
redis高级用法
1 高级用法之慢查询

# 讲5大数据类型,O(n), 命令执行时间很长,redis 命令操作 单线程架构 ,阻塞 -单线程架构:并发操作不需要锁 -mysql:行锁,表锁,并发操作数据错乱的问题 # 慢查询命令 记录下来,以备后期查看,排查,redis的配置,用来记录慢查询,如果符合这个配置,这条命令就会被记录 # 命令操作生命周期 -客户端到服务端的网络时间 -执行命令时间 (咱们指的慢查询指这里),设定一个时间,如果超过了这个时间,咱们就认为是慢查询 -服务端返回客户端时间 # 配置:两个配置项 config get slowlog-max-len=128 # 慢查询队列是128 config get slowly-log-slower-than=10000 # 微秒,超过这个时间,我们就记录 # 动态配置 config set slowlog-log-slower-than 0 # 记录所有 config set slowlog-max-len 128 # 持久化到本地配置文件 config rewrite # 查看慢命令队列 slowlog get [n] #获取慢查询队列 ''' 日志由4个属性组成: 1)日志的标识id 2)发生的时间戳 3)命令耗时 4)执行的命令和参数 ''' slowlog len #获取慢查询队列长度 slowlog reset #清空慢查询队列 # 作用 -后期发现redis速度非常慢,开启慢日志,过一会,查看一下慢命令,取出慢命令,分析这个命令是不是必须要执行,把这个慢命令换一种方式实现,从而加快操作速度
2 pipline与事务
# redis 本身不支持事务,通过管道实现部分事务 Redis的pipeline(管道)功能在命令行中没有,但redis是支持pipeline的,而且在各个语言版的client中都有相应的实现 将一批命令,批量打包,在redis服务端批量计算(执行),然后把结果批量返回 1次pipeline(n条命令)=1次网络时间+n次命令时间 # python代码实现 import redis pool = redis.ConnectionPool(host='127.0.0.1', port=6379) r = redis.Redis(connection_pool=pool) #创建pipeline pipe = r.pipeline(transaction=True) #开启事务 pipe.multi() pipe.set('name', 'lqz') #其他代码,可能出异常 pipe.set('role', 'nb') pipe.execute() # 一次性执行命令 ,在这之前,如果处理异常,所有命令都不会执行,保证了一致性 # 了解,原生事务操作 # 1 mutil 开启事务,放到管道中一次性执行 multi # 开启事务 set name lqz set age 18 exec # 原生redis使用管道 # 2 模拟事务 # 在开启事务之前,先watch,只有这个age,在整个过程中没有被改变,才能正常修改成功,如果在执行exec时发现,age被改了,就修失败 watch age multi decr age exec # 另一台机器 multi decr age exec # 先执行,上面的执行就会失败(乐观锁,被wathc的事务不会执行成功)
3 发布订阅
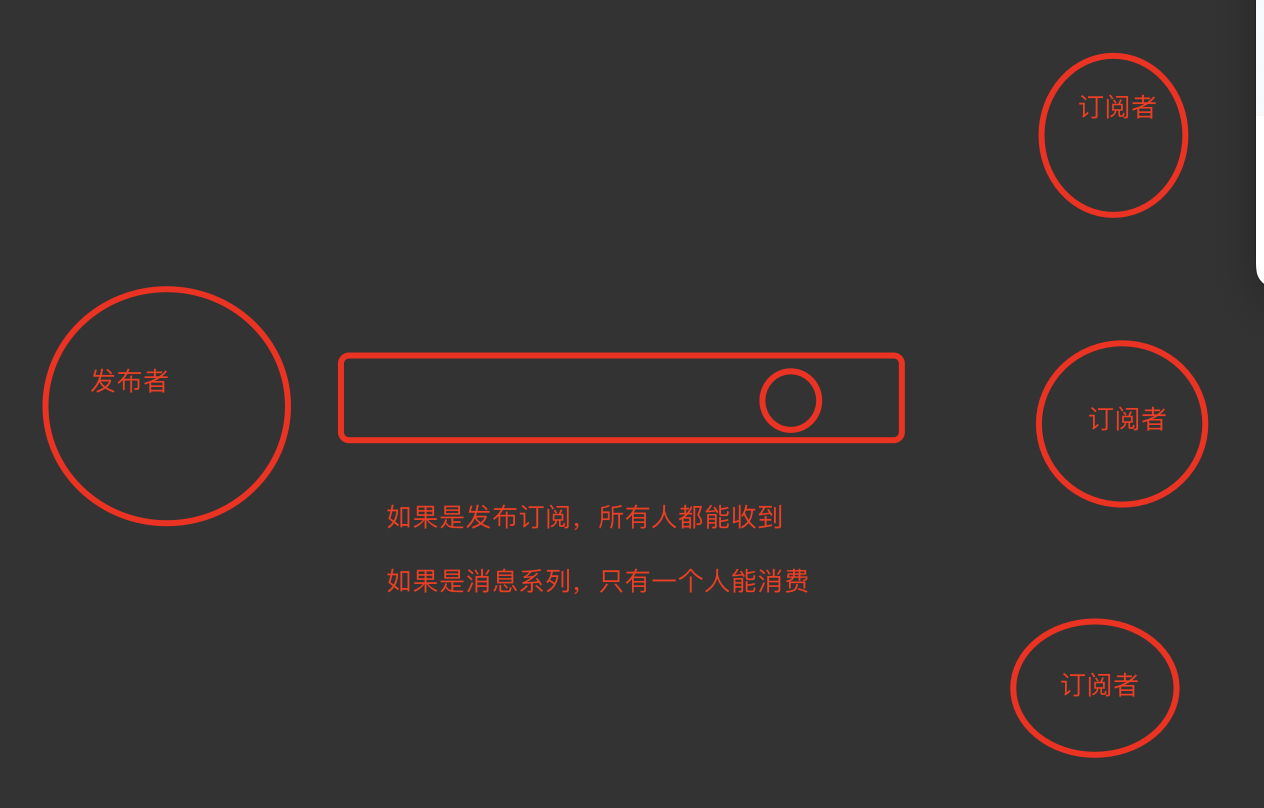
# 观察者模式:我们现在订阅了一个人,只要这个人发生变化,我们都能收到变化 发布者发布了消息,所有的订阅者都可以收到,就是生产者消费者模型(后订阅了,无法获取历史消息) # 关注了某个明星,只要明星发布动态,大家都能收到 # 订阅了某个人的博客,只要它发布新博客,都能收到 # 订阅了某个商品的抢购提醒,当要开始抢购的时候,你收到短信通知 # redis实现发布订阅 # 1 发布消息 publish souhu:tv "hello world" # 2 订阅消息 subscribe souhu:tv # 发布订阅和消息队列区别 -只要订阅了,所有人都能收到消息 -消息队列,只有一个人能抢到消息
4 bitmap位图
