【Redis】ziplist压缩列表
压缩列表
压缩列表是列表和哈希表的底层实现之一:
-
如果一个列表只有少量数据,并且数据类型是整数或者比较短的字符串,redis底层就会使用压缩列表实现。
-
如果一个哈希表只有少量键值对,并且每个键值对的键和值数据类型是整数或者比较短的字符串,redis底层就会使用压缩列表实现。
Redis压缩列表是由连续的内存块组成的列表,主要包含以下内容:
-
zlbytes:记录压缩列表占用的总的字节数,占用4个字节(32bits)
-
zltail:记录压缩列表的起始位置到最后一个节点的字节数,假如知道压缩列表的起始地址,只需要假设zltail记录的偏移量即可定位到压缩列表中最后一个节点的位置,占用4个字节(32bits)
-
zllen:记录了压缩列表中节点的数量,占用2个字节(16bits)
-
entry:存储数据的节点,可以有多个
-
zlend:标记压缩列表的结尾,值为255,占用1个字节(8bits)

压缩列表的创建
列表在初始化的时候会计算需要分配的内存空间大小,然后进行内存分配,之后将内存空间的最后一个字节标记为列表结尾,内存空间的大小计算方式如下:
-
压缩列表头大小,包括zlbytes、zltail和zllen所占用的大小:32 bits * 2 + 16 bits
-
压缩列表结尾大小:8bits
// 压缩列表头大小,包括zlbytes、zltail和zllen所占用的大小:32 bits * 2 + 16 bits
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// 压缩列表结尾大小:8bits
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
// 列表结尾标记
#define ZIP_END 255
unsigned char *ziplistNew(void) {
// 计算需要分配的内存大小
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
// 分配内存
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
// 将内存空间的最后一个字节标记为列表结尾
zl[bytes-1] = ZIP_END;
return zl;
}
所以在创建之后,内存布局如下,此时压缩列表中还没有节点:

之后如果如果需要添加节点,会进行移动,为新节点的插入腾出空间,所以还是占用的连续的空间:
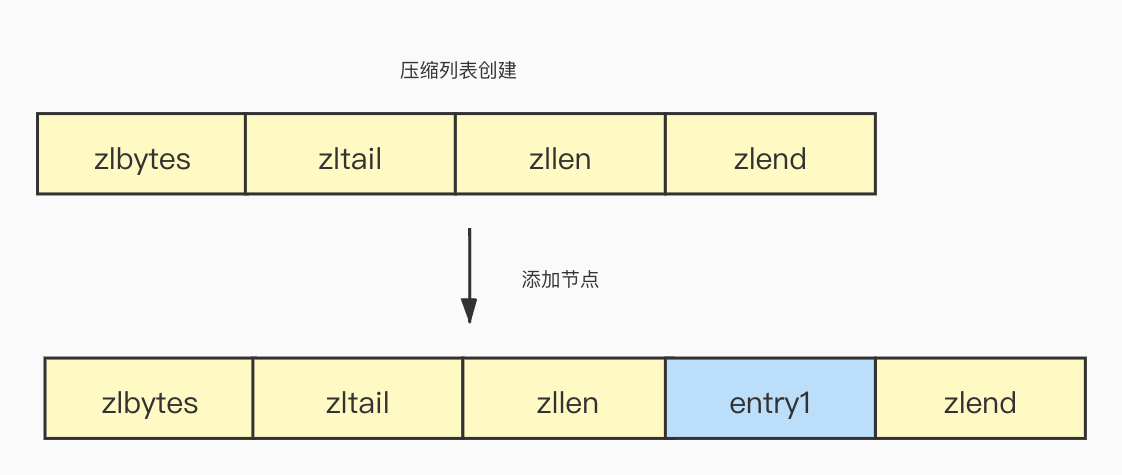
压缩列表节点
压缩列表的节点可以存储字符串或者整数类型的值,为了节省内存,它采用了变长的编码方式,压缩列表的节点的结构定义如下:
typedef struct zlentry {
unsigned int prevrawlensize; /* 前一个节点长度编码所需要的字节数*/
unsigned int prevrawlen; /* 前一个节点的长度(占用的字节数)*/
unsigned int lensize; /* 当前节点长度编码所需要的字节数*/
unsigned int len; /* 当前节点的长度(占用的字节数)*/
unsigned int headersize; /* header的大小,headersize = prevrawlensize + lensize. */
unsigned char encoding; /* 记录了数据的类型和数据长度 */
unsigned char *p; /* 指向数据的指针 */
} zlentry;
prevrawlen:存储前一个节点的长度(占用的字节数),这样如果从后向前遍历,只需要当前节点的起始地址减去长度的偏移量prevrawlen就可以定位到上一个节点的位置,prevrawlen的长度可以是1字节或者5字节:
- 如果前一项节点的长度小于254字节,那么prevrawlen的长度是1字节。
- 如果前一项节点的长度大于254字节,那么prevrawlen的长度是5字节,其中第一个字节会被设置为0xFE(十进制254),之后的四个字节用于保存前一个节点的长度。
为什么没有255字节?
