


SpringBoot - 使用hbase-client操作HBase教程2(过滤器Filter)
二、过滤器 Filter
1,基本介绍
Filter 可以在 Scan 的结果集基础之上,对返回的记录设置更多条件值,这些条件可以与 RowKey 有关,可以与列名有关,也可以与列值有关,还可以将多个 Filter 条件组合在一起等等。基于 Hbase 本身提供的三维有序(主键有序、列有序、版本有序),这些 Filter 可以高效的完成查询过滤的任务。
注意:Filter 可能会导致查询响应时延变的不可控制。因为我们无法预测,为了找到一条符合条件的记录,背后需要扫描多少数据量,如果在有效限制了 Scan 范围区间(通过设置 StartRow 与 StopRow 限制)新版是(withstartRow和withstopRow)的前提下,该问题能够得到有效的控制。
2,过滤操作的参数
(1)要完成一个过滤的操作,至少需要两个参数。一个是如下抽象的操作符(比较运算符),Hbase 提供了枚举类型的变量来表示这些抽象的操作符:
BinaryComparator 按字节索引顺序比较指定字节数组,采用 Bytes.compareTo(byte[]) BinaryPrefixComparator 跟前面相同,只是比较左端的数据是否相同 NullComparator 判断给定的是否为空 BitComparator 按位比较 RegexStringComparator 提供一个正则的比较器,仅支持 EQUAL 和非 EQUAL SubstringComparator 判断提供的子串是否出现在 value 中
附:过滤器的分类以及样例演示
1,准备工作
(1)为了方便使用,首先对前文的 HBaseUtils.java 工具类稍作修改,增加如下方法,可以传入一个 Filter 继续数据过滤:
/** * 获取数据(根据传入的filter) * @param tableName 表名 * @param filter 过滤器 * @return map */ public List<Map<String, String>> getData(String tableName, Filter filter) { List<Map<String, String>> list = new ArrayList<>(); try { Table table = hbaseAdmin.getConnection().getTable(TableName.valueOf(tableName)); Scan scan = new Scan(); // 添加过滤器 scan.setFilter(filter); ResultScanner resultScanner = table.getScanner(scan); for(Result result : resultScanner) { HashMap<String, String> map = new HashMap<>(); //rowkey String row = Bytes.toString(result.getRow()); map.put("row", row); for (Cell cell : result.listCells()) { //列族 String family = Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength()); //列 String qualifier = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()); //值 String data = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()); map.put(family + ":" + qualifier, data); } list.add(map); } table.close(); } catch (IOException e) { e.printStackTrace(); } return list; }
在上一篇工具类里面已经封装好了
(2)然后创建一张 test 表,并添加一些数据:
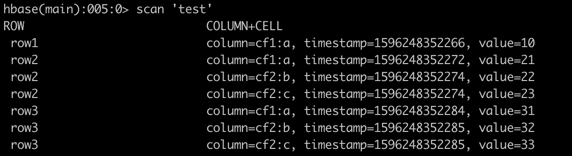
2,行键过滤器(RowFilter)
@RestController public class HelloController { @Autowired private HBaseUtils hbaseUtils; @GetMapping("/test") public void test() { // 筛选出行键大于row1的数据 Filter rowFilter = new RowFilter(CompareOperator.GREATER, new BinaryComparator("row1".getBytes())); List<Map<String, String>> tableData = hbaseUtils.getData("test", rowFilter); System.out.println(tableData); } }

3,列簇过滤器(FamilyFilter)
// 筛选出列族为cf2的数据 Filter familyFilter = new FamilyFilter(CompareOperator.EQUAL, new BinaryComparator("cf2".getBytes())); List<Map<String, String>> tableData = hbaseUtils.getData("test", familyFilter); System.out.println(tableData);

4,列过滤器(QualifierFilter)
// 筛选出列名为b的数据 Filter qualifierFilter = new QualifierFilter(CompareOperator.EQUAL, new BinaryComparator("b".getBytes())); List<Map<String, String>> tableData = hbaseUtils.getData("test", qualifierFilter); System.out.println(tableData);

5,列前缀过滤器(ColumnPrefixFilter)
//筛选出列前缀为b的数据 ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter("b".getBytes()); List<Map<String, String>> tableData = hbaseUtils.getData("test", columnPrefixFilter); System.out.println(tableData);

6,值过滤器(ValueFilter)
// 筛选出值为22的数据 Filter valueFilter = new ValueFilter(CompareOperator.EQUAL.EQUAL, new SubstringComparator("22")); List<Map<String, String>> tableData = hbaseUtils.getData("test", valueFilter); System.out.println(tableData);

7,单列值过滤器(SingleColumnValueFilter)
//筛选出列族为cf2,列为c,且值为33的整行数据 SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter( "cf2".getBytes(), "c".getBytes(), CompareOperator.EQUAL.EQUAL, new SubstringComparator("33")); //如果不设置为 true,则那些不包含指定 column 的行也会返回 singleColumnValueFilter.setFilterIfMissing(true); List<Map<String, String>> tableData = hbaseUtils.getData("test", singleColumnValueFilter); System.out.println(tableData);

8,单列值排除器(SingleColumnValueExcludeFilter)
SingleColumnValueExcludeFilter 跟上面的 SingleColumnValueFilter 功能一样,仅仅是不查询出该列的值。
//筛选出列族为cf2,列为c,且值不为33的整行数据(但会把该列数据排除) SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter( "cf2".getBytes(), "c".getBytes(), CompareOperator.EQUAL.EQUAL, new SubstringComparator("33")); //如果不设置为 true,则那些不包含指定 column 的行也会返回 singleColumnValueExcludeFilter.setFilterIfMissing(true); List<Map<String, String>> tableData = hbaseUtils.getData("test", singleColumnValueExcludeFilter); System.out.println(tableData);

9,行键前缀过滤器(PrefixFilter)
//筛选出行键前缀为ro的整行数据 PrefixFilter prefixFilter = new PrefixFilter("ro".getBytes()); List<Map<String, String>> tableData = hbaseUtils.getData("test", prefixFilter); System.out.println(tableData);

10,时间戳过滤器(TimestampsFilter)
// 筛选出时间戳为1596248352266或1596248352285的数据 List<Long> list = new ArrayList<>(); list.add(1596248352266L); list.add(1596248352285L); TimestampsFilter timestampsFilter = new TimestampsFilter(list); List<Map<String, String>> tableData = hbaseUtils.getData("test", timestampsFilter); System.out.println(tableData);
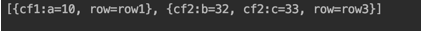
补充知识 查询最后10条
scan 'mytable1', {COLUMNS => ['student:age', 'student:age'], REVERSED => true,LIMIT => 10, STARTROW => '0019000000',ENDROW => '0019000000'}
代码如下
//倒序且查询最近5个点 Scan scan = new Scan(); scan.withStopRow((vid+dateFormat.format(beforeThreemonth)).getBytes()).withStartRow((vid+dateFormat.format(now)).getBytes()); scan.setLimit(5); scan.setReversed(true);
早年同窗始相知,三载瞬逝情却萌。年少不知愁滋味,犹读红豆生南国。别离方知相思苦,心田红豆根以生。