# 本质是字符串,可以操作某个比特位 # 比如字符串是 big,设置和获取某个比特位 set hello big #放入key位hello 值为big的字符串 00000000 00000000 00000000 # 获取比特位 getbit hello 0 #取位图的第0个位置,返回0 getbit hello 1 #取位图的第1个位置,返回1 如上图 # 设置比特位 setbit hello 7 1 # 获取对应的字符串 get hello # 获取指定范围内1 的个数 ,前闭后闭区间 bitcount key start到end, 单位为字节,注意按字节一个字节8个bit为 # 作用:做独立用户统计,日活用户统计,大数据量的日活统计,使用它会节约内存 -用户id 是数字,1,2,3.... -日活:每日的用户活跃数,用户登录后,把id号放到集合中 - 1 2 3 9999 字符串 9999四个字符 4*8 32个比特位,用户量越多,存储用户id用的空间就越大 -使用setbit设置 ,只要用户登录了,就在对应的位置设为1,没有登录就是0 setbit users 9999 1 setbit users 1 1 最终通过bitcount计算出总共有多少个1,就是多少个活跃用户 -抖音日活 -集合 : 用户id方式 3亿用户*32比特位 -位图 方式 3亿*1 个比特位 setbit users 10亿 1 # 做日活,使用集合和位图比较 1 使用set和Bitmap对比 2 1亿用户,5千万独立(1亿用户量,约5千万人访问,统计活跃用户数量) 数据类型 每个userid占用空间 需要存储用户量 全部内存量 set 32位(假设userid是整形,占32位) 5千万 32位*5千万=200MB bitmap 1位 1亿 1位*1亿=12.5MB 假设有10万独立用户,使用位图还是占用12.5mb,使用set需要32位*1万=4MB
5 HyperLogLog
# HyperLogLog:本质还是字符串 基于HyperLogLog算法:极小的空间完成独立数量统计 # 用来统计某个值是否在其中,只能统计,不能取出来 # 集合可以取值,统计是否在其中,但是集合占的空间大 # 使用 pfadd key element #向hyperloglog添加元素,可以同时添加多个 pfcount key #计算hyperloglog的独立总数 # 类似于集合,去重,统计某个元素是否在其中,之前使用去重的地方,就可以使用它 # 独立用户统计,也可以使用HyperLogLog -如果用户id不是数字,而是uuid无规律的形式 asdf-asdfw-dsdf-asdf # 错误率,布隆过滤器本质是一样的,使用HyperLogLog算法 百万级别独立用户统计,百万条数据只占15k 错误率 0.81% 无法取出单条数据,只能统计个数
# GEO(地理信息定位):存储经纬度,计算两地距离,范围等 -抖音,附近的人 -美团,附近的美食 -交友软件,附近的美女 # 存储经纬度,通过经纬度,计算距离 -经纬度哪里来?前端(app,网页),前端获取用户授权,用户授权后,通过某个方法,可以直接获取到手机的位置,获取出来就是经纬度 -通过后台某个接口,把此时的经纬度,提交到后台,后台保存到redis的geo中 #1 存数据 geoadd user:locations 116.28 39.55 1 geoadd user:locations 116.28 42.55 2 geoadd cities:locations 116.28 39.55 beijing geoadd cities:locations 117.12 39.08 tianjin geoadd cities:locations 114.29 38.02 shijiazhuang geoadd cities:locations 118.01 