先将自定义的函数打好jar包,放到服务器上。执行add jar /opt/jar_path/xxx.jar;
2. 执行创建命令:create temporary function my_len as "com.hive.udf.MyLength"
3. 查看创建的函数:show functions like 'my_len' ;
4. 调用自定义函数:select my_len ("abc" ) ;
创建自定义永久函数:
1. 先将自定义的函数打好jar包,上传到hdfs路径上。
2. 执行创建命令:create function my_len2 as "com.hive.udf.MyLength" using jar "hdfs:/hadoop102:8020/udf/myudf.jar" ;
3. 查看创建的函数:show functions like '*my_len*' ;
4. 调用自定义函数:select middle.my_len("abc" );
分区表
hive中的分区就是把一张大表的数据,按照业务需要分散地存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where 子句中的表达式,选择查询时所需的分区,这样的查询效率会提高很多。
创建分区表:
create table dept_partition(
deptno int comment '部门编号' ,
dname string comment '部门名称' ,
loc string comment '部门位置'
) partition by (day string) / / 指定分区字段,该字段可以认为是hive表中的字段,能拿来查询和where 过滤等操作
row format delimited fields terminated by '\t' ;
写数据:load
往分区表中写数据的时候,必须指定分区day 等于多少。
load data local inpath '/data/filepath/xx.txt' into table detp_pertition partition (day = '2022-02-22' );
写数据:insert
insert overwrite table detp_pertition partition (day = '2022-02-22' )
select deptno,dname,loc
from detp_pertition
where day = 2022 -02 -22 ;
读数据:
查询分区表数据时,可以将分区字段看作表的伪列,可像使用其他字段一样使用分区字段。查询的时候,分区字段day 能正常显示,其实是取自于hdfs的路径目录day = 2022 -02 -22
select deptno,dname,loc,day from dept_partition where day = 2022 -02 -22 ;
查看所有分区信息:
show partitions dept_partition;
增加分区:
执行这个命令,首先会在hdfs上创建该路径,然后在hive的元数据里增加一条分区信息。metastore数据库,t bls表
增加单个分区:alter table dept_partition add partition (day = '2022-02-22' );
增加多个分区用空格隔开。
增加多个分区: alter table dept_partition add partition (day = '2022-02-22' ) partition (day = '2022-02-23' );
删除分区:删除分区的同时,也会将hdfs上的路径删除。以及删除hive上的元数据信息。
删除单个分区::alter table dept_partition drop partition (day = '2022-02-22' );
删除多个分区用逗号隔开
删除多个分区::alter table dept_partition drop partition (day = '2022-02-22' ),partition (day = '2022-02-23' );
内部表和外部表的区别?
外部表删除表的时候,只会删除元数据,不会删除hdfs上的路径。
如果是内部表,又称管理表。元数据和数据都由hive管理,因此drop table 的时候会删除MySQL中的元数据以及hdfs上的路径。
删除分区的时候同理,外部表只会删除元数据里的分区信息,不会删除hdfs上的路劲。内部表会删除元数据的分区信息和hdfs路径。
修复分区:
hive将分区表的所有分区信息都保存在元数据中,只有元数据与hdfs上的分区路径一致时,分区表才能正常读写数据。若用户手动创建删除分区路径,hive都是感知不到的,这样就会导致hive的元数据和hdfs的分区路径不一致。再比如,分区表为外部白哦,用户执行drop partition 命令后,分区元数据会被删除,而hdfs的分区路径不会被删除,同样会导致hive的元数据和hdfs的分区路径不一致。若出现不一致的情况,可通过如下手段修复分区。
1. add partition :若手动创建hdfs的分区路径,hive无法识别,可通过add partition 命令增加分区元数据信息,从而使元数据和分区信息保持一致。
2. drop partition :若手动删除hdfs的分区路径,hive无法识别,可通过drop partition 删除分区元数据信息,从而使元数据和分区信息保持一致。
