Shared Virtual Memory (SVM) Functions
共享虚拟存储系统
深入GPU硬件架构及运行机制
What differences and relations between SVM, HSA, HMM and Unified Memory?
Could someone explain differences and relations between the SVM(Shared Virtual Memory, by Intel), HSA(Heterogeneous System Architecture, by AMD), HMM(Heterogeneous Memory Management, by Glisse from redhat) and UM(Unified Memory, by NVIDIA) ? Are these in the substitutional relation?
As I understand it, these aim to solve the same thing, sharing pointers between CPU and GPU(implement with ATS/PASID/PRI/IOMMU support). So far, SVM and HSA can only be used by integrated gpu. And, Intel declare that the root ports doesn’t not have the required TLP prefix support, resulting that SVM can’t be used by discrete devices. So could someone tell me the required TLP prefix means what specifically? With HMM, we can use allocator like malloc to manage host and device memory. Does this mean that there is no need to use SVM and HSA with HMM, or HMM is the basis of SVM and HAS to implement Fine-Grained system SVM defined in the opencl spec?
有人可以解释一下SVM(英特尔共享虚拟内存),HSA(异构系统架构,AMD),HMM(异构内存管理,Glisse)和UM(统一内存,NVIDIA)之间的区别和关系吗?这些是替代关系吗?
据我了解,它们旨在解决同一问题,在CPU和GPU之间共享指针(通过ATS / PASID / PRI / IOMMU支持实现)。到目前为止,SVM和HSA只能由集成GPU使用。而且,英特尔宣布根端口不具备必需的TLP前缀支持,从而导致分立设备无法使用SVM。那么有人可以告诉我所需的TLP前缀是什么意思吗?使用HMM,我们可以使用malloc之类的分配器来管理主机和设备内存。这是否意味着不需要将SVM和HSA与HMM一起使用,还是HMM是SVM和HAS的基础,以实现opencl规范中定义的精细系统SVM?
I can't provide an exhaustive answer, but I have done some work on SVM. Take it with a grain of salt though, I am not an expert.
* HSA is an architecture that provides a common programming model for CPUs and accelerators (GPGPUs etc). It does have SVM requirement (I/O page faults, PASID and compatible address spaces), though it's only a small part of it.
* Similarly, OpenCL provides an API for dealing with accelerators. OpenCL 2.0 introduced the concept of Fine-Grained System SVM, which allows to pass userspace pointers to devices. It is just one flavor of SVM, they also have coarse-grained and non-system. But they might have coined the name, and I believe that in the context of Linux IOMMU, when we talk about "SVM" it is OpenCL's fine-grained system SVM.
* Nvidia Cuda has a feature similar to fine-grained system SVM, called Unified Virtual Adressing. I'm not sure whether it maps exactly to OpenCL's system SVM. Nividia's Unified Memory seems to be more in line with HMM, because in addition to unifying the virtual address space, they also unify system and device memory.
So SVM is about userspace API, the ability to perform DMA on a process address space instead of using a separate DMA address space. One possible implementation, for PCIe endpoints, uses ATS+PRI+PASID.
* The PASID extension adds a prefix to the PCI TLP (characterized by bits[31:29] = 0b100) that specifies which address space is affected by the transaction. The IOMMU uses (RequesterID, PASID, Virt Addr) to derive a Phys Addr, where it previously only needed (RID, IOVA).
* The PRI extension allows to handle page faults from endpoints, which are bound to happen if they attempt to access process memory.
* PRI requires ATS. PRI adds two new TLPs, but ATS makes use of the AT field [11:10] in PCIe TLPs, which was previously reserved.
So PCI switches, endpoints, root complexes and IOMMUs all have to be aware of these three extensions in order to use SVM with discrete endpoints.
While SVM is only about virtual address space, HMM deals with physical storage. If I understand correctly, HMM allows to transparently use device RAM from userspace applications. So upon an I/O page fault, the mm subsystem will migrate data from system memory into device RAM. It would differ from "pure" SVM in that you would use different page directories on IOMMU and MMU sides, and synchronize them using MMU notifiers. But please don't take this at face value, I haven't had time to look into HMM yet.