39.38 tangshan geoadd cities:locations 115.29 38.51 baoding # 2 获取地理位置信息 ---->获取张三的位置 # geopos user:locations 2 --->经纬度----》开放的接口,通过经纬度获得具体的位置信息 geopos cities:locations beijing #获取北京地理信息 # 3 获取两个地点的距离 geodist cities:locations beijing tianjin km # 4 方圆100km内有哪些城市 # 改一个接口,交友类app,附近5公里的美女,每次都会把它自己查出来,不显示自己,只查别人 georadiusbymember cities:locations beijing 150 km # geo 本质是zset类型
7 持久化
# redis redis的所有数据保存在内存中,对数据的更新将异步的保存到硬盘上,更新到硬盘上这个操作称之为持久化 # 常见的持久化方案 快照:某时某刻数据的一个完成备份 -mysql的Dump -redis的RDB 写日志:任何操作记录日志,要恢复数据,只要把日志重新走一遍即可 -mysql的 Binlog -Redis的 AOF # redis 支持两种持久化方案 -rdb :快照,某一时刻完整备份 -aof: 日志,进行了操作就记录日志 -混合持久化:rdb+aof方案,后来加入的,为了快速恢复数据
# 三种触发机制 -手动:save -手动:bgsave -配置文件:符合条件就触发 # 方式一: -在客户端执行save,把此时内存中的数据,完整的备份到硬盘上,生成一个xx.rdb 文件,当redis服务器停止,再启动,会加载rdb文件数据到内存,达到快速恢复的效果 -sava 会阻塞住,导致其他命令执行不了 # 方式二: -在客户端执行bgsave,异步备份,不会阻塞其他命令的执行 # 方式三:配置文件 ,用它比较多 save 900 1 save 300 10 save 60 10000 # 如果60s中改变了1w条数据,自动生成rdb # 如果300s中改变了10条数据,自动生成rdb # 如果900s中改变了1条数据,自动生成rdb # 我的配置 save 900 20 save 300 10 save 60 5 dbfilename dump.rdb # 客户端主动关闭服务端时,也会触发 # rdb 方案会存在数据丢失的情况,一般咱们用redis做缓存,可以使用这种方案,缓存丢失,影响不大,但如果对数据准确性要求比较高,应该使用aof方案
7.2 aof 方案
# 客户端每写入一条命令,都记录一条日志,放到日志文件中,如果出现宕机,可以将数据完全恢复 # AOF的三种策略 日志不是直接写到硬盘上,而是先放在缓冲区,缓冲区根据一些策略,写到硬盘上 always:redis–》写命令刷新的缓冲区—》每条命令fsync到硬盘—》AOF文件 # redis写入速度很快,每条日志都立马写到硬盘上,硬盘性能跟不上 everysec(默认值):redis——》写命令刷新的缓冲区—》每秒把缓冲区fsync到硬盘–》AOF文件 # 每s把日志写到硬盘上 no:redis——》写命令刷新的缓冲区—》操作系统决定,缓冲区fsync到硬盘–》AOF文件 # 操作系统决定 # AOF 重写策略 随着命令的逐步写入,并发量的变大, AOF文件会越来越大,通过AOF重写来解决该问题 本质就是把过期的,无用的,重复的,可以优化的命令,来优化 这样可以减少磁盘占用量,加速恢复速度 # 配置文件配置好,会自动开启aof重写,优化aof日志文件 auto-aof-rewrite-min-size # AOF文件到达某个尺寸,就触发aof重写 auto-aof-rewrite-percentage # AOF文件增长率,到达某个比率,就触发aof重写 # 最佳配置 appendonly yes #将该选项设置为yes,打开,开启aof appendfilename appendonly.aof #文件保存的名字 appendfsync everysec #采用第二种策略 no-appendfsync-on-rewrite yes #在aof重写的时候,是否要做aof的append操作,因为aof重写消耗性能,磁盘消耗,正常aof写磁盘有一定的冲突,这段期间的数据,允许丢失 # 我们公司采用了什么持久化方案 -如果是缓存,就用rdb -如果对数据准确性要求高,就用aof -混合持久化:两个都开启
8 主从复制
