
爬虫中scrapy管道的使用
来源:http://www.shanhubei.com/archives/8595.html
一、pipeline中常用的方法
1. process_item(self,item,spider)
- 管道类中必须有的函数
- 实现对item数据的处理
- 必须return item
2. open_spider(self,spider):在爬虫开启的时候仅执行一次
3. close_spider(self,spider):在爬虫关闭的时候仅执行一次
二、管道的使用
总体思路:
- items中建模
- 创建爬虫cwangyi2
- 完善爬虫
- pipelines中写入一个新管道
- 在settings中打开管道
1.建模
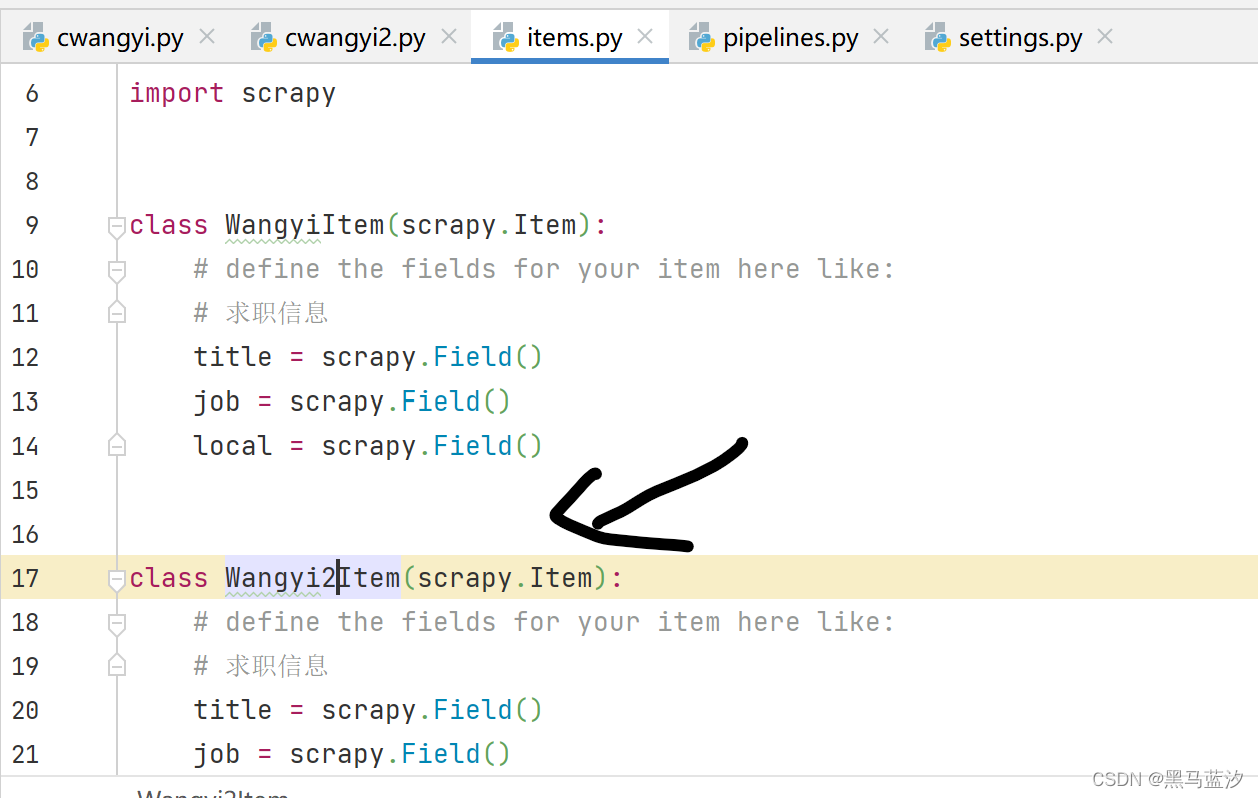