我无法提供详尽的答案,但是我已经在SVM上做了一些工作。虽然我有些经验,但我不是专家。
* HSA是为CPU和加速器(GPGPU等)提供通用编程模型的体系结构。它确实具有SVM要求(I / O页面错误,PASID和兼容的地址空间),尽管它只是其中的一小部分。
*同样,OpenCL提供了用于处理加速器的API。 OpenCL 2.0引入了精细系统SVM的概念,该概念允许将用户空间指针传递给设备。这只是SVM的一种,它们还具有粗粒度且非系统的特性。但是他们可能是个名字,我相信在Linux IOMMU的背景下,当我们谈论“ SVM”时,它就是OpenCL的细粒度系统SVM。
* Nvidia Cuda具有类似于细粒度系统SVM的功能,称为统一虚拟地址。我不确定它是否完全映射到OpenCL的系统SVM。 Nividia的统一内存似乎更符合HMM,因为除了统一虚拟地址空间外,它们还统一系统和设备内存。
因此,SVM与用户空间API有关,即在进程地址空间上执行DMA而不是使用单独的DMA地址空间的能力。对于PCIe端点,一种可能的实现方式是使用ATS + PRI + PASID。
* PASID扩展名在PCI TLP上添加了一个前缀(由bit [31:29] = 0b100表征),该前缀指定事务影响哪个地址空间。 IOMMU使用(RequesterID,PASID,Virt Addr)派生一个Phys Addr,以前仅在此位置(RID,IOVA)。
* PRI扩展允许处理来自端点的页面错误,如果它们试图访问进程内存,这些错误肯定会发生。
* PRI需要ATS。 PRI添加了两个新的TLP,但是ATS利用了先前保留的PCIe TLP中的AT字段[11:10]。
因此,PCI交换机,端点,根联合体和IOMMU都必须了解这三个扩展,才能将SVM与离散端点一起使用。
虽然SVM仅与虚拟地址空间有关,但是HMM处理物理存储。如果我理解正确,则HMM允许透明地使用用户空间应用程序中的设备RAM。因此,在发生I / O页面故障时,mm子系统会将数据从系统内存迁移到设备RAM。它与“纯” SVM的不同之处在于,您将在IOMMU和MMU端使用不同的页面目录,并使用MMU通知程序对其进行同步。但是请不要一味看待这个,我还没有时间研究HMM。
So aim of all technology is to share address space between a device and CPU. Now they are 3 way to do it:
A) all in hardware like CAPI or CCIX where device memory is cache coherent from CPU access point of view and system memory is also accessible by device in cache coherent way with CPU. So it is cache coherency going both way from CPU to device memory and from device to system memory
B) partially in hardware ATS/PASID (which are the same technology behind both HSA and SVM). Here it is only single way solution where you have cache coherent access from device to system memory but not the other way around. Moreover you share the CPU page table with the device so you do not need to program the IOMMU. Here you can not use the device memory transparently. At least not without software help like HMM.
C) all in software. Here device can access system memory with cache coherency but it does not share the same CPU page table. Each device have their own page table and thus you need to synchronize them.
HMM provides helper that address all of the 3 solutions.
A) for all hardware solution HMM provides new helpers to help with migration of process memory to device memory
B) for partial hardware solution you can mix with HMM to again provide helpers for migration to device memory. This assume you device can mix and match local device page table with ATS/PASID region
C) full software solution using all the feature of HMM where it is all done in software and HMM is just doing the heavy lifting on behalf of device driver
In all of the above we are talking fine-grained system SVM as in the OpenCL specificiation. So you can malloc() memory and use it directly from the GPU.
因此,所有技术的目的都是在设备和CPU之间共享地址空间。现在,他们是三种实现方法:
A)所有在CAPI或CCIX之类的硬件中,从CPU访问的角度来看,设备内存是缓存连贯的,并且设备也可以通过缓存与CPU连贯的方式来访问系统内存。因此,缓存一致性是从CPU到设备内存以及从设备到系统内存的两种方式
B)部分包含在硬件ATS / PASID中(这是HSA和SVM背后的相同技术)。在这里,这是唯一的单向解决方案,您可以缓存从设备到系统内存的一致性访问,而没有相反的方法。此外,您与设备共享CPU页表,因此无需对IOMMU进行编程。在这里,您不能透明地使用设备存储器。至少并非没有像HMM这样的软件帮助。
C)全部在软件中。在这里,设备可以访问具有缓存一致性的系统内存,但是它不共享同一CPU页表。每个设备都有自己的页表,因此您需要对其进行同步。
HMM提供了可解决所有3个解决方案的助手。
A)对于所有硬件解决方案HMM提供了新的帮助程序,以帮助将过程内存迁移到设备内存
B)对于部分硬件解决方案,您可以将其与HMM混合使用,以再次提供用于迁移到设备内存的帮助器。假设您的设备可以将本地设备页面表与ATS / PASID区域混合并匹配
C)完整的软件解决方案,使用了HMM的所有功能,其中所有功能都是通过软件完成的,而HMM只是代表设备驱动程序进行了繁重的工作
在以上所有内容中,我们都在谈论像OpenCL规范中的细粒度系统SVM。因此,您可以malloc()内存并直接从GPU使用它。
希望这可以澄清事情。
Description
Shared Virtual Memory (SVM) (Glossary): An address space exposed to both the host and the devices within a context. SVM causes addresses to be meaningful between the host and all of the devices within a context and therefore supports the use of pointer based data structures in OpenCL kernels. It logically extends a portion of the global memory into the host address space therefore giving work-items access to the host address space.
There are three types of SVM in OpenCL.
Coarse-Grained buffer SVM: Sharing occurs at the granularity of regions of OpenCL buffer memory objects.
Fine-Grained buffer SVM: Sharing occurs at the granularity of individual loads/stores into bytes within OpenCL buffer memory objects.
Fine-Grained system SVM: Sharing occurs at the granularity of individual loads/stores into bytes occurring anywhere within the host memory.
