
Python入门:Python基础笔记
(C语言:)C语言是相对C++、C#、Java等语言更接近底层,并且一些硬件编程都可以使(只能使用)C语言。另外C语言学起来相对困难,因为涉及到指针,指针也是语言接近底层语言的一个特征。目前编写较大的项目、软件等,一般不会使用C语言,使用一些高级语言会提高开发效率,缩短开发周期。这也就导致一个问题,使用C语言像写出一个像样点的应用是不容易的(不仅限于功能),即使C语言再精通,只是对计算机的底层了解更深,写出真正的软件还需要其他各种支持。
(Python:)就自己的理解,Python入门还是很容易的。Python语言简洁,相比C语言学起来更加有趣,Python的简洁是建立在强大的lib支持。新手学习语言一般会急于自己写一个像样点的App(例如小游戏、小型管理系统等),用Python实现要比C语言简洁的多,甚至C语言高手要写出个可玩的游戏也是很困难的。另外Python流行起来是由于当前的数据分析、收据挖掘。这可能是Python的强项。
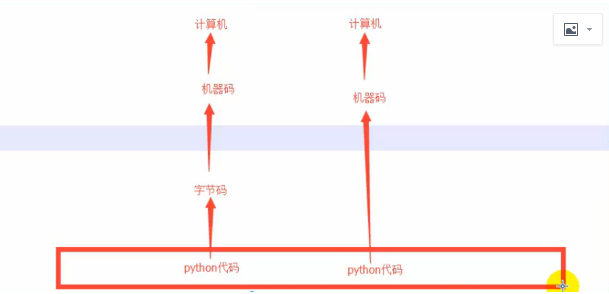
C语言执行效率高,Python语言开发效率高(不需要管理内存,虚拟机提供开放内存,释放内存)

