Dapr 长程测试和混沌测试
介绍
这是Dapr的特色项目,具体参见: https://github.com/dapr/test-infra/issues/11 ,在全天候运行的应用程序中保持Dapr可靠性至关重要。在部署真正的应用程序之前,可以通过在受控的混沌环境中构建,部署和操作此类应用程序来实现这种信心。
测试应用程序
所测试应用程序将模拟在社交网络中发布的消息,以便通过情绪分析进行评分。不采用外部依赖来更好地控制环境。可以删除某些组件,并实现相同的结果。另一方面,这个测试设计是有意地执行Dapr的所有构建块。
此应用程序中的所有组件使用相同的存储库和相同的编程语言实现,以便快速开发。由于此应用程序也使用 Actor 功能,因此可以用 .Net 或 Java 编写。鉴于当前的项目维护者更熟悉 C#,因此使用带有 C# 的 .Net SDK来实现这个项目。
存储库应与现有存储库分开。建议创建一个名为“长程测试”的新存储库。
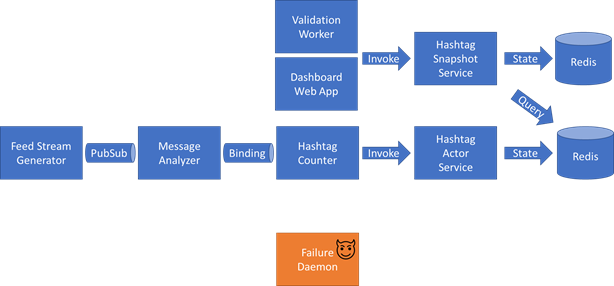
Feed 流发生器
生成人工社交网络消息帖子,例如:“Dapr很棒。#DaprRocks #Kubernetes“。将在预定义的模板中自动生成这些消息“ is . <Hashtag 1> <Hashtag 2>” 名词和形容词的列表是预定义的,并且是随机选择的。与主题标签列表相同。
该消息使用 UUID 生成器获取随机生成的消息 Id 和相关 Id,并使用 Dapr 的 PubSub API 以下列格式发布:
{
"correlationId": "<UUID>",
"messageId": "<UUID>",
"message": "<message>",
"creationDate": "<creationDate>"
}消息分析器
该组件通过Dapr 的PubSub功能订阅主题,查找形容词与情绪类型(正面,中性,负面)的映射,并使用识别的类型(或未知,如果找不到)并将该内容附加到消息中。最后,通过 Dapr 的输出绑定API 发布新的标记有效负载。
标记的有效负载采用以下格式:
{
"correlationId": "<UUID>",
"messageId": "<UUID>",
"message": "<message>",
"sentiment": "<sentiment type>",
"creationDate": "<creationDate>"
}Hashtag 计数器
此组件将通过 Dapr 的输入绑定调用接收消息。从邮件中提取主题标签。对于每个hashtag标识的# 标签,它都会进行一个Actor方法调用:标识为“HashtagActor”的执行组件实例中的方法increment(sentiment)。
Hashtag Actor 服务
此组件对于在 Dapr 中练习“Actor ”功能非常有用。它注册主题HashtagActor 程序类型,其中hashtag是标识符。这个Actor 有一个方法increment(String sentiment), 其目标是保持每个主题标签 - 情绪组合的计数器。在状态键中传递的情绪和状态值是前一个值(如果未找到,则为零),增量为 1。
Hashtag 快照服务
此组件将执行 Dapr 的状态 API(而不是在Actor 的上下文中)。它每分钟唤醒一次,并从 Redis 状态存储中检索所有Key - 不使用 Dapr 的状态 API,因为 Dapr 不提供 API 来从另一个 Dapr 应用程序的状态存储中查询一系列状态。预计只有几十个Key,因为此组件中预定义了主题标签列表。
现在,为所有状态生成键值对,并通过 Dapr 的状态存储 API 保存。此服务还提供了一个 API,用于通过 GET 方法检索所有密钥。
验证Worker
此组件将对应用程序的结果执行运行状况检查。鉴于最终的一致性和人为注入的故障,验证必须是模糊的。Worker应执行以下验证:
- 每5分钟唤醒一次。
- 通过在Hashtag 快照服务上调用 API 来获取所有键值对。
- Sleep 2分钟。
- 通过在Hashtag 快照服务上调用 API 来获取所有键值对。
- 计算已更改的计数器数的比率。
- 以 JSON 格式向标准输出指标:
{ "longhaul-counters-changeratio": "<ratio>"}
仪表板网络应用
这是一个简单的网页,它将调用Hashtag 快照服务进行 API ,显示所有键值对。这对于手动验证非常有用。(可选)此组件还可以通过 Dapr 的中间件验证 OAuth 功能。
失败守护进程
最后但并非最不重要的一点是,在给定固定配置的情况下,此服务将触发故障。本文档稍后将介绍故障类型和特定的故障配置。
平台、日志和指标
长程测试应用将使用 AKS 群集进行部署,该群集在 3 个可用区中的每个节点上至少有 1 个节点。由于目标是测试复原能力而不是性能,并且流量是人为生成的,因此便宜的硬件类型应该足够了,例如标准DS2 v2(2个vcpus,7 GiB内存)。
日志和指标将转发到 Azure 监视器,并且可以通过 JSON 作为结构化数据进行查询。
故障类型
为了模拟混乱的环境,将注入一些人为的故障。可以通过将服务从 3 缩小到 0,然后从 0 扩展到 3 来实现重新启动。当需要单个 POD(例如,placement服务)时,重新缩放应改为从1/到 1。