因为255用来标记为压缩列表的结尾。
/* 节点编码所需要的字节数 */
unsigned int zipStorePrevEntryLength(unsigned char *p, unsigned int len) {
if (p == NULL) {
return (len < ZIP_BIG_PREVLEN) ? 1 : sizeof(uint32_t) + 1;
} else {
// 判断长度是否小于254
if (len < ZIP_BIG_PREVLEN) {
p[0] = len;
// 使用1个字节
return 1;
} else {
return zipStorePrevEntryLengthLarge(p,len);
}
}
}
// 节点编码所需要的字节数
int zipStorePrevEntryLengthLarge(unsigned char *p, unsigned int len) {
uint32_t u32;
if (p != NULL) {
// 将prevrawlen的第1个字节设置为254
p[0] = ZIP_BIG_PREVLEN;
u32 = len;
memcpy(p+1,&u32,sizeof(u32));
memrev32ifbe(p+1);
}
// 使用5个字节
return 1 + sizeof(uint32_t);
}
encoding:记录了节点的数据类型和内容的长度,因为压缩列表可以存储字符串或者整型,所以有以下两种情况:
-
存储内容为字符串
C语言存储字符串底层使用的是字节数组,当内容为字符串时分为三种情况,encoding分别占用1字节、2字节、5字节,encoding占用字节大小的不同,代表存储不同长度的字节数组。
| 编码 | 编码长度 | 数据类型 |
|---|---|---|
| 00xxxxxx | 占用1个字节,也就是8bits | 长度小于等于63(2^6 - 1)字节的字节数组 |
| 01xxxxxx xxxxxxxx | 占用2个字节,也就是16bits | 长度小于等于16383(2^14 - 1)字节的字节数组 |
| 10xxxxxx xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx | 占用5个字节,40bits | 长度小于等于4294967295(2^32 - 1)字节的字节数组 |
- 存储内容为整数
存储内容为整数时,encoding占用1个字节,最高位是11开头,后六位代表整数值的长度,其中当编码为1111xxxx时情况比较特殊,
后四位的值在0001和1101之间,此时直接代表数据的内容,是0到12之间的一个数字,并不是数据长度,因为它代表了数据内容,所以也不需要额外的空间存储数据内容。
| 编码 | 编码长度 | 数据类型 |
|---|---|---|
| 11000000 | 1个字节 | int16_t类型的整数 |
| 11010000 | 1个字节 | uint32_t类型的整数 |
| 11100000 | 1个字节 | uint64_t类型的整数 |
