customize the entry point of pod runtime
1. create a run.sh
#!/bin/sh get_cpu_list(){ cpus=$(cat /sys/fs/cgroup/cpuset/cpuset.cpus) cpu_l="" for i in $(echo $cpus | tr , " "); do # if [[ $i =~ "-" ]]; then if [ -z "${i##*-*}" ]; then bg=${i%%-*} en=${i##*-} for j in $(seq $bg $en);do if [ -z "$cpu_l" ]; then cpu_l=$j else cpu_l="$cpu_l $j" fi done else if [ -z "$cpu_l" ]; then cpu_l=$i else cpu_l="$cpu_l $i" fi fi done echo $cpu_l } allocate_cups(){ argv=$# if [ $# -le 2 ]; then echo "input $# arguments, it should not less than 2 arguments" return 1 fi CONF=$1 NUM=$2 if [ ! -e "$CONF" ]; then echo "The first argument is configure file, it does not exist!" return 1 fi if [[ ! -z "${NUM//[0-9]}" ]]; then echo "The second argument is required CPU numbers, it should be a number!" return 1 fi avaliable=$((argv - 2)) if [ "$avaliable" -lt "$NUM" ]; then echo "The process requires no less than $NUM, But k8s only allocate $avaliable to it!" return 1 fi echo "Please implement your CPU pin configure here, and call 5G CNF entry-point!" } CPUS=$(get_cpu_list) CONF=/bin/ls NUM=2 # required CPU numbers allocate_cups $CONF $NUM $CPUS echo "Hello from the script residing in helm chart." echo "New line added here." echo "Sleeping for eternity!" sleep infinity
2. create a configmap
kubectl create cm scripts-configmap --from-file run.sh \ --dry-run=client -o yaml | kubectl apply -f -
3. deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: echoscript
labels:
app: echoscript
spec:
replicas: 1
selector:
matchLabels:
app: echoscript
template:
metadata:
labels:
app: echoscript
spec:
containers:
- name: echoscript
image: fedora:32
command: ["/bin/bash"]
args: ["/scripts-dir/run.sh"]
resources:
limits:
cpu: "2"
memory: 200Mi
requests:
cpu: "2"
memory: 200Mi
volumeMounts:
- name: scripts-vol
mountPath: /scripts-dir
volumes:
- name: scripts-vol
configMap:
name: scripts-configmap
4. main.c
#define _GNU_SOURCE #include <sched.h> #include <stdio.h> #include <string.h> #include <stdlib.h> #include <unistd.h> #include <errno.h> int main(int argc, char **argv) { int cpus = 0; int i = 0; int num = 2; cpu_set_t mask; cpu_set_t get; cpus = sysconf(_SC_NPROCESSORS_ONLN); printf("cpus: %d\n", cpus); CPU_ZERO(&mask); /* init set,set is null*/ /*pin this process to CPU 2*/ if (argc > 1) { num = atoi(argv[1]); } printf("Set CPU affinity ID: %d\n", num); CPU_SET(num, &mask); if (sched_setaffinity(0, sizeof(mask), &mask) == -1) { printf("Set CPU affinity failue, ERROR:%s\n", strerror(errno)); return -1; } while(1) { sleep(1); } return 0; }
gcc -o test main.c
REF:
https://suraj.io/post/use-configmap-for-scripts/
Use Configmap for Scripts
A new way to ship scripts to container images.
https://www.starkandwayne.com/blog/silly-kubectl-trick-8-redux-configmaps/
Using Kubernetes ConfigMaps As Code - Stark & Wayne
Photo by Ryan Moulton on Unsplash A ConfigMap is a set of named bits of data. They allow Kubernetes operators to supply additional runtime configuration to the images they are spinning. They can be...
https://stackoverflow.com/questions/41674108/how-to-include-script-and-run-it-into-kubernetes-yaml
How to include script and run it into kubernetes yaml?
It is how to run simple batch in kubernetes yaml (helloworld.yaml): ... image: "ubuntu:14.04" command: ["/bin/echo", "hello", "world"] ... In Kubernetes i can deploy that like this: $ kubectl cr...
How to modify containers without rebuilding their image
Sidecar container lifecycle changes in Kubernetes 1.18
With the Kubernetes Sidecar feature, the pod startup lifecycle will be changed, so sidecar containers will start after init containers finished, and normal containers will only be started once the sidecars become ready. It ensures that sidecars are up and running before the main processes start.
Delaying application start until sidecar is ready
Taking advantage of a peculiar Kubernetes implementation detail to block containers from starting before another container starts
Marko Lukša
Jun 17, 2020·3 min read
Some days ago, while I was writing another chapter of Kubernetes in Action, Second Edition, I noticed something unexpected in the way Kubernetes starts the containers in a pod. After inspecting the source code to confirm what I was seeing, I realized I had just found a solution to a long-standing problem in the Istio Service Mesh, which is what I’m currently working on at Red Hat.
