缓存雪崩一般是由某个缓存节点失效,导致其他节点的缓存命中率下降,缓存中确实的数据去数据库查询,短时间内,造成数据库服务器的崩溃。
这时,我们需要重启数据库,但重启一段时间后,又会被压垮,但此时缓存的数据也比之前要多。
这样,反复几次重启数据库,缓存才重建完成,数据库才稳定的运行。
或者,是由于缓存周期性的失效,比如每6个小时失效一次,那么每6个小时,将有一个请求的峰值,严重者设置会令数据库崩溃。
可以看下面的这幅统计图,是数据库的访问量统计图:
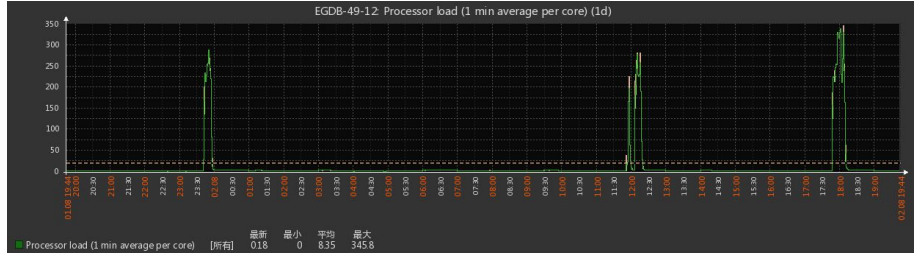
可以看到,缓存每6个小时就失效一次,每过6个小时就到了一次请求的高峰时期,那这样的话,每过6个小时数据库就会崩溃一次的。
我们可以采用的解决方案是:
可以把缓存设置的失效的时间设置为3到9小时的生命周期,这样不同时失效,把工作分担到各个时间点上去
缓存无底洞现象:
该问题由facebook的工作人员提出的,facebook在2010年左右,memcached节点就已经达
3000个.缓存数千G内容.
他们发现了一个问题---memcached连接频率,效率下降了,于是加memcached节点,
添加了后,发现因为连接频率导致的问题,仍然存在,并没有好转,称之为”无底洞现象”.
multiget-hole的问题分析:
以用户为例:user-133-age,user-133-name,user-133-height ... N个ke,当服务器增多的时候,133号用户的信息,也被更散落在更多的节点上,所以,同样是访问个人主页,得到相同的个人信息,节点越多,要连接的节点也越多,对于memecached的连接数,并没有随着节点的增多,而降低。于是出现了无底洞现象。
multiget-hole的解决方案:
把某组key,按其共同前缀,来进行分布:
比如 user-133-age,user-133-name,user-133-height 这3个key,在使用分布式计算法求其节点时,应该以‘user-133’来进行计算,而不是以 user-133-age/name/height来进行计算。
这样,3个关于个人信息的key,都落在同1个节点上,访问个人主页时,只需要连接1个节点.问题得到解决
1 事实上: 2 NoSQL和传统的RDBMS,并不是水火不容,两者在某些设计上,是可以相互参考的. 3 4 对于memcached,redis这种kv存储,key的设计,可以参考MySQL中表/列的设计. 5 6 比如:user表下,有age列,name列,身高列, 7 对应的key,可以用user:133:age=23,user:133:name=‘lisi’,user:133:height=168;