共享虚拟内存(SVM)(词汇表):在上下文中向主机和设备公开的地址空间。SVM 使主机和上下文中的所有设备之间的地址有意义,因此支持在 OpenCL 内核中使用基于指针的数据结构。 它在逻辑上将全局内存的一部分扩展到主机地址空间,因此使工作项能够访问主机地址空间。
OpenCL 中有三种类型的 SVM:
粗粒度缓冲区 SVM: 共享 OpenCL 缓冲区对象的区域粒度。
细粒度缓冲区 SVM:共享在OpenCL 缓冲区内存对象中的单个字节加载/存储。
细粒度系统 SVM:共享在主机内存中任意位置的单个字节加载/存储。
前两种模式需要使用OpenCL clSVMAlloc函数显式分配SVM缓冲区,并且当将该缓冲区的指针传递给内核时,必须将其显式声明为SVM指针。相反,细粒度的系统SVM提供了最高级别的抽象,因为设备上的每个内核都可以访问任何指针:使用clSVMAlloc和 由常规malloc / new函数返回的那些。
OpenCL™ 2.0 Shared Virtual Memory Overview
One of the remarkable features of OpenCL™ 2.0 is shared virtual memory (SVM). This feature enables OpenCL developers to write code with extensive use of pointer-linked data structures like linked lists or trees that are shared between the host and a device side of an OpenCL application. In OpenCL 1.2, the specification doesn't provide any guarantees that a pointer assigned on the host side can be used to access data in the kernel on the device side or vice versa. Thus, data with pointers in OpenCL 1.2 cannot be shared between the sides, and the application should be designed accordingly, for example, with indices used instead of pointers. This is an artifact of a separation of address spaces of the host and the device that is addressed by OpenCL 2.0 SVM.
OpenCL 2.0 的显著功能之一™共享虚拟内存 (SVM)。此功能使 OpenCL 开发人员能够编写代码,广泛使用指针链接的数据结构,如在 OpenCL 应用程序的主机和设备端之间共享的链接列表或树。在 OpenCL 1.2 中,规范不提供任何保证,保证在主机端分配的指针可用于访问设备端内核中的数据,反之亦然。因此,在 OpenCL 1.2 中具有指针的数据不能在两者之间共享,并且应用程序应相应地进行设计,例如,使用索引而不是指针。这是由OpenCL 2.0 SVM寻址的主机和设备地址空间分离的产物。