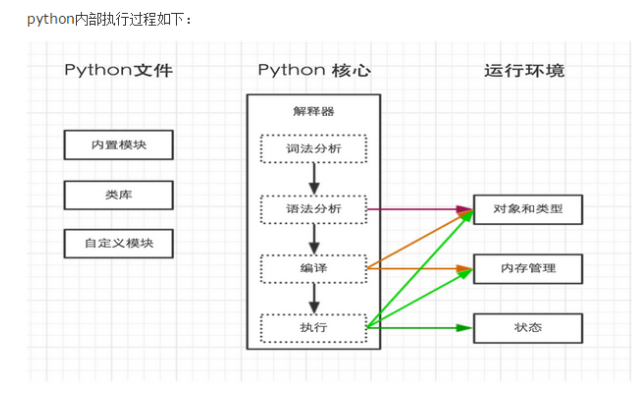
cpython和pypy的内部执行过程(左:cpython 右:pypy)
解释器:#!/usr/bin/python(这一行用来指定python的解释器在哪),Liunx下,执行前需给予 hello.py文件执行权限,命令:chmod 755 hello.py (ps:windows下无效)
编码:
ascii 8位:可以表示出所有的英文,数字,字符。01001010 可以组合成 2**8=256种可能,这就是 ascii码(译音:阿斯克) ,原来编码的叫阿斯克码,不能识别所有的字符(比如汉字等等)!
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
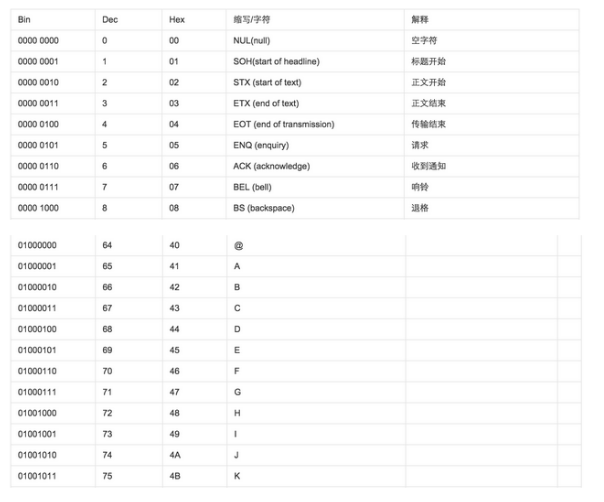
unicode (统一码、万国码、单一码)最少用2个字节:(1byte字节=8bit位=01010101,所以最少就是要使用16位0101010101010101,一个汉字等于3个字节,吴永聪=9字节 1个字节等于8位,这个名字就等于24位)万国码 unicode(译音:油泥扣得)后来出现的叫万国码,能识别世界上所有字符!用ascii码 表示A的话,A=65 ‘0b1000001’b代表用2进制表示,一共8位!但是万国码最少用2个字节,也就是16位,前面没有,就要补8个零,‘000000000b1000001’就白白浪费了内存空间,所以万国码不可取!(缺点:它最少要使用2个字节,也就是16位来表示)
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8编码:它就是unicode加工而来:对于所有英文,数字,字符都是用8位表示,对于欧洲的文字用16位,中文用24位。.... 其实就是对unicode里面的所有包含的字符进行的划分。适合用8位的就用8位,适合16位的就用16位表示,大大节省了unicode所占的内存空间!
GBK GB2312编码类似于UTF-8
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以刚才用python运行 print ‘你好,世界’ 的时候下图中的报错,Non(译音:那俺)-ASCII charater(译音:卡瑞克测)意思就是 没有ascii码对应的字符!因为ascii码不能识别汉字!
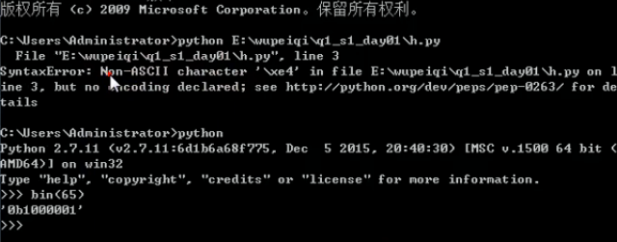
代码顶部解释器加上 # -*- coding(译音:寇丁): utf-8 -*- 这段代码告诉Python用UTF-8编码来识别!(Python2.X默认使用的ascii码!Pyrhon3.X默认使用的utf-8编码,所以不用在解释器加以上代码)
养成写代码之前必须加上以下两行:
#! usr/bin/env/python #解释器
# -*- coding: utf-8 -*- #编码
#! usr/bin/env python 和 #! usr/bin/python 的区别:
在unix类的操作系统才有意义。 #!/usr/bin/python是告诉操作系统执行这个脚本的时候,调用/usr/bin下的python解释器; #!/usr/bin/env python这种用法是为了防止操作系统用户没有将python装在默认的/usr/bin路径里。当系统看到这一行的时候,首先会到env设置里查找python的安装路径,再调用对应路径下的解释器程序完成操作。
这跟linux系统里安装python的目录有关 #!/usr/bin/python相当于写死了python路径; #!/usr/bin/env python会去环境设置寻找python目录,所以推荐这种写法。
四、注释
当行注视:# 被注释内容
多行注释:""" 被注释内容 """
一个项目是由多个.py文件组成的,.py的种类
1.python为用户提供的 #类库,D:/python/lib (导入就行)
2.自己写一个.py
3.网上下载别人的.py文件
import(译音:哎木跑特) 另一个.py文件名 #导入另一个.py
生成的.pyc文件是缓存文件
交互:

import getpass(译音:哎母泡特 盖特怕思)#Python3.0系列将raw_input作为垃圾扔掉了。。。 改用input
i1 = raw_input(译音:ruai_因普特) ("请输入用户名")
#i2 = raw_input ("请输入密码")
i2 = getpass.getpass("请输入密码")#将用户输入的内容不可见,
print(i1)
print(i2)
流程梳理:
1.创建XXX.py文件
PS:不要有中文路径,文件名也不要中文
2.写代码
PS:头部加上特殊的两行,写功能代码
3.执行代码
PS:打开终端,功能键+R+cmd,输入python+空格+代码文件的路径


 浙公网安备 33010602011771号
浙公网安备 33010602011771号