3. msck:若分区元数据和hdfs分区路径不一致,还可使用msck。全称是metastore check 。
msck repair table table_name add partitions;该命令会增加hdfs路径存在但元数据缺失的分区信息。
msck repair table table_name drop partitions;删除hdfs路径已经删除但元数据仍然存在的分区信息。
msck repair table table_name sync partitions;同步hdfs路径和元数据分区信息,相当于同时执行上述两个命令。
msck repair table table_name;等价于msck repair table table_name add partitions命令。
二级分区:
如果一天内的日志数据量也很大,如何将数据再拆分。答案是二级分区表,例如可以在按天分区的基础上,再对每天的数据按小时分区。
创建分区语句:
create table dept_partition2(
deptno int comment '部门编号' ,
dname string comment '部门名称' ,
loc string comment '部门位置'
) partition by (day string,hour string)
row format delimited fields terminated by '\t' ;
数据装载语句:
load data local inpath '/data/filepath/xx.txt' into table detp_pertition2
partition (day = '2022-02-22' ,hour = '12' );
查询分区数据:
select *
from dept_partition2
where day = '2022-02-22' and hour = '12' ;
动态分区:
动态分区是指向分区表insert 数据时,被写往的分区不能由用户指定,而是由每行数据的最后一个字段的值来动态的决定。使用动态分区,可只用一个insert 语句将数据写入多个分区。
相关参数:
1. 动态分区功能总开关,默认true ,开启。 set hive.exec.dynamic.partition= true ;
2. 严格模式和非严格模式。默认严格模式strict,要求必须指定至少一个分区为静态分区。非严格模式nonstrict,允许所有的分区字段都使用动态分区。set hive.exec.dynamic.partition.mode= nonstrict
3. 一条insert 语句可同时创建的最大的分区个数,默认为1000 。set hive.exec.dynamic.partitions= 1000
4. 单个mapper或者reducer可同时创建的最大的分区个数,默认为100 。set hive.exec.dynamic.partitions.pernode= 100
5. 一条insert 语句可以创建的最大的文件个数,默认100000 。hive.exec.max.created.files= 100000
6. 当查询结果为空时且进行动态分区时,是否抛出异常,默认false 。hive.error.on.empty.partition= false
分桶表
分桶表的基本原理是,先为每行数据计算一个指定字段的数据的hash值,然后取模一个指定的分桶数,最后将取模结果相同的行,写入同一个文件中,这个文件就称为一个分桶bucket。
create table stu_buck(
id int ,
name string
)cluster by (id) / / 按照id分桶
into 4 buckets / / 分桶数量为4
row format delimited fields terminated by '\t' ;
分桶:cluster by (colum) stored by into 4 buckets,按照某字段分桶,分成4 个桶。
分区:partition by (colum) ;分区是多个目录存放,分桶是多个文件存放。
提问:分4 个桶,但是只有3 个文件,导入数据后会有几个文件。4 个,有一个为空。
分桶排序:cluster by (id) sorted by (id) 分桶与排序字段可以一致,也可以不一致,跟业务有关。
文件格式与压缩:压缩方式hive与Hadoop保持一致。
压缩方式:snappy解压快,gzip压缩后文件小。默认是textfile
语法:stored as textfile 默认就是text文件。
ORC:全称optimized row columnar。翻译为优化后的行列。
ORC是hive0.11 版本引入的一种列式存储的文件格式。
hive数据存储格式可选:text file、ORC、parquet、sequence file
ORC使用:create table ... stored as ORC ,不需要声明row format delimited fields terminated by '\t' ;只有文本文件才需要声明分隔符。
ORC支持的参数:
orc.compress:表示ORC文件的压缩类型,常与snappy、none 、ZLB同用。「可选的类型有NONE 、ZLB和SNAPPY,默认值是ZLIB(Snappy不支持切片)」—这个配置是最关键的。
