【Disruptor】之Ringbuffer
一、Ringbuffer的概念
=>是一个环形数据队列的数据结构
=>嗯,正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer。
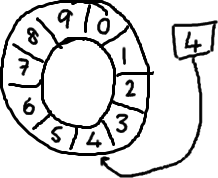
=>基本来说,ringbuffer拥有一个序号,这个序号指向数组中下一个可用的元素。(校对注:如下图右边的图片表示序号,这个序号指向数组的索引4的位置。)
=>随着你不停地填充这个buffer(可能也会有相应的读取),这个序号会一直增长,直到绕过这个环。
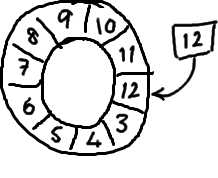
要找到数组中当前序号指向的元素,可以通过mod操作:
sequence mod array length = array index
以上面的ringbuffer为例(java的mod语法):12 % 10 = 2。很简单吧。
事实上,上图中的ringbuffer只有10个槽完全是个意外。如果槽的个数是2的N次方更有利于基于二进制的计算机进行计算。
(校对注:2的N次方换成二进制就是1000,100,10,1这样的数字, sequence & (array length-1) = array index,比如一共有8槽,3&(8-1)=3,HashMap就是用这个方式来定位数组元素的,这种方式比取模的速度更快。)
二、它为什么如此优秀?
之所以ringbuffer采用这种数据结构,是因为它在可靠消息传递方面有很好的性能。这就够了,不过它还有一些其他的优点。
首先,因为它是数组,所以要比链表快,而且有一个容易预测的访问模式。(译者注:数组内元素的内存地址的连续性存储的)。这是对CPU缓存友好的—也就是说,在硬件级别,数组中的元素是会被预加载的,因此在ringbuffer当中,cpu无需时不时去主存加载数组中的下一个元素。(校对注:因为只要一个元素被加载到缓存行,其他相邻的几个元素也会被加载进同一个缓存行)
其次,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号