# mysql 主从复制 ,原理 binlog,relaylog,io线程,sql线程 # redis 主从复制 # 主从复制出现原因 问题:机器故障;容量瓶颈;QPS瓶颈 解决问题:一主一从,一主多从,做读写分离,做数据副本 扩展数据性能 一个master可以有多个slave 一个slave只能有一个master 数据流向是单向的,从master到slave # redis主从复制原理 1. 副本库通过slaveof 127.0.0.1 6379命令,连接主库,并发送SYNC给主库 2. 主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库 3. 副本库接收后会应用RDB快照 4. 主库会陆续将中间产生的新的操作,保存并发送给副本库 5. 到此,我们主复制集就正常工作了 6. 再此以后,主库只要发生新的操作,都会以命令传播的形式自动发送给副本库. 7. 所有复制相关信息,从info信息中都可以查到.即使重启任何节点,他的主从关系依然都在. 8. 如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送PSYNC给主库 9. 主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的
8.1 主从复制搭建
# 方式一: -两台机器,启动两个redis进程 # 第一台机器配置 daemonize yes port 6379 dir "/root/redis/data" logfile "6379.log" save 900 20 save 300 10 save 60 5 dbfilename dump.rdb appendonly yes appendfilename appendonly.aof appendfsync everysec no-appendfsync-on-rewrite yes # 第二台机器配置 daemonize yes port 6380 dir "/root/redis/data2" logfile "6380.log" save 900 20 save 300 10 save 60 5 dbfilename dump.rdb appendonly yes appendfilename appendonly.aof appendfsync everysec no-appendfsync-on-rewrite yes # 启动两个redis-server服务 redis-server ./redis_6379.conf redis-server ./redis_6380.conf ps aux |grep redis # 在6380库上执行 slaveof 127.0.0.1 6379 以后6380库就是6379的从库了,不能再写数据了 # (error) READONLY You can't write against a read only replica. # info 命令查看主从关系 # 一主多从也是同理
8.2 配置文件搭建方式
# 在从库配置文件加入 slaveof 127.0.0.1 6379 slave-read-only yes # 在俩从库配置文件中加入 # 启动三个redis服务 -6379 主 -6380 从 -6381 从 # 停掉一个从库,主从关系还在 # 停掉主库,就不能写数据了
9 哨兵