orc.compress.size:表示压缩块( chunk)的大小,默认值是262144 (256 KB)。解压orc需要拿到完整的块。
orc.stripe.size:通常一个stripe作为一个block存储,设置128 MB.写 stripe,可以使用的内存缓冲池大小,默认值是67108864 (64 MB)。
orc. row. index.stride:行组级别索引的数据量大小,默认是10000 ,必须要设置成大于等于10000 的数。索引步长的意思。
使用测试:
create table test... stored as orc; orc建表的简写方式,使用show create table test;可以查看orc建表的完整语法。
SERDE:用来序列化和反序列化。
往ORC表中load一个文本文件,能行的通吗?答:不能。orc的序列化方式未ORCFormat,往外读的时候,text文件不可读取。可以建一个临时表load进去,再通过insert...select..放入ORC表。
parquet文件格式:create table test... stored as parquet
hive on MR:运行于yarn,调优从MR和yarn入手。
yarn.nodemanager.resource.memory- mb:表示一个nm分配给container的总内存。
explain执行计划
explain呈现的执行计划,由一系列的stage组成,这一系列的stage具有依赖关系,每个stage对应一个MR的job,或者一个文件系统操作。
案例:执行计划
explain select user_id,count (*) from order_detail group by order_detail;
执行计划包含两部分,stage dependencies依赖关系和stage plans执行计划
hive sql优化
聚合优化
开启map-side聚合
set hive.map.aggr=true;
检测源数据表是否适合进行map-side聚合。先对若干数据进行map-side聚合,若聚合后的条数和聚合前的条数的比值小于该值,则认为该表适合进行map-side聚合,否则认为不适合,后续的数据便不再进行map-side聚合。此处可设置比值。
set hive.map.aggr.hash.min.reduction=0 .5 ;
检测源数据表适合进行map-side聚合的条数
set hive.groupby.map.aggr.checkinterval=100000 ;
检测map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0 .9 ;
join优化
hive包含多种join算法,包括common join,map join,bucket map join,sort merge bucket map join等。
common join:
是hive中最稳定的join算法,其通过一个mapreduce job完成一个join操作。如果不设置join算法的话,默认就是common join。map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过shuffle,将其发送到reduce端,相同key的数据在reduce端完成最终的join操作。
需要注意的是,SQL语句中的join操作和执行计划中的common join并非一对一的关系,一个SQL语句中相邻且关联字段相同的多个join操作可以合并为一个common join任务。a表join b表 join c表,底层MR任务可能为一个也可能为两个,不一定。如果A B C表三个的关联字段一样的话,只启动一个MR任务。MAP端读取三张表的id,在同一个shuffle中进行join,将结果发往同一个reduce。如果A B C三张表关联的字段不同,则先将A B表join,得到的中间结果再与C表进行join,此时就需要启动两个MR任务。
实例:select a.id,b.id,c.id from a join b on (a.key1 = b.key1) join c on (c.key1 = b.key1);启动一个MR任务。
select a.id,b.id,c.id from a join b on (a.key2 = b.key2) join c on (c.key2 = b.key2);启动两个MR任务。
Map join:
可以通过只有两个map阶段的job完成一个join操作。其使用场景为大表join小表。若某join操作满足要求,则第一个job会读取小表数据,将其制作为hash table,并上传至Hadoop分布式缓存(本质上是上传至HDFS)。第二个job会先从分布式缓存中读取小表数据,并缓存在MAP TASK的内存中,然后扫描大表数据,这样在map端即可完成关联操作。
Bucket Map Join
对map join的改进,打破了只适用于大表join小表的限制,可用于大表join大表的场景。
核心思想:若能保证参与join的表均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍,就能保证参与join的两张表的分桶之间具有明确的关联关系,所以就可以在量表的分桶间进行map join操作,这样一来,第二个job的map端就无需缓存小表的全部数据了,而只需缓存其所需的分桶即可。





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本