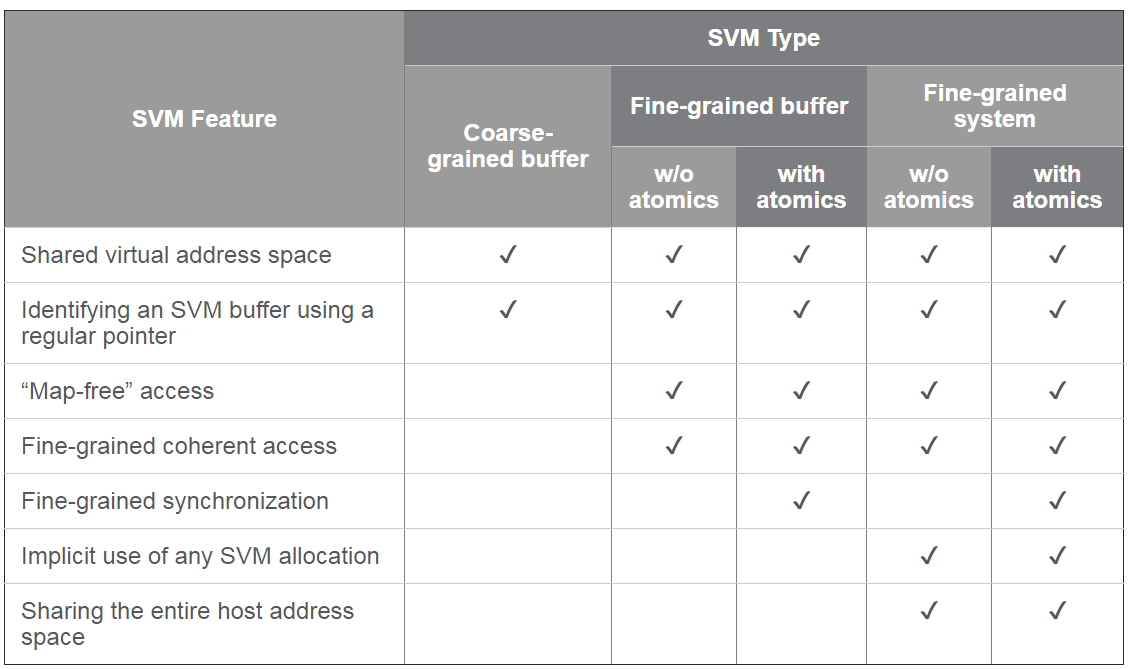
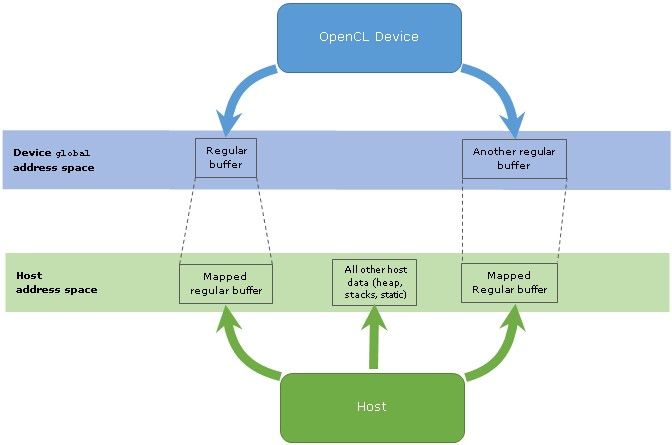
Figure 1: OpenCL 1.2和常规缓冲区中的地址空间及其映射内容的示意图
OPenCL 2.0 Shared Virtual Address Space
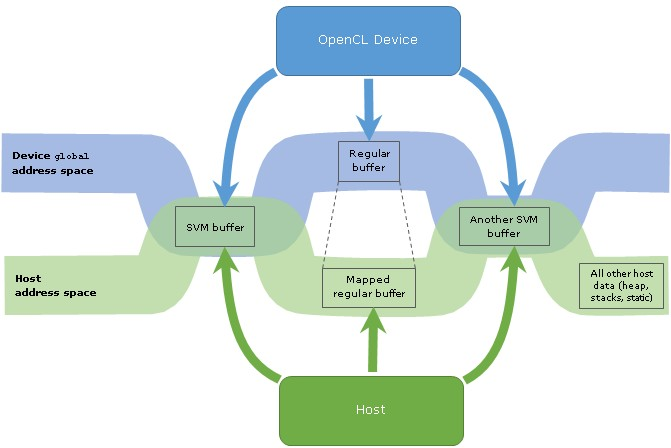
OpenCL 2.0中地址空间的示意图及其在分配SVM缓冲区的区域中的重叠。 显示了常规缓冲区及其映射的内容以进行比较。
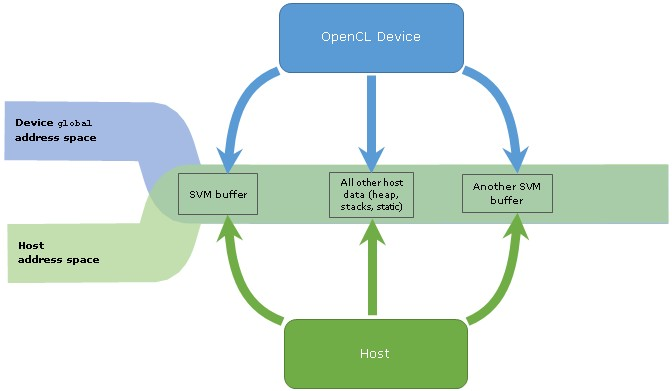
结论和要点
借助OpenCL 2.0,对共享虚拟内存(SVM)的支持为编程模型引入了最重要的改进之一。以前,主机和OpenCL设备的内存空间是不同的,这增加了OpenCL主机逻辑的复杂性。现在,SVM弥合了差距,因此主机和OpenCL设备都可以使用单个指针访问内存。
SVM最重要的是一种生产力功能,它使将现有C / C ++代码移植到OpenCL更加简单,尤其是对于指针链接的数据结构。但是SVM不仅要消除多余的主机OpenCL代码,它还可以通过使用原子对SVM内存的细粒度一致访问来实现主机和OpenCL设备之间更紧密的同步。
根据OpenCL平台的硬件功能,有不同级别的SVM支持。对于开发人员而言,了解SVM类型之间的差异并相应地设计主机逻辑非常重要。
SVM支持的级别更高-从粗粒度的缓冲区SVM迁移到细粒度的系统SVM-它提供的主机逻辑组织的生产方式更加有效。同时,使用高级级别的SVM支持会降低主机OpenCL代码的可移植性,因为并非所有OpenCL 2.0平台都提供所有SVM功能。因此,为OpenCL应用程序选择目标SVM类型是生产力和可移植性之间的权衡。
The Compute Architecture of Intel® Processor Graphics Gen9
Intel® Processor Graphics
Architecture Overview for Intel® Processor Graphics Gen11
Optimizing Matrix Multiply for Intel® Processor Graphics Architecture Gen9
Shared Virtual Memory
Pass a Pointer: Exploring Shared Virtual Memory Abstractions in OpenCL Tools for FPGAs
Developer and Optimization Guide for Intel® Processor Graphics Gen11 API
all Compute+Architecture+of+Intel+Processor+Graphics
相关论文,lect10.pdf FelixFPT17.pdf
The-Compute-Architecture-of-Intel-Processor-Graphics-Gen9-v1d0.pdf
The-Architecture-of-Intel-Processor-Graphics-Gen11_R1new.pdf