| 11110000 | 1个字节 | 24位有符号整数 |
| 11111110 | 1个字节 | 8位有符号整数 |
| 1111xxxx | 1个字节 | 特殊情况,后四位的值在0001和1101之间,此时代表的是数据内容,并不是数据长度 |
zipStoreEntryEncoding
// 节点编码所需字节数判断
unsigned int zipStoreEntryEncoding(unsigned char *p, unsigned char encoding, unsigned int rawlen) {
unsigned char len = 1, buf[5];
// 如果是字符串
if (ZIP_IS_STR(encoding)) {
/* 根据字符串的长度判断使用几个字节数 */
if (rawlen <= 0x3f) { // 小于等于63字节
if (!p) return len;
buf[0] = ZIP_STR_06B | rawlen;
} else if (rawlen <= 0x3fff) { // 小于等于16383字节
len += 1; // 使用2个字节
if (!p) return len;
buf[0] = ZIP_STR_14B | ((rawlen >> 8) & 0x3f);
buf[1] = rawlen & 0xff;
} else { // 字符串长度大于16383字节
len += 4; // 使用5个字节
if (!p) return len;
buf[0] = ZIP_STR_32B;
buf[1] = (rawlen >> 24) & 0xff;
buf[2] = (rawlen >> 16) & 0xff;
buf[3] = (rawlen >> 8) & 0xff;
buf[4] = rawlen & 0xff;
}
} else {
// 如果是整数,使用1个字节
if (!p) return len;
buf[0] = encoding;
}
/* 保存长度 */
memcpy(p,buf,len);
return len;
}
节点的插入
// 添加节点
// zl:指向压缩列表的指针
// s:数据内容
// slen:数据的长度
// where:在哪个位置添加
// 调用例子:zl = ziplistPush(zl, (unsigned char*)"foo", 3, ZIPLIST_TAIL);
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) {
unsigned char *p;
// 判断是在头部或者尾部进行添加
p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);
// 插入节点
return __ziplistInsert(zl,p,s,slen);
}
// 插入节点
// zl:指向压缩列表的指针
// p:添加的位置
// s:数据内容
// slen:数据的长度