I believe most Kubernetes users assume that after a pod’s init containers have finished, the pod’s regular containers are started in parallel. It turns out that’s not the case.
If you inspect the Kubelet code that starts the containers, you’ll notice that it does this sequentially. The code executes in a single thread and starts the containers in the order they are listed in the pod’s spec.containers array.
But who cares, right? Assuming that the container images are already stored locally, the time it takes for the Kubelet to start the second container after it starts the first one is negligible. Effectively, they both start at the same time.
This isn’t ideal when a container depends on another container and requires it to be fully started before it can run. One example of this is the Istio Proxy sidecar container. Because the application’s outgoing communication is routed through the proxy, the proxy must be up and running before the application itself is started.
You could add a shell script in the application container that waits for the proxy to be up, and then runs the application’s executable file. But this requires changing the application itself. Ideally, we want to inject the proxy into the Pod without any changes to the application or its container image.
It turns out that this can be done by taking advantage of the synchronous container start in Kubernetes.
First, we need to specify the proxy as the first container in spec.containers, but this is just part of the solution, as it only ensures that the proxy container is started first and doesn’t wait for it to become ready. The other containers are started immediately, leading to a race condition between the containers. We need to prevent the Kubelet from starting the other containers until the proxy is ready.
This is where the post-start lifecycle hook comes in. It turns out that the Kubelet code that starts the container blocks the start of the next container until the post-start handler terminates.
We can take advantage of this behavior. Not just in Istio, but in every pod where the sidecar container must start and become ready before the application container can start.
In a nut-shell, the solution to the sidecar startup problem is the following:
If the sidecar container provides an executable file that waits until the sidecar is ready, you can invoke it in the container’s post-start hook to block the start of the remaining containers in the pod.
The following figure should help you visualize what happens in the pod.
https://miro.medium.com/max/1400/1*doJhrU_cgrh8jq2jNrQNFA.png
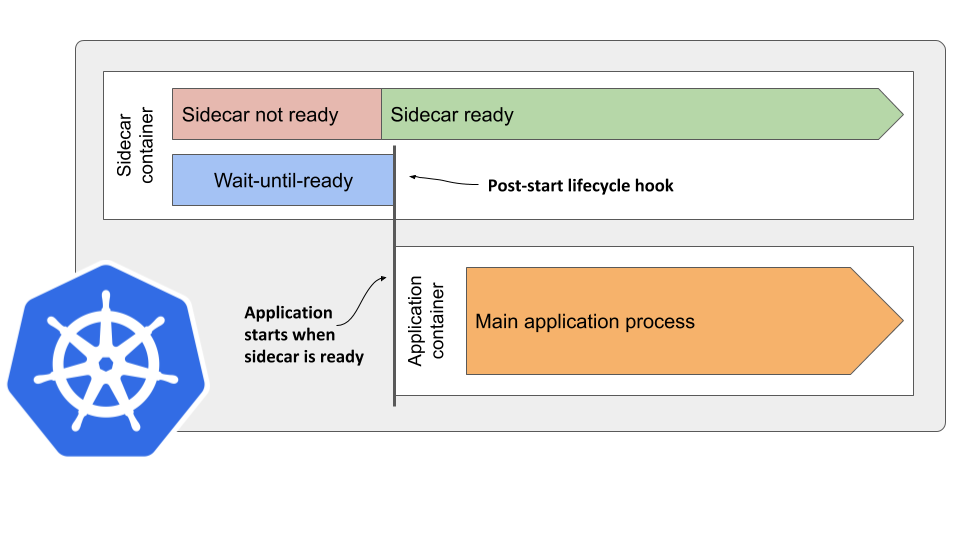
Here’s how the pod manifest might look like:
apiVersion: v1
kind: Pod
metadata:
name: sidecar-starts-first
spec:
containers:
- name: sidecar
image: my-sidecar
lifecycle:
postStart:
exec:
command:
- /bin/wait-until-ready.sh
- name: application
image: my-application
This approach is not perfect, though. If either the command invoked in the post-start hook or the container’s main process fail, the other containers will be started right away. Nevertheless, this should be a good workaround until Kubernetes introduces proper support for sidecar containers. Or until someone decides to change the Kubelet’s behavior and make it start containers in separate goroutines.
While this technique fixes the container start up order, it doesn’t help with the order in which the pod’s containers are stopped when you delete the pod. The pod’s containers are truly terminated in parallel. When it shuts down a pod, the Kubelet executes the container termination code in goroutines — one for each container. Unlike post-start hooks, the pre-stop hooks therefore run in parallel.
If you need the sidecar to stop only after the main application container has terminated, you must handle this in a different way.
I’ll explain how in my next blog post…

 浙公网安备 33010602011771号
浙公网安备 33010602011771号