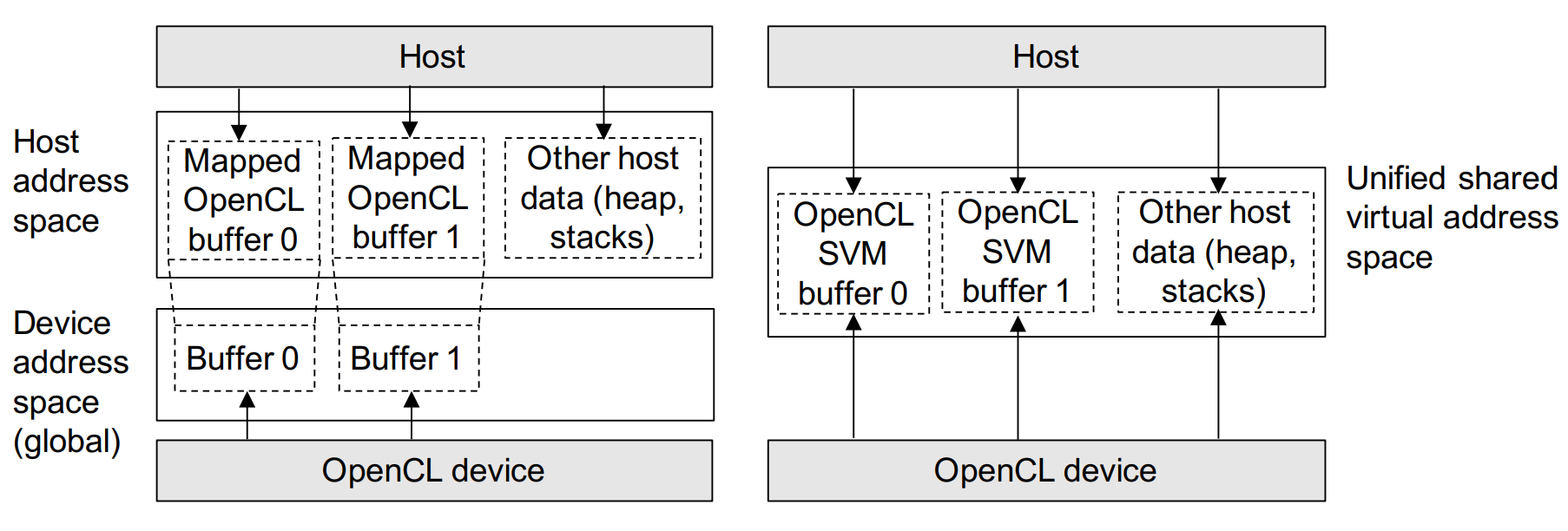
OpenCL 1.x中的主机设备通信(左);通过OpenCL 2.0细粒度系统SVM进行通信(右)
自定义SVM基础结构
OpenCL细粒度系统SVM需要三个基准功能。首先,主机指针带有操作系统通过系统调用malloc和new分配的虚拟地址。但是,通过内核总线接口在寄存器传输级别(RTL)进行的内存访问使用物理地址。因此,需要从虚拟地址到物理地址的转换,以使主机指针在设备地址空间中有意义。
其次,虚拟到物理地址转换必须嵌入到内存管理单元中,该内存管理单元处理内核对SVM的访问并执行实际的数据传输。
第三,通过原子加载/存储操作进行并发内存访问的细粒度主机设备同步需要一种机制,以确保防止主机或内核对共享数据的访问受到另一方的干扰,直到另一方访问同一位置为止。访问已完成(访问的原子性)。
我们的OpenCL SVM框架的目标平台是一个Intel Cyclone V SoC,它由可编程逻辑和运行Linux和Intel FPGA OpenCL运行时环境(版本16.0)的双核32位ARM处理器组成。
虽然我们的框架将来可以移植到不同的体系结构,但是下面描述的一些基础结构细节是特定于Cyclone V体系结构的。
具体来说,这适用于虚拟到物理地址转换(由于ARM特定的虚拟内存系统架构)和将ARM内核与FPGA连接的物理总线接口(SoC片上总线架构)。
虚实地址转换
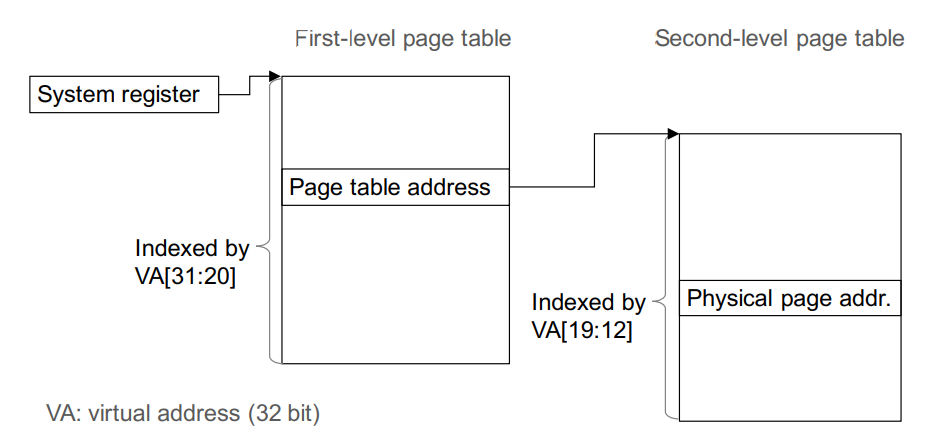
使用ARM系统架构中的页表进行地址转换
传递给内核的主机指针包含操作系统分配的虚拟内存地址。当ARM内核执行内存访问时,它会通过在Linux页表中进行查找,从虚拟地址中获取物理内存地址。页表驻留在系统内存中,并存储活动内存页的物理地址。 ARM体系结构使用两级转换表层次结构,如图3所示。第一级转换表的基地址存储在CPU系统寄存器(TTBR0)[16]中,可以在Linux内核中读取该寄存器。模式。
通过指针值的高12位(32位虚拟地址)对第一级表进行索引,然后通过查找来获取相应第二级页表的基址。后者由虚拟地址位的第二部分索引。然后第二次查找将得出4 KB页面的物理地址。
请求数据的物理内存地址由页面地址和虚拟地址的低12位组成。在我们的框架中,FPGA内核与CPU处于同等地位,并且应具有独立于主机程序启动对CPU系统内存本身的访问的能力。因此,内核必须拥有以FPGA逻辑实现的自己的虚拟地址到物理地址的转换。
转换过程先于内核进行的每个SVM访问。转换单元通过主总线桥直接访问系统内存中的Linux页表,该总线桥通过ACP连接ARM内核和可编程逻辑。为了通知内核第一级页表的基地址,在主机程序中的OpenCL初始化代码期间(使用我们框架提供的驱动程序模块)读取TTBR0系统寄存器的值并进行传递作为默认参数添加到内核。利用该基地址,翻译单元执行两次系统存储器读取,以遍历第一和第二级页表并获得请求字的物理地址。在极少数的页面错误事件中,即不存在有效物理页面的虚拟地址,在地址转换过程中会检测到这些虚拟地址并触发CPU中断(使用Cyclone V中的备用FPGA至主机中断请求端口)。软件中断例程获取丢失的页面,然后重复内核的地址转换。默认情况下,页表遍历以32位字的粒度执行。地址转换单元的实现是以下部分的一部分。