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen, newlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789;
zlentry tail;
// 判断要添加的位置是否是结尾处
if (p[0] != ZIP_END) {// 如果不是尾部
// 计算前一个节点的长度prevlen
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else { // 如果是在尾部
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
// 计算前一个节点的长度
prevlen = zipRawEntryLengthSafe(zl, curlen, ptail);
}
}
// 判断节点是否可以被Encoding
if (zipTryEncoding(s,slen,&value,&encoding)) {
// 计算将字符串转换为整数后的长度
reqlen = zipIntSize(encoding);
} else {
// 直接使用原始长度
reqlen = slen;
}
// reqlen用来保存当前节点所占用的长度
// 加上前一个节点编码所需要的字节数
reqlen += zipStorePrevEntryLength(NULL,prevlen);
// 加上当前节点编码所需要的字节数
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
/* 这里用于判断节点加入的时候,后面的节点prevrawlen的字节数是否可以满足要插入节点的长度*/
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
offset = p-zl;
newlen = curlen+reqlen+nextdiff;
// 调整压缩列表的长度
zl = ziplistResize(zl,newlen);
p = zl+offset;
// 如果p不指向链表结尾,说明新加入的节点不是最后一个
if (p[0] != ZIP_END) {
/* 将p指向的节点和它之后的节点向后移动,为新节点腾出空间*/
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* 当前节点的长度编码后存储到后一个节点的prevrawlen*/
if (forcelarge)
zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
else
zipStorePrevEntryLength(p+reqlen,reqlen);
/* 更新结尾的OFFSET */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
assert(zipEntrySafe(zl, newlen, p+reqlen, &tail, 1));