##### 第一步:搭建一主两从 #第一个是主配置文件 daemonize yes pidfile /var/run/redis.pid port 6379 dir "/root/redis/data" logfile 6379.log #第二个是从配置文件 daemonize yes pidfile /var/run/redis2.pid port 6378 dir "/root/redis/data1" logfile 6378.log slaveof 127.0.0.1 6379 slave-read-only yes #第三个是从配置文件 daemonize yes pidfile /var/run/redis3.pid port 6377 dir "/root/redis/data2" logfile 6377.log slaveof 127.0.0.1 6379 slave-read-only yes #把三个redis服务都启动起来 redis-server ./redis_6379.conf redis-server ./redis_6378.conf redis-server ./redis_6377.conf ### 第二步:2 搭建哨兵 # sentinel.conf这个文件 # 【把哨兵也当成一个redis服务】 创建三个配置文件分别叫sentinel_26379.conf sentinel_26378.conf sentinel_26377.conf # 当前路径下创建 data1 data2 data3 个文件夹 #内容如下(需要修改端口,文件地址日志文件名字) vim sentinel_26379.conf port 26379 daemonize yes dir /root/redis/data protected-mode no bind 0.0.0.0 logfile "redis_sentinel.log" sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 180000 vim sentinel_26378.conf port 26378 daemonize yes dir /root/redis/data1 protected-mode no bind 0.0.0.0 logfile "redis_sentinel1.log" sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 180000 vim sentinel_26377.conf port 26377 daemonize yes dir /root/redis/data2 protected-mode no bind 0.0.0.0 logfile "redis_sentinel2.log" sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 180000 #启动三个哨兵 redis-sentinel ./sentinel_26379.conf redis-sentinel ./sentinel_26378.conf redis-sentinel ./sentinel_26377.conf # 第三步:登录哨兵,查看信息 redis-cli -p 26379 info # 查看哨兵信息 redis-cli -p 6379 info # 查看主从信息 # 第四步:故障演示 主库停掉,哨兵会自动做故障切换,把6378作为了主库,6377还是从库 把原来6379启动,现在它就变成了从库(不是主库了) # 解释 sentinel monitor mymaster 127.0.0.1 6379 2 # 服务名字叫 mymaster 2个哨兵觉得主库挂掉了,主库就真的挂掉了,就开始做故障切换 sentinel down-after-milliseconds mymaster 30000 # 这个配置项指定了需要多少失效时间,一个master才会被这个sentinel主观地认为是不可用的。 