自定义SVM基础结构
OpenCL细粒度系统SVM需要三个基准功能。
首先,主机指针带有操作系统通过系统调用malloc和new分配的虚拟地址。但是,通过内核总线接口在寄存器传输级别(RTL)进行的内存访问使用物理地址。因此,需要从虚拟地址到物理地址的转换,以使主机指针在设备地址空间中有意义。
其次,虚拟到物理地址转换必须嵌入到内存管理单元中,该内存管理单元处理内核对SVM的访问并执行实际的数据传输。
第三,通过原子加载/存储操作进行并发内存访问的细粒度主机设备同步需要一种机制,以确保防止主机或内核对共享数据的访问受到另一方的干扰,直到另一方访问同一位置为止。访问已完成(访问的原子性)。
我们的OpenCL SVM框架的目标平台是一个Intel Cyclone V SoC,它由可编程逻辑和运行Linux和Intel FPGA OpenCL运行时环境(版本16.0)的双核32位ARM处理器组成。虽然我们的框架将来可以移植到不同的体系结构,但是下面描述的一些基础结构细节是特定于Cyclone V体系结构的。
具体来说,这适用于虚拟到物理地址转换(由于ARM特定的虚拟内存系统架构)和将ARM内核与FPGA连接的物理总线接口(SoC片上总线架构)。
内存管理单元
内存管理单元(MMU)集成了虚拟地址到物理地址的转换以及加载/存储功能,以执行实际的数据访问。该单元是一个RTL模块,已添加到FPGA内核逻辑中。

地址转换由两次系统内存读取组成,而实际的数据访问是对系统内存的读取或写入访问。图4示出了基本存储器管理单元的实现。它与其余内核逻辑的接口是类似FIFO的Avalon流输入和输出接口,其信号指示新数据(valid_in和valid_out)和反压(stall_out和stall_in)以及数据输入和输出的可用性。该单元由一个加载/存储单元(LSU)组成,该单元处理对系统总线的内存访问请求。 LSU连接到FPGA到处理器的片上总线桥(存储器映射的Avalon-MM接口)
为了使高速缓存通过ACP对CPU系统存储器进行一致的访问,请在Cyclone V SoC上进行访问。 LSU包含一个FIFO缓冲区,该缓冲区缓冲输出数据,直到下游节点可以拾取它为止。有限状态机(FSM)控制LSU并管理停顿和有效信号,以与内核逻辑的其余部分进行交互。在内存管理单元的基本版本中,用于地址转换和实际数据访问的两个页表查找在单个LSU上进行时间复用。
我们探索内存管理单元的几种设计选择。图5显示了图4中单元的流水线版本。它不是对三个总线访问进行时分多路复用,而是在空间上展开所需的LSU和FSM,以便内核模块在完成第一个流水线阶段后立即接受新请求。并实时处理多个SVM请求。对FPGA到处理器总线桥的并发访问的仲裁被分流到Avalon总线互连。虽然这两个版本在FPGA区域之间交换了吞吐量,但我们可以配置LSU使其包含进一步影响这一折衷的功能。首先,可以更改LSU处理一系列请求的方式:
◦基本:LSU一次处理一个请求。 它使上游节点停止运行,直到完成内存请求为止。
◦静态突发合并:如果已知n个请求序列中的地址严格连续,则将这些地址编译为长度为n的突发访问(假设n小于最大突发长度),通常比独立的顺序访问更有效。 LSU将停止上游节点,直到突发访问已完成。