应用容器崩溃
若要模拟的应用崩溃(进程退出),任何容器都将在一段时间内重新启动此系统。值得注意的是,Dapr的Sidecar 预计将继续运行。预计容器将正常重新启动,Dapr的Sidecar将在没有手动干预的情况下恢复与应用程序的通信。
Pod 崩溃
要模拟给定 POD 不正常的情况,系统中的服务 POD 将在一段时间内重新启动。这是部分故障,这意味着在 Kubernetes 恢复新 POD 时,服务应继续运行。预计 Kubernetes 会将服务再次恢复到正常状态,而来自其他服务的 Dapr sidecar 将能够与恢复的服务中的所有 POD 进行通信。
服务崩溃
此故障通过重新启动服务的所有 POD 来模拟服务的完全中断。这将导致验证工作程序可能会识别完全中断。预计 Kubernetes 会将服务再次恢复到正常状态,而来自其他服务的 Dapr sidecar 将能够与恢复的服务中的所有 POD 进行通信。
状态存储中断
状态存储可能由于任何原因而关闭。为了模拟这一点,Redis 的所有 POD 都将每隔一段时间重新启动一次。
状态存储速度缓慢
状态存储的性能可能会因邻居应用的繁忙或其他外部因素而降低。这是通过在内部以 X tps 对 Redis 执行 Y 秒的写入操作来模拟的。预计数据处理会有些缓慢,但在突发结束后恢复。
主题中断
主题可能因任何原因而关闭。这将通过每隔一段时间重新启动 Kafka 的所有 POD 来模拟。
主题缓慢
由于并置了另一个主题并接收到流量峰值,因此主题的吞吐量可能会降低。缓慢也可能是由其他外部因素引起的。为了模拟这一点,创建了一个随机主题ios,副本设置为3(保证所有节点都有数据的副本),并且流量以X tps保持,持续时间为Y秒,间隔一次。预计数据处理会有些缓慢,但在突发结束后恢复。
Dapr 的sidecar 注入器奔溃
使用以下步骤模拟此故障后,数据处理应继续,并且所有 POD 都应具有 Dapr sidecar。
- 将服务从 3 扩展到 0。
- 等待服务为 0。
- 重新启动达普尔的边车喷油器。
- 将服务从 0 扩展到 3。
Dapr的placement服务崩溃
这是通过每隔一段时间重新启动placement服务来模拟的。
Dapr的Sentry服务崩溃
这是通过每隔一段时间重新启动sentry服务来模拟的。
Actor 实例化 洪峰
某些应用程序可能会在很短的时间内创建许多Actor。这种突发将通过创建随机类型的actor并以X tps的固定速率激活它来模拟,以达到一定间隔的持续 D。频繁的Actor类型必须与应用中使用的actor 类型不同,但也应由 Hashtag Actor 服务注册,以确保服务获得流量负载。预计数据处理会有些缓慢,但在洪峰结束后恢复。
失败配置
失败守护程序将配置为每隔一小时执行以下模式 (即,活动 1 小时,空闲 1 小时)。
- Feed 流生成器的容器每 2 分钟崩溃一次。
- 消息分析器的容器每 3 分钟崩溃一次。
- Hashtag计数器的容器每 4 分钟崩溃一次。
- Hashtag Actor 服务的容器每 5 分钟崩溃一次。
- Hashtag计数器的POD每9分钟崩溃一次。
- Hashtag Actor服务的 POD 每 10 分钟崩溃一次。
- 消息分析器的服务每 7 分钟崩溃一次。
- 状态存储每 25 分钟中断一次。
- 状态存储速度为每 29 分钟 1 分钟(tps 将在实现期间定义)。
- 每 21 分钟中断一次主题。
- 每 23 分钟有 1 分钟的主题缓慢。
- Dapr的Sidecar 注入器与Hashtag 快照服务每13分钟崩溃一次。
- Dapr的placement每5分钟崩溃一次。
- Dapr的sentry服务每7分钟就会崩溃一次。
- Actor 的实例化每 10 分钟突发 1 分钟(tps 将在实现期间定义)。
如果上述所有故障在现实世界中都不能一起证明是可行的,那么 Failure Daemon 可以随机选择上述故障配置的子集(例如 5),并仅在给定运行中执行这些配置。
测试验证
测试验证通过 Azure 监视器中触发 sev3 的监视器上的警报进行。将配置以下监视器,并应始终保持正常:
数据处理
对于两个连续的数据点,验证工作人员的更改比率指标永远不应为零。此指标由验证工作程序发出。
消息分析器延迟
消息分析器必须发布自消息创建以来延迟的指标。任何消息都不应早于 2 分钟。此指标由消息分析器发出。
Hashtag计数器延迟
Hashtag计数器必须发布自消息创建以来延迟的指标。任何消息都不应早于 4 分钟。此指标由 Hashtag计数器发出。
过时快照
即使 Hashtag 快照服务正在运行,最后一个快照也可能太旧。Hashtag 快照服务应在自上次成功运行以来延迟时发布指标。延迟不应超过 5 分钟。此指标可由 Hashtag 快照服务发出。
服务运行状况
可以使用其他告警检测到完全中断。要检测部分故障,任何服务都不能在超过 50 分钟内具有少于 3 个正常运行的 POD。此衡量指标可由失败守护程序发出。
一般错误计数峰值
错误计数峰值时发出警报。确切的值将在实施过程中确定。
无错误
错误计数不应大于零超过 70 分钟(即,进入正常小时 10 分钟)。
欢迎大家扫描下面二维码成为我的客户,扶你上云


 浙公网安备 33010602011771号
浙公网安备 33010602011771号