单位是毫秒,默认为30秒 sentinel parallel-syncs mymaster 1 # 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。 sentinel failover-timeout mymaster 180000 # failover-timeout 可以用在以下这些方面: 1. 同一个sentinel对同一个master两次failover之间的间隔时间。 2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。 3.当想要取消一个正在进行的failover所需要的时间。 4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了。
9.1 python操作哨兵
# python操作哨兵,代码中需要单独写了,跟之前不一样了 import redis from redis.sentinel import Sentinel # 连接哨兵服务器(主机名也可以用域名) # 10.0.0.101:26379 sentinel = Sentinel([('127.0.0.1', 26379), ('127.0.0.1', 26378), ('127.0.0.1', 26377) ], socket_timeout=5) print(sentinel) # 获取主服务器地址 master = sentinel.discover_master('mymaster') print(master) # 获取从服务器地址 slave = sentinel.discover_slaves('mymaster') print(slave) ##### 读写分离 # 获取主服务器进行写入 # master = sentinel.master_for('mymaster', socket_timeout=0.5) # w_ret = master.set('foo', 'bar') # slave = sentinel.slave_for('mymaster', socket_timeout=0.5) # r_ret = slave.get('foo') # print(r_ret)
10 集群
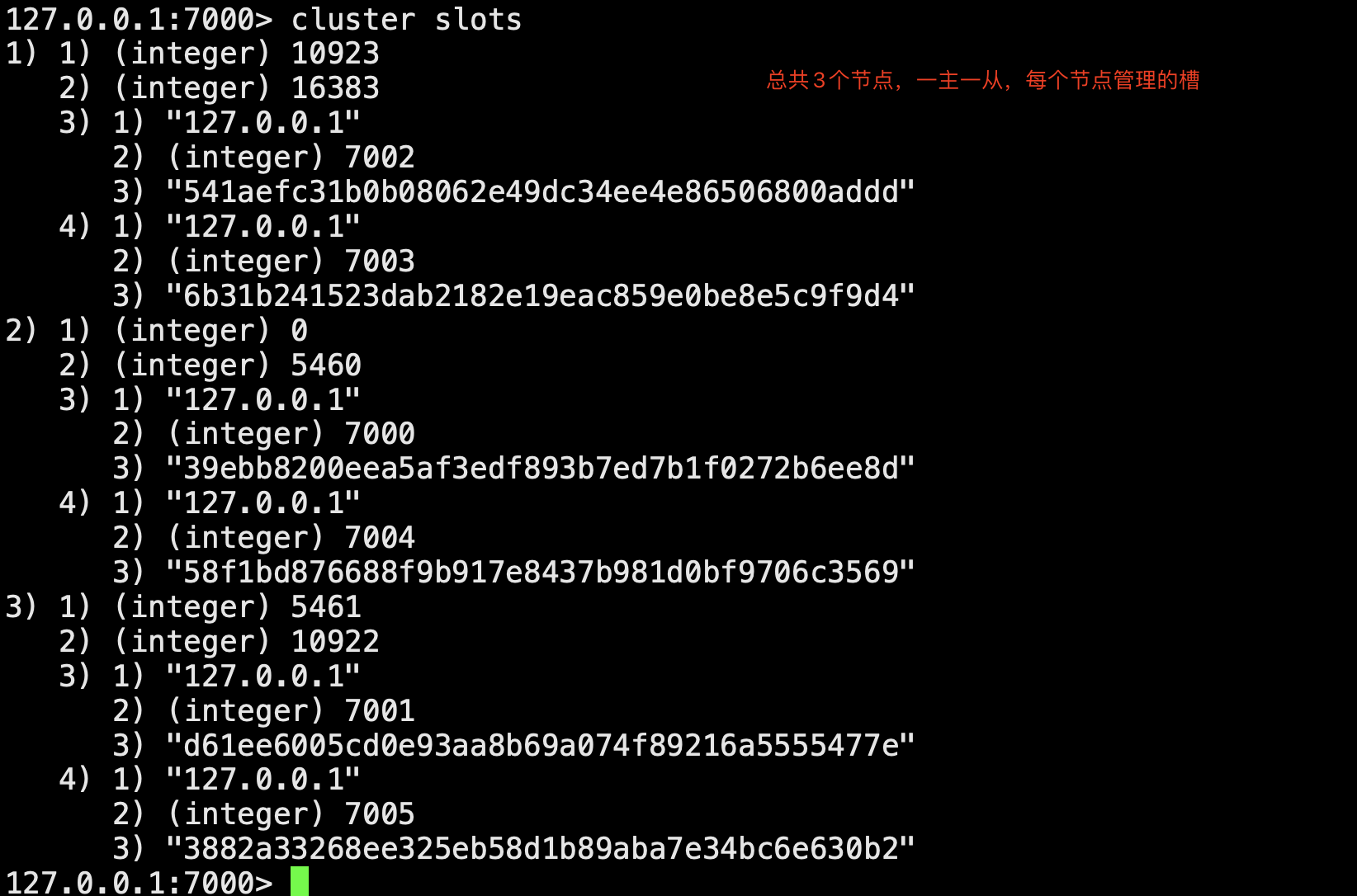
# 存在问题 1 并发量:单机redis qps为10w/s,但是我们可能需要百万级别的并发量 2 数据量:机器内存16g--256g,如果存500g数据呢? # 解决:加机器,分布式 redis cluster 在2015年的 3.0 版本加入了,满足分布式的需求 # 数据分布(分布式数据库) #假设全量的数据非常大500g,单机已经无法满足,我们需要进行分区,分到若干个子集中---》数据分片 # 分区,分片方式 - 顺序分区 -原理:100个数据分到3个节点上 1--33第一个节点;34--66第二个节点;67--100第三个节点(很多关系型数据库使用此种方式) -mysql 分库分表 - hash分区:原理:hash分区: 节点取余 ,假设3台机器, hash(key)%3,落到不同节点上 -节点取余分区 -一致性哈希分区 -虚拟槽分区 # redis使用的分区方案:-redis使用hash分区中的虚拟槽分区,总共有16384个槽 -为什么redis 有16384个槽 -一般redis集群节点数,不会超过1千多个,16384就够了 -如果槽过多,通信效率也会受影响 -综合权衡完,使用16384个槽 -原理:5个节点,把16384个槽平均分配到每个节点,客户端会把数据发送给任意一个节点,通过CRC16对key进行哈希对16383进行取余,算出当前key属于哪部分槽,属于哪个节点,
每个节点都会记录是不是负责这部分槽,如果是负责的,进行保存,如果槽不在自己范围内,redis cluster是共享消息的模式,它知道哪个节点负责哪些槽,返回结果,
