

apache spark
基本介绍
特点
性能特点
-
更快的速度
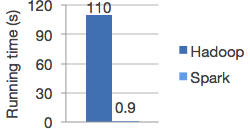
计算时间比较
-
易用性
-
通用性
-
支持多种资源管理器
spark的体系架构

spark的安装部署:
安装部署
准备工作:安装Linux、JDK等等
解压:tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz -C ~/training/
由于Spark的脚本命令和Hadoop有冲突,只设置一个即可(不能同时设置)配置文件:/root/training/spark-2.1.0-bin-hadoop2.7/conf/spark-env.sh
=============伪分布: hadoop153============
修改配置文件:spark-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
export SPARK_MASTER_HOST=hadoop153
export SPARK_MASTER_PORT=7077
slaves
hadoop153
启动:sbin/start-all.sh
Spark Web Console(内置Tomcat:8080) http://ip:8080
==============================================
执行Spark Demo程序(hadoop153:伪分布上)
1、执行Spark任务的工具
(1)spark-submit: 相当于 hadoop jar 命令 ---> 提交MapReduce任务(jar文件 )
提交Spark的任务(jar文件 )
Spark提供Example例子:/root/training/spark-2.1.0-bin-hadoop2.7/examples/spark-examples_2.11-2.1.0.jar
执行如下命令:
示例:蒙特卡罗求PI(3.1415926******)
>bin/spark-submit --master spark://Hadoop153:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 200

得到结果:

=============全分布:三台================
Master节点: bigdata112
Worker从节点:bigdata113 bigdata114
修改配置文件:spark-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
export SPARK_MASTER_HOST=bigdata112
export SPARK_MASTER_PORT=7077
slaves
bigdata113
bigdata114
复制到从节点上
scp -r spark-2.1.0-bin-hadoop2.7/ root@bigdata113:/root/training
scp -r spark-2.1.0-bin-hadoop2.7/ root@bigdata114:/root/training
在主节点上启动: sbin/start-all.sh