◦动态突发合并:如果不知道n个请求序列中的地址总是严格连续的,但是在大多数情况下都是连续的,则动态突发合并会很有效。 只要到达的请求具有相对于先前请求的连续地址,LSU就会在将请求以突发形式发送给总线之前保持收集请求,并旨在编译可能的最大突发。
其次,各个LSU可以配置为包括直接映射的片上高速缓存。 在LSU用于“虚拟到物理转换”(图5中的LSU 0和LSU 1)的情况下,高速缓存对应于转换后备缓冲区(TLB), 存储页表查找的最新历史记录。
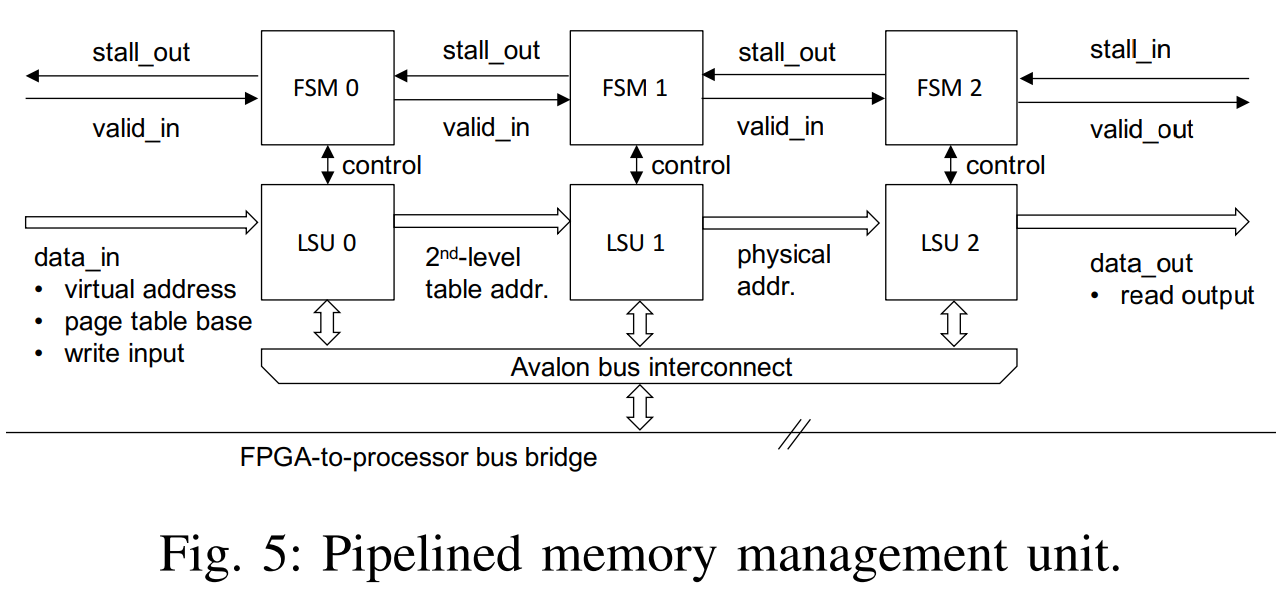

FPGA内核通常包含与OpenCL代码中的SVM加载/存储指令一样多的存储器管理单元。 所有单元都通过Avalon总线互连连接到FPGA至处理器的总线桥。 以下部分描述了SVM基础结构的扩展,以启用细粒度的主机设备同步。
系统内存原子访问
除了支持共享地址空间外,我们的内存管理单元还可以配置为包括主机设备的同步机制,以实现原子加载/存储操作。 该机制是通过使用锁定服务(在提供给程序员的原子内存指令的高级视图下)实现的。 为此,内存管理单元具有一个附加的Avalon总线接口,以请求锁的所有权。 图6(左)显示了锁定服务的体系结构。 锁服务器从其核心服务于从主机程序以及FPGA内核中的一个或几个MMU两者获取和释放锁的请求。 后者通过Avalon总线互连连接到服务器。 来自主机端的锁定请求命令是通过Cyclone V架构中的另一个CPU-FPGA总线桥接收的:
轻量级的处理器到FPGA的桥接器,专为低吞吐量,小批量传输而设计。
图6(右)显示了锁服务器内部的状态机。 命令host_acquire,host_release,dev_acquire_x和dev_release_x缓存在请求队列中,分别指示主机和设备希望获取或释放锁的愿望。 锁定服务器确认已成功完成对客户端的请求。 在发出实际的内存操作之前,内存管理单元将暂停直到收到此请求。 在主机方面,原子内存操作在等待确认的同时轮询内存映射的处理器到FPGA总线桥接器。
轻量级的处理器到FPGA接口也用于交换数据以进行页面错误处理
Comparison with OpenCL 1.x
除了内存访问单元,流水线内核实现在所有设计中都是相同的。内核时间的主要区别仅源于不同的内存访问时间。图9显示了四种设计的系统执行时间细分。由于Cyclone V [13]上CPU和FPGA之间不存在直接存储器访问(DMA)功能,因此设计1在将树形缓冲区复制到设备存储器上花费了大量时间(> 8 s)。设计2完全避免了加载时间。其他没有共享物理内存但具有DMA支持的平台将在设计2处使用OpenCL命令clEnqueueMapBuffer而不是常规的new / malloc命令在主机端分配“树数组”,这将导致主机对树的访问速度变慢在植树期间。两个非SVM内核都直接访问DDR内存,因此内核执行速度很快。相比之下,这两种SVM设计由于对树数据的访问速度较慢而具有更长的内核执行时间,但它们也避免了整个树的初始副本。
对于设计3,必须保证存储在树节点上的14个32位字位于物理上连续的内存位置。这使树节点的内存分配变得复杂,从而给主机和设备的内存访问带来了时间损失。
Design 4动态地聚合突发,并不严格要求此保证。该设计可以使用常规的new / malloc命令来构建树,并且在所有SVM设计中都具有最佳性能。我们在Design 4中使用流水线式动态突发合并MMU的SVM实现比标准OpenCL 1.x实现的性能高2倍,并且执行时间与共享物理内存的OpenCL 1.x实现的性能接近。