让客户端找对应的节点去存服务端管理节点,槽,关系 # redis集群搭建---》流程---》了解 节点(6台机器,一主已从,3个节点),meet(每个节点需要相互感知),指派槽(16384分配给3台机器),复制(一主一从),高可用(主库挂掉,从库会顶上来)
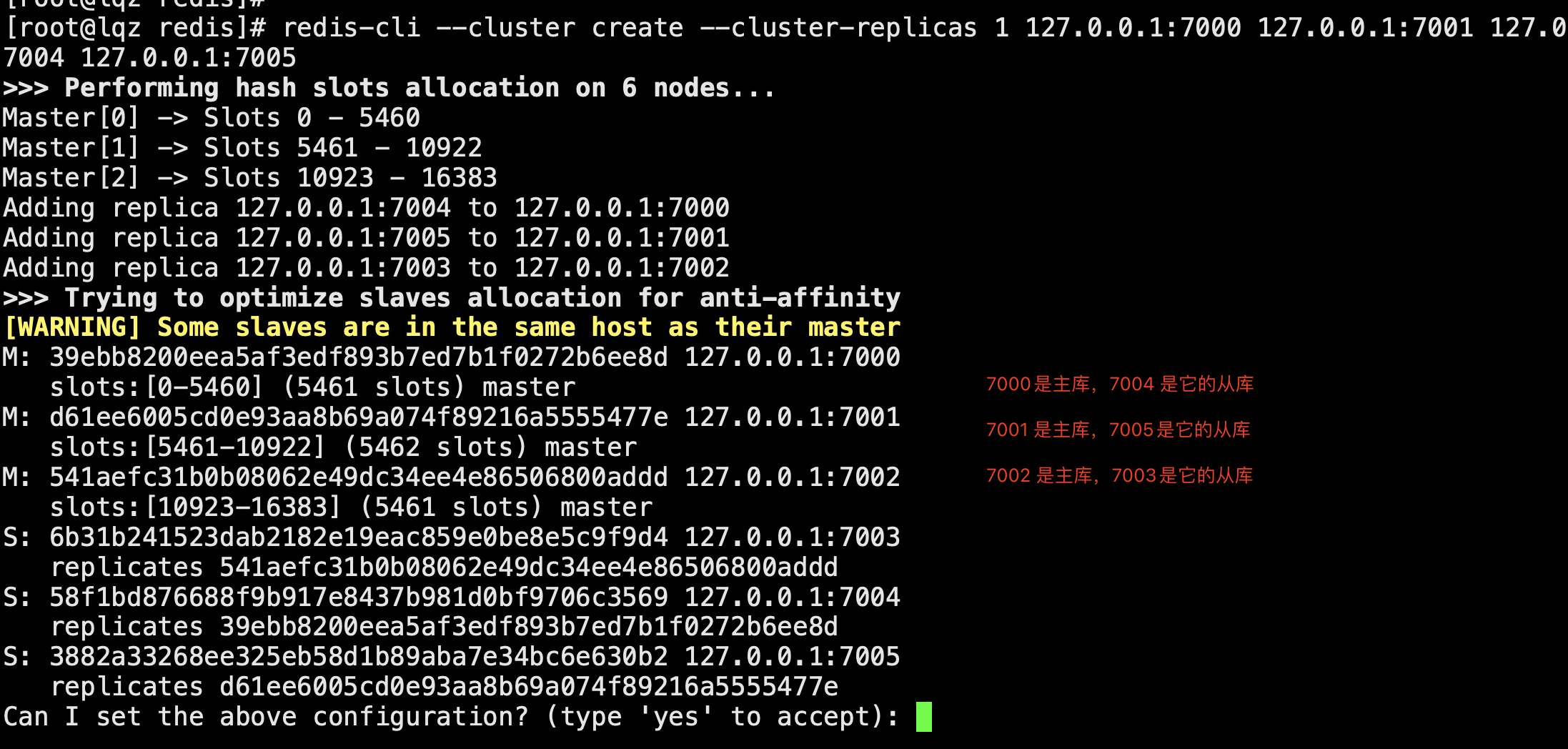
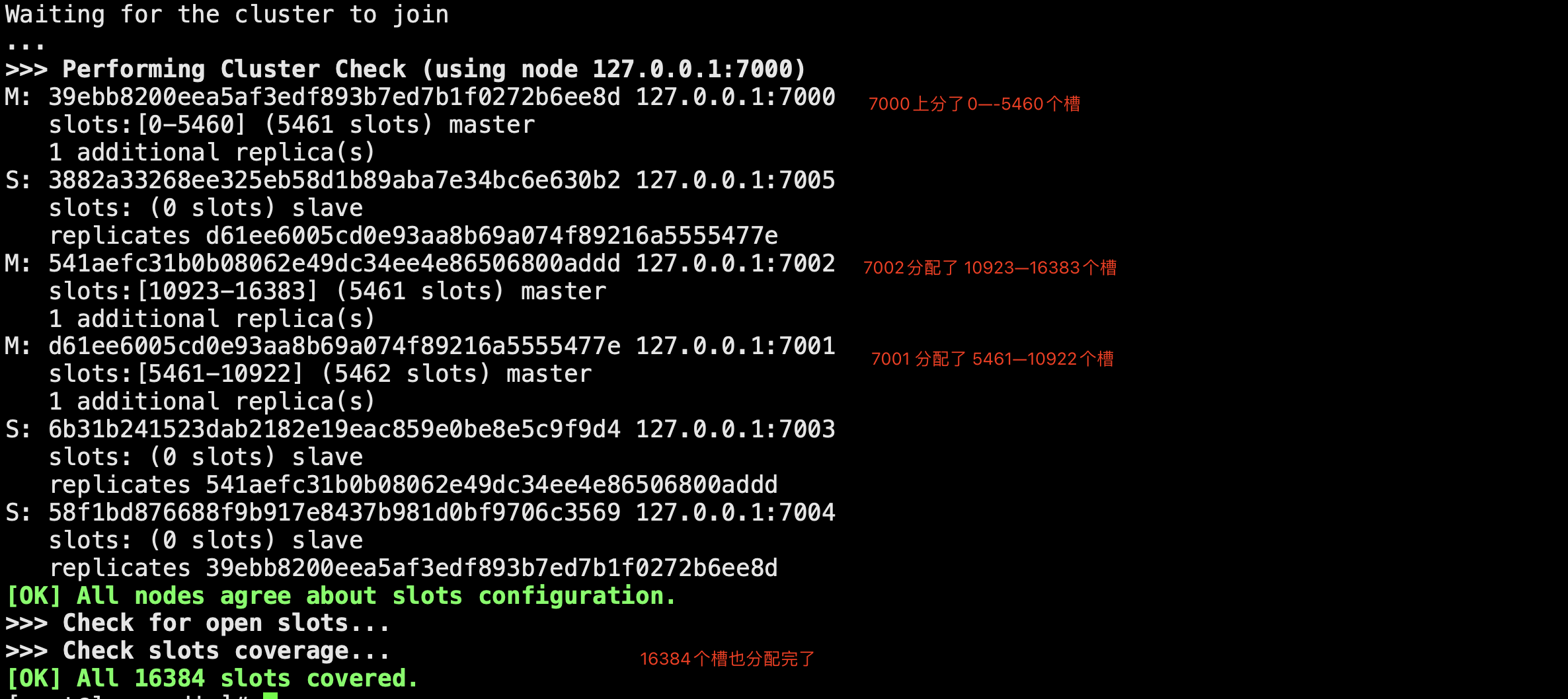
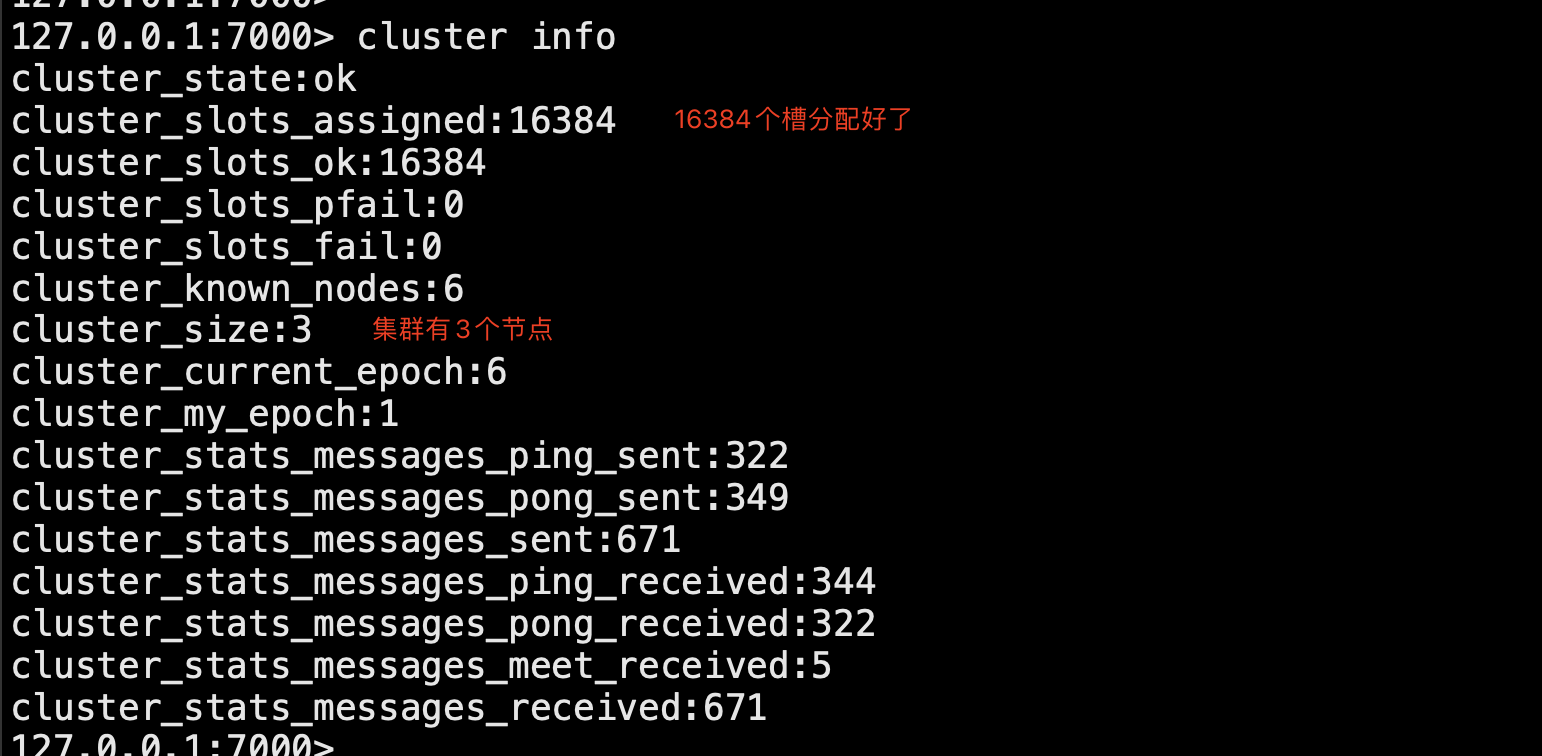
# 第一步:准备6台机器 # 配置文件解释 cluster-enabled yes # 开启cluster cluster-node-timeout 15000 # 故障转移,超时时间 15s cluster-config-file nodes-${port}.conf # 给cluster节点增加一个自己的配置文件 cluster-require-full-coverage yes #只要集群中有一个故障了,整个就不对外提供服务了,这个实际不合理,假设有50个节点,一个节点故障了,所有不提供服务了;,需要设置成no -准备6个配置文件 vim redis-7000.conf port 7000 daemonize yes dir "/root/redis/data/" logfile "7000.log" dbfilename "dump-7000.rdb" cluster-enabled yes cluster-config-file nodes-7000.conf cluster-require-full-coverage yes # 快速生成其他配置6个排位置文件 sed 's/7000/7001/g' redis-7000.conf > redis-7001.conf sed 's/7000/7002/g' redis-7000.conf > redis-7002.conf sed 's/7000/7003/g' redis-7000.conf > redis-7003.conf sed 's/7000/7004/g' redis-7000.conf > redis-7004.conf sed 's/7000/7005/g' redis-7000.conf > redis-7005.conf # 启动6台机器 redis-server ./redis-7000.conf redis-server ./redis-7001.conf redis-server ./redis-7002.conf redis-server ./redis-7003.conf redis-server ./redis-7004.conf redis-server ./redis-7005.conf ps -ef |grep redis ## 第二步:相互感知,分配主从,分配槽 # meet,分配槽,指定主从 1 的意思是,每个节点都是一主一从 ,自动组件主从 redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 yes 确定 ## 第三步:主从关系和集群关系 # 7000 主 7004从 # 7001 主 7005 从 # 7002 主 7003从 # 3个命令 cluster nodes # 看节点信息 cluster slots # 槽的信息 cluster info # 整体信息 # 链接服务的 redic-cli -c # 集群模式链接,设置获取值,如果不在当前节点,会自动转过去,并完成数据操作 #### 扩容,8台机器,4个节点的集群 -启动两台机器,加入到集群中(meet),两台机器做主从,这个节点分配槽 # 启动两台集群:一个主,一个从 -第一步启动两台机器 sed 's/7000/7006/g' redis-7000.conf > redis-7006.conf sed 's/7000/7007/g' redis-7000.conf > redis-7007.conf -第二步:启动新增的两台机器 