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* 新加入的节点是列表的最后一个节点时 */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* 这里判断是否需要连锁更新 */
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* 插入节点*/
p += zipStorePrevEntryLength(p,prevlen);
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
// 修改压缩列表节点的数量
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
连锁更新
因为压缩列表中每个节点记录了前一个节点的长度:
- 如果前一项节点的长度小于254字节,那么prevrawlen的长度是1字节。
- 如果前一项节点的长度大于254字节,那么prevrawlen的长度是5字节,其中第一个字节会被设置为0xFE(十进制154),之后的四个字节用于保存前一个节点的长度。
假设有一种情况,一个压缩列表中,存储了多个长度是253字节的节点,因为节点的长度都在254字节以内,所以每个节点的prevrawlen只需要1个字节去存储长度的值:
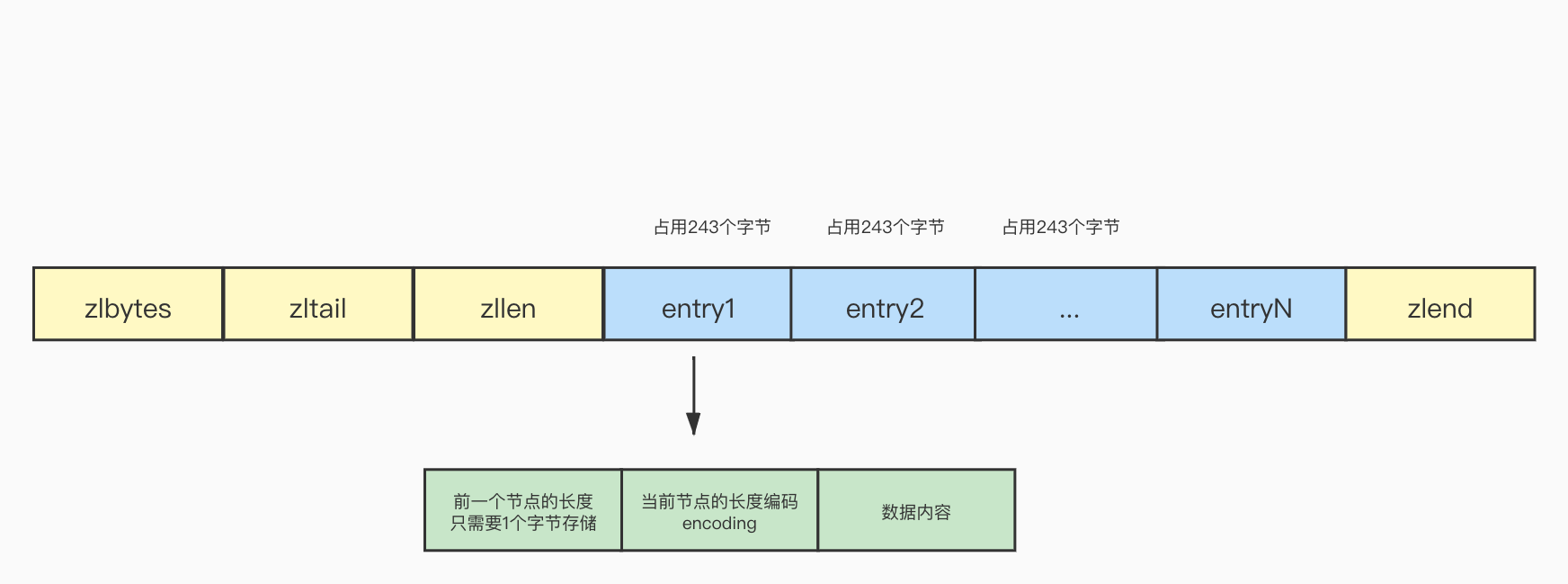
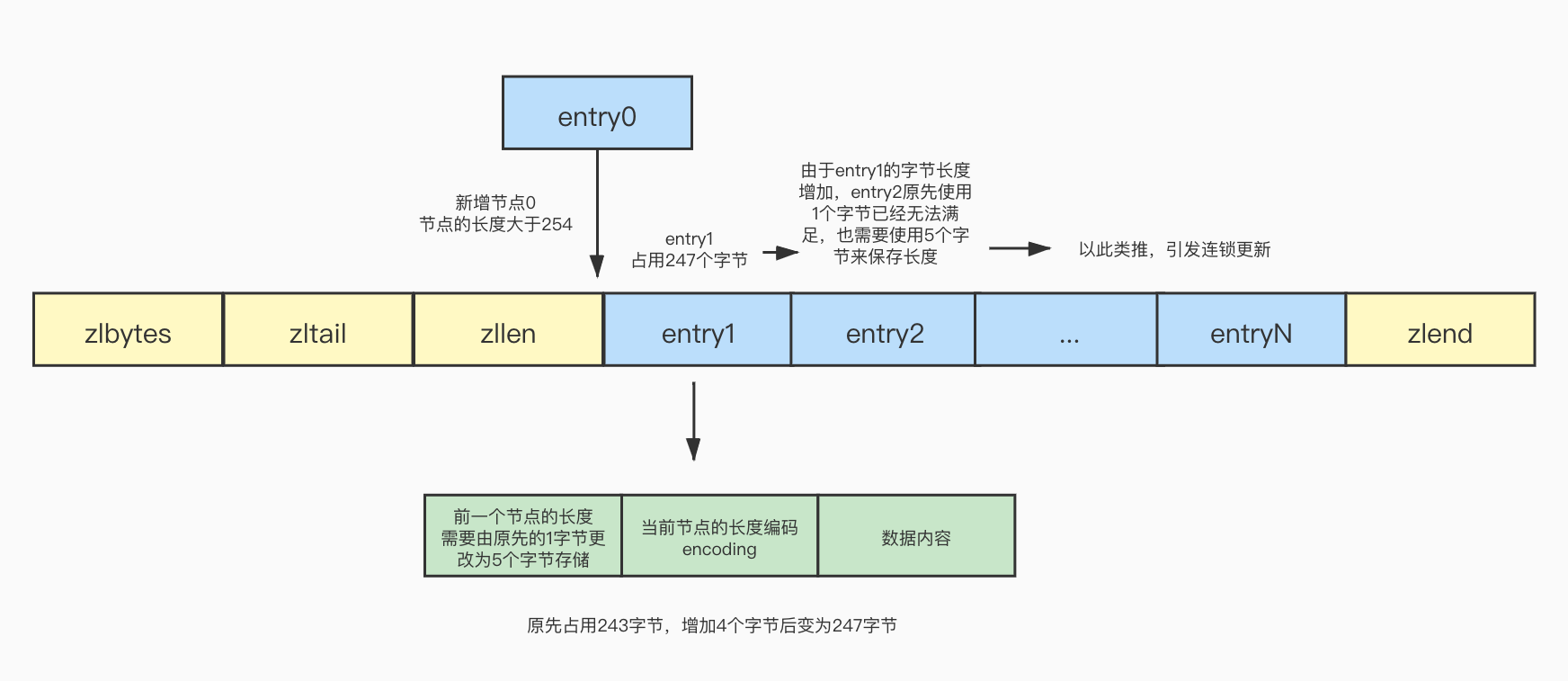
此时在列表的头部需要新增加一个节点,并且节点的长度大于254,这个时候原先的头结点entry1 prevrawlen使用1字节已经不能满足当前的情况了,必须要使用5字节存储,因此entry1的prevrawlen变成了5字节,entry1的长度也会跟着增加4个字节,已经超过了254字节,因为大于254就需要使用5个字节存储,所以entry2的prevrawlen也需要改变为5字节,后面的以此类推,引发了连锁更新,这种情况称之为连锁更新:
总结
(1)Redis压缩列表使用了一块连续的内存,来节约内存空间。
(2)压缩列表的节点可以存储字符串或者整数类型的值,它采用了变长的编码方式,根据数据类型的不同以及数据长度的不同,选择不同的编码方式,每种编码占用的字节大小不同,以此来节约内存。
(3)压缩列表的每个节点中存储了前一个节点的字节长度,如果知道某个节点的地址,可以使用地址减去字节长度定位到上一个节点,不过新增节点的时候,由于前一个节点的长度大于254使用5个字节,小于254使用1个字节存储,在一些极端的情况下由于长度的变化会引起连锁更新。
参考
黄健宏《Redis设计与实现》
【张铁蕾】Redis内部数据结构详解(4)——ziplist
【_HelloBug】Redis-压缩表-__ziplistInsert详解
Redis版本:redis-6.2.5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号