工具整合
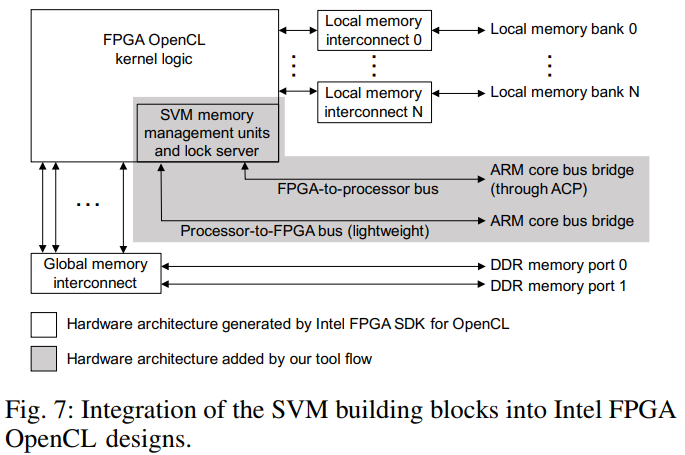
我们的SVM框架是作为用于OpenCL的英特尔FPGA SDK的附加组件实现的。上面描述的SVM构建块已添加到工具流程中,并由用户在OpenCL主机和内核代码中调用。在主机端,提供了一个应用程序编程接口(API),使程序员可以使用我们的SVM功能并与之交互。我们的框架还为内核提供了API。程序员通过内核代码中的函数调用实例化SVM加载/存储指令。除了常规内核逻辑之外,这些调用还触发了FPGA逻辑中自定义RTL模块的实例化。图7显示了OpenCL SDK生成的硬件设计。图7中带有灰色阴影的部分(即内存管理单元,锁定服务器,附加的Avalon总线配置和ACP配置)自动添加到OpenCL的构建流程中。为此,在系统设计生成后停止OpenCL流程,并通过自动的源到源转换来修改生成的RTL,以包括自定义SVM功能。下一节评估了我们的SVM基础架构的性能,并提出了一个设计空间探索,涵盖了IV-B节中描述的内存管理单元的不同实现选项。
结论
OpenCL SVM通过赋予FPGA内核无缝地取消对在主机软件中创建的指针的引用的能力以及在主机和设备之间并行共享数据结构的情况下提供确保数据一致性的机制,极大地简化了异构CPU-FPGA系统的编程。我们提供了一个开放源代码的框架,该框架会自动将SVM功能添加到使用面向Cyclone V SoC的针对OpenCL的英特尔FPGA SDK开发的实现中。使用此框架,我们将为底层的SVM构建块提供设计空间探索。通过实际的基准测试应用程序,我们可以证明,与基于OpenCL 1.x的等效实现方式相比,这种设计空间探索的最快变体可以将端到端系统的执行时间减少1.5倍至2.3倍。
如果访问的主机数据部分与最坏情况相比较小,则我们的SVM实现将使用共享的物理内存来估计特殊情况的执行时间。我们得出的结论是,除了易于编程之外,在OpenCL SVM的支持下,避免了人为地调整动态共享数据结构和仅在需要时才获取数据的要求,这可能会导致性能提升。未来的工作将包括探索更大的基准集,我们希望对基准的SVM构建基块实现展现不同的权衡。我们还计划部署静态程序分析,以实现这些实现的特定于应用程序的优化。
REF:
刘肄同学的patch
Qemu: Extend intel_iommu emulator to support Shared Virtual Memory
vfio: support Shared Virtual Addressing
PCI-SIG (PASID)
Process Address Space ID (PASID)
内核patchs: Shared Virtual Addressing for the IOMMU
AMD IOMMU PPT
AMD I/O Virtualization Technology (IOMMU) Specification
DMA Remapping的简介 VT-d DMA Remapping
ARM SMMU学习笔记 (CSDN)描述了二次地址转换
来自微软的doc GpuMmu 模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号