redis-server ./redis-7006.conf redis-server ./redis-7007.conf -第三步:两台机器加入到集群中去 -这两台机器加入到机器中(add-node) redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7000 -第四步:让7007作为7006的从 redis-cli -p 7007 cluster replicate fb83d0f5c350ccf4c2e067f1b2081e236a266b15 -第五步:迁移槽:从每台机器均匀的移动一部分槽给新的机器 redis-cli --cluster reshard 127.0.0.1:7000 # 希望迁移多少个槽:4096 # 希望那个id是接收的:7006的id fb83d0f5c350ccf4c2e067f1b2081e236a266b15 # 传入source id :all # yes #### ### 集群缩容 7006管理的槽,移走,关闭节点,节点下线,先下从库,再下主 # 第一步:下线迁槽(把7006的1366个槽迁移到7000上) redis-cli --cluster reshard --cluster-from 9ab90b9d5807a84ad9ac6c57e6906f1bea37733f --cluster-to 0804be1fe7a906bd36c241c2df1c5b3005cb511b --cluster-slots 1365 127.0.0.1:7000 yes redis-cli --cluster reshard --cluster-from 9ab90b9d5807a84ad9ac6c57e6906f1bea37733f --cluster-to 9b8cc2dc1fecd2abb93da30a239bd9ed41a1f3d4 --cluster-slots 1366 127.0.0.1:7001 yes redis-cli --cluster reshard --cluster-from 9ab90b9d5807a84ad9ac6c57e6906f1bea37733f --cluster-to 8267f681a1948a2eb5ea224015702b511a578f7d --cluster-slots 1366 127.0.0.1:7002 yes #第二步:下线节点 忘记节点,关闭节点 redis-cli --cluster del-node 127.0.0.1:7000 52d8ef3460ae31825c80111a3aa1da4ad90c5509 # 先下从,再下主,因为先下主会触发故障转移 redis-cli --cluster del-node 127.0.0.1:7000 9ab90b9d5807a84ad9ac6c57e6906f1bea37733f # 第三步:关掉其中一个主,另一个从立马变成主顶上, 重启停止的主,发现变成了从


# rediscluster # pip3 install redis-py-cluster from rediscluster import RedisCluster startup_nodes = [{"host":"127.0.0.1", "port": "7000"},{"host":"127.0.0.1", "port": "7001"},{"host":"127.0.0.1", "port": "7002"}] # rc = RedisCluster(startup_nodes=startup_nodes,decode_responses=True) rc = RedisCluster(startup_nodes=startup_nodes) rc.set("foo", "bar") print(rc.get("foo"))


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)