
Hive的架构和执行流程
1. Hive架构组成
Hive的架构组成,包括三部分Hive Client、Hive Service、Hive Storage and Computing

A. Hive Client,Hive的客户端
针对不同的应用程序提供了不同的驱动,例如像是
a. JDBC驱动
b. ODBC驱动
c. Thrift Client
B. Hive Service,Hive的服务端
分为三个部分,用户接口组件、Diver组件、Metastore组件
a. 用户接口组件
CLI:命令行方式
HWI:页面操作方式
HiveServer:对接Api程序
b. Diver组件
Hive 驱动引擎,Hive的核心。该组件包含编译器、优化器和执行引擎。
它的作用是将hiveSQL语句进行解析、编译优化、生成执行计划,然后调用底层MR计算框架。
c. Metastore组件
元数据服务组间。Hive的数据分为两部分。
一部分为业务数据,保存在HDFS中。另一部分为对业务数据的描述数据,即元数据,保存在Derby或MySQL数据库中。
Meta store:访问元数据存储的入口
File System:访问文件系统的入口,分布式文件系统或本地文件系统
Job Client:提交job作业的入口
C.Hive Storage and Computing
元数据存储组件和计算引擎。Hive的外部组件。
a. 元数据存储数据库(Derby、MySQL)
b. 计算引擎(MR、Spark等)
2. Hive的工作流程
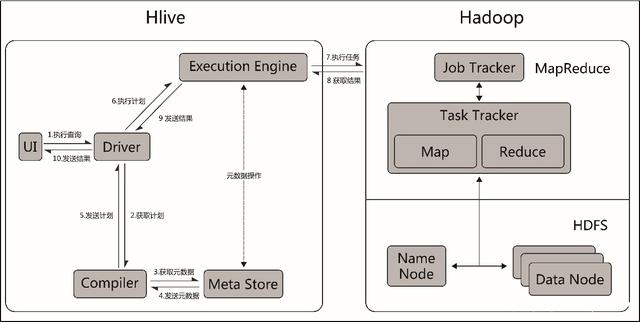
A. 详细执行流程
a. 通过用户接口组件,如命令行方式、页面操作方式或不同驱动程序(JDBC、ODBC等)的客户端。
向Hive Driver发送执行命令。目的是获取查询结果。
b. 获取查询计划,Driver拿到执行命令后,会向Complier(编译器)获取查询计划
c. 获取元数据信息,编译器生成查询计划,首先要获取相关的元数据信息。此步骤为编译器向元数据组间获取元数据信息。
d. 元数据组间向编译器发送元数据信息
e. 编译器根据获取元数据信息生产计划计划
f. 编译器将查询计划返回给Driver
g. Driver将查询计划交给优化器做优化
h. Driver将优化后的执行计划发送给执行器,执行器向元数据组间请求相关的元数据
i. 执行器将执行计划通过接口提交给Hadoop并执行job任务
j. Hadoop将执行的结果返回给执行器,并更新对应的元数据。
k. 执行器将执行结果交给Driver
l. Driver将执行结果返回给客户端
B. 概要执行流程
Hive接到命令之后,首先会去元数据库获取元数据,
然后把元数据信息和作业计划发送Hadoop集群执行任务,
再将最终的结果返回。