2. 创建爬虫

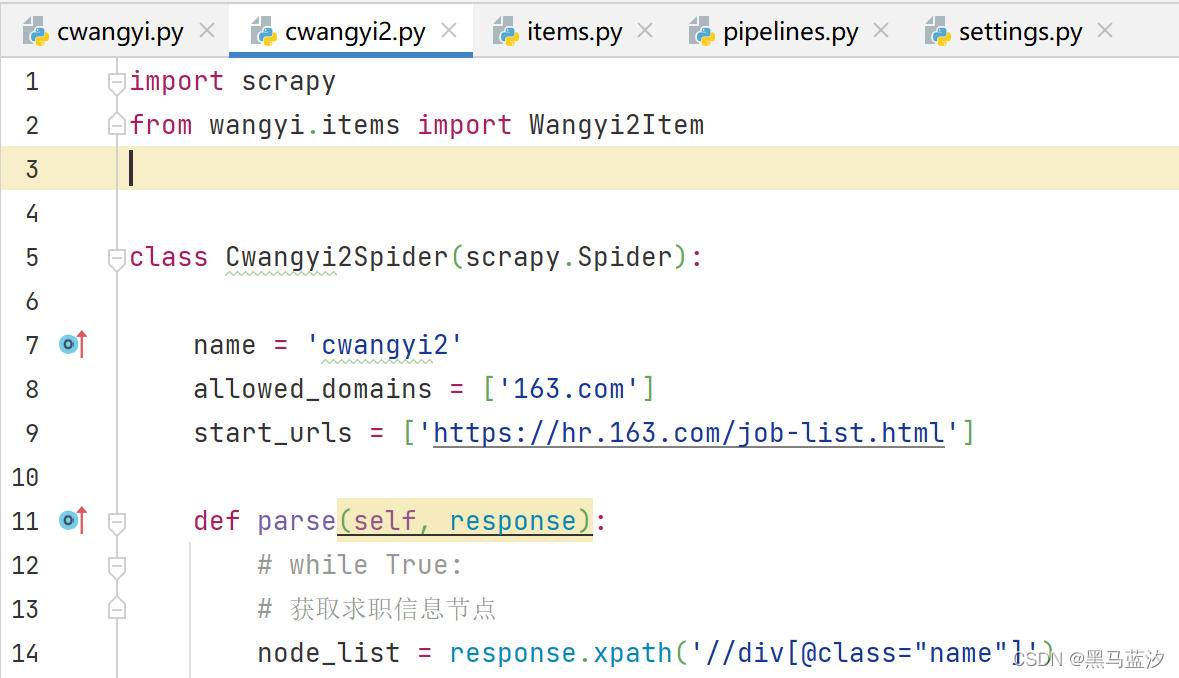
3. 完善爬虫
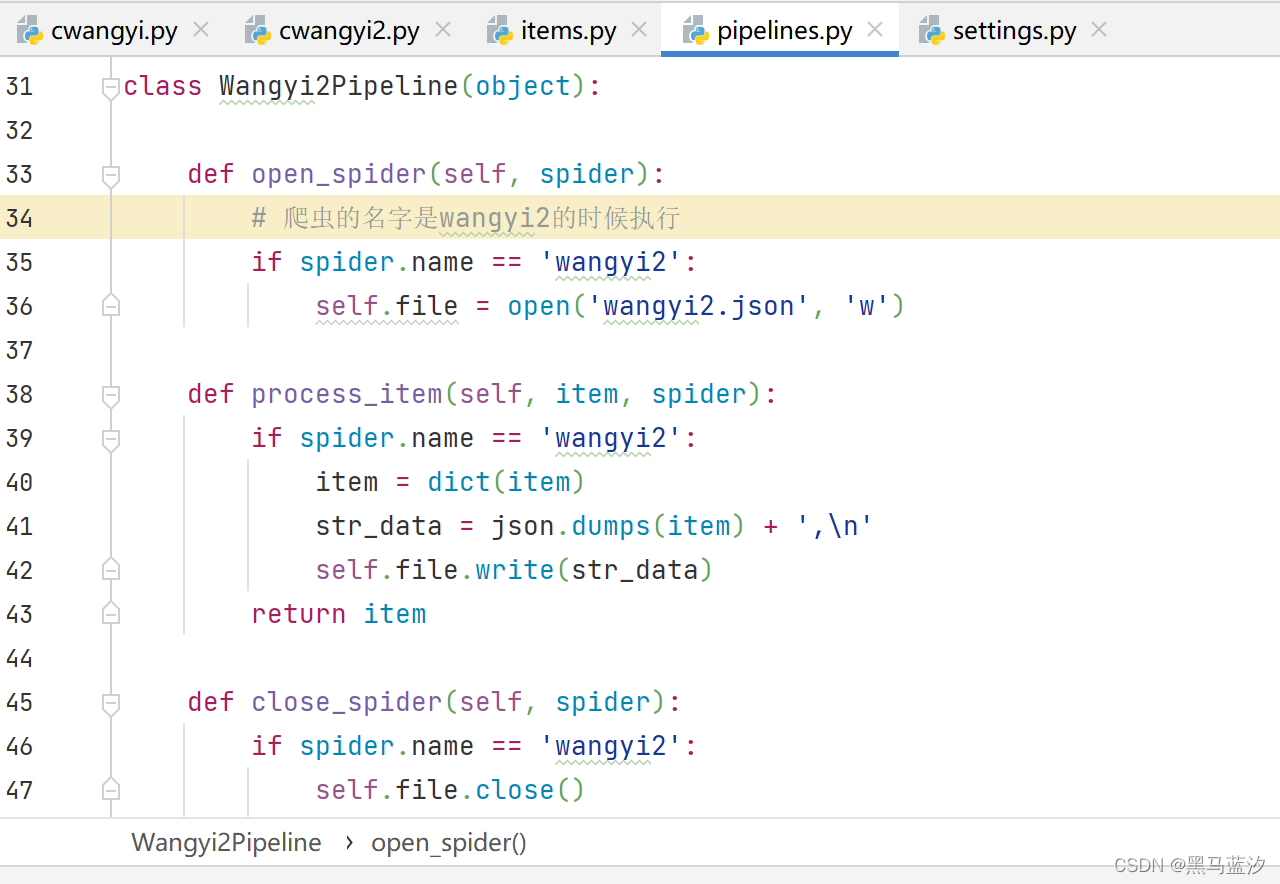
4. 写入新管道
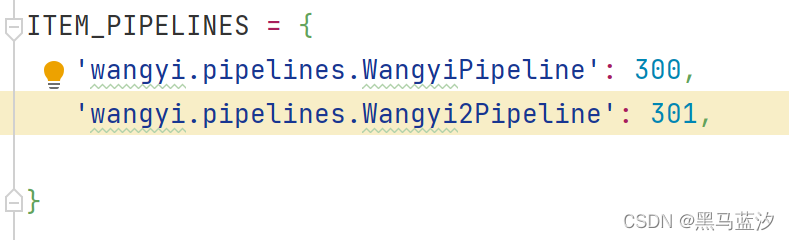
5. 打开管道
三、为什么settings中能够(需要)开启多个管道
不同的pipeline可以处理不同的爬虫数据,通过spider.name属性区分不同的pipeline能够对一个或多个爬虫进行不同的数据处理操作,比如一个进行数据清洗,一个进行数据保存
同一个管道类也可以处理不同爬虫的数据,通过spider.name属性来区分
四、pipeline使用注意点
使用之前需要在settings中开始
pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近的数据会越先经过:权重值小的优先执行
有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
pipeline中process_item的方法必须有,否则item没有办法接收和处理
process_item方法接收item和spider,其中spider表示当前传递item过来的spider
open_spider(spider):能够在爬虫开启的时候执行一次
close_spider(spider):能够在爬虫关闭的时候执行一次
上述两个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人