【java基础】java中String的注意点
【java的内存模型】
一、Java内存模型
按照官方的说法:Java 虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配。
JVM主要管理两种类型内存:堆和非堆,堆内存(Heap Memory)是在 Java 虚拟机启动时创建,非堆内存(Non-heap Memory)是在JVM堆之外的内存。
简单来说,非堆包含方法区、JVM内部处理或优化所需的内存(如 JITCompiler,Just-in-time Compiler,即时编译后的代码缓存)、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法的代码。
Java的堆是一个运行时数据区,类的(对象从中分配空间。这些对象通过new、newarray、 anewarray和multianewarray等指令建立,它们不需要程序代码来显式的释放。堆是由垃圾回收来负责的,堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈中主要存放一些基本类型的变量数据(int, short, long, byte, float, double, boolean, char)和对象句柄(引用)。
虚拟机必须为每个被装载的类型维护一个常量池。常量池就是该类型所用到常量的一个有序集合,包括直接常量(string,integer和 floating point常量)和对其他类型,字段和方法的符号引用。
对于String常量,它的值是在常量池中的。而JVM中的常量池在内存当中是以表的形式存在的,
对于String类型,有一张固定长度的CONSTANT_String_info表用来存储文字字符串值,注意:该表只存储文字字符串值,不存储符号引
用。说到这里,对常量池中的字符串值的存储位置应该有一个比较明了的理解了。在程序执行的时候,常量池会储存在Method
Area,而不是堆中。常量池中保存着很多String对象; 并且可以被共享使用,因此它提高了效率
二、String对象的存储
请看这样两个语句:
String x = "abc"; String y = new String("abcd");

可以看出,x与y存在栈中,它们保存了相应对象的引用。第一条语句没有在堆中分配内存,而是将“abc”保存在常量池中。对于第二条语句,同样会在常量池 中有一个“abcd”的字符串,当new时,会拷贝一份该字符串存放到堆中,于是y指向了堆中的那个“abcd”字符串。
请看这样的语句
String s1="a";String s2="b";String s3=s1+s2;
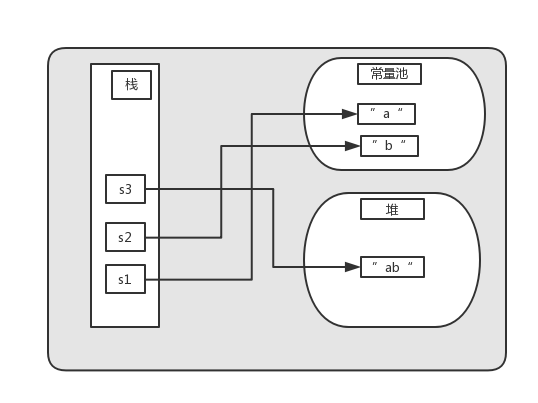
S3的创建是将常量池的"a"和"b"拷贝一分组合成一个新的字符串,在堆中创建一份对象。栈中的s3变量指向堆中的"ab"
三:测试案例


package com.sxf.test.collections; public class StringTest { public static void main(String[] args) { //test01(); //test02(); // test03(); //test04(); // test05(); test06(); } /** * s1在常量池中查找是否存在"a",结果没有,创建一个a的常量 * s2在常量池中查找是否有,结果有,则指向常量池中的"a" * "=="比较的是地址 * "equals"比较的是值 */ public static void test01(){ String s1="a"; String s2="a"; System.out.println("StringTest.test01()==>"+(s1==s2));//true System.out.println("StringTest.test01()==>"+(s1.equals(s2)));//true } /** * s3的创建:在堆内存中创建一个对象,value为"ab".栈中的s1变量指向堆中的地址。 * s4的创建:在常量池中创建"ab"常量,然后再在堆内存中创建一个对象,value为"ab"。栈中的s4变量指向堆中的地址。 * 所以s3和s4的地址是不一样的。s3和s4的value是一样的。 * * s5中去常量池中查找是否存在ab,因为s4已经在常量池中创建"ab",结果存在,所以s5指向常量池 */ public static void test02(){ String s1="a"; String s2="b"; String s3=s1+s2; String s4=new String("ab"); String s5="ab"; System.out.println("StringTest.test02()==>"+(s3==s4));//false System.out.println("StringTest.test02()==>"+(s3.equals(s4)));//true System.out.println("StringTest.test02()==>"+(s3==s5));//false System.out.println("StringTest.test02()==>"+(s3.equals(s5)));//true } /** * 两个常量的字面相加,还是保存在常量池中。 * s2的机制:常量的值在编译的时候就被确定(优化)了。 * 在这里,"a"和"1"都是常量,因此变量s2的值在编译时就可以确定。 * 这行代码编译后的效果等同于: String s2 = "abcd"; */ public static void test03(){ String s1 = "a1"; String s2 = "a" +"1"; System.out.println("StringTest.test03()===>"+(s1==s2));//true } /** * s4:栈中的变量和一个常量相加,需要在堆内存中创建一份对象 * s5:两个栈中的变量相加,需要在堆中创建一份对象。 * s4:这个s4的数值在运行时才能确定,因此产生一份对象。 * */ public static void test04(){ String s1="a1"; String s2="a"; String s3="1"; String s4=s2+"1"; String s5=s2+s3; System.out.println("StringTest.test04()===>"+(s1==s4));//false System.out.println("StringTest.test04()===>"+(s1==s5));//false System.out.println("StringTest.test04()===>"+(s4==s5));//false } /** *final修饰的是常量,所有s3在创建的时候,还是现在常量池中查找是否存在"ab",结果存在,所以共享。结果为true */ public static void test05(){ String s1 = "ab"; final String s2 = "b"; String s3 = "a" + s2; System.out.println("StringTest.test05()===>"+(s1==s3));//true } /** * final String s2 = getBB();其实与final String s2 = new String(“b”);是一样的。 * 也就是说return “b”会在堆中创建一个String对象保存”b”, * 虽然s2被定义成了final。可见并非定义为final的就保存在常量池中, * 很明显此处s2常量引用的String对象保存在堆中,因为getBB()得到的String已经保存在堆中了, * final的String引用并不会改变String已经保存在堆中这个事实。 */ public static void test06(){ String s1 = "ab"; final String s2 = getBB(); String s3 = "a" + s2; System.out.println("StringTest.test06()===>"+(s1==s3));//false } private static String getBB() { return "b"; } /** * 可能很多人对intern()这个函数不了解。JDK API文档中对intern()方法的描述是: * 返回字符串对象的规范化表示形式。 * 一个初始为空的字符串池,它由类 String 私有地维护。 * 当调用 intern 方法时,如果池已经包含一个等于此 String 对象的字符串(用 equals(Object) 方法确定),则返回池中的字符串。否则,将此 String 对象添加到池中,并返回此 String 对象的引用。 * 它遵循以下规则:对于任意两个字符串 s 和 t,当且仅当 s.equals(t) 为 true 时,s.intern() == t.intern() 才为 true。 * 所有字面值字符串和字符串赋值常量表达式都使用 intern 方法进行操作。 * 上面字符串池即为字符串常量池。明白该题结果的原因了吧。 */ private static String a = "ab"; public static void test07() { String s1 = "a"; String s2 = "b"; String s = s1 + s2; System.out.println("StringTest.test07()==>"+(s==a));//flase System.out.println("StringTest.test07()==>"+(s.intern()==a));//true } }
1.String类初始化后是不可变的(immutable)
这 一说又要说很多,大家只要知道String的实例一旦生成就不会再改变了,比如说:String str=”kv”+”ill”+” “+”ans”; 就是有4个字符串常量,首先”kv”和”ill”生成了”kvill”存在内存中,然后”kvill”又和” ” 生成 “kvill “存在内存中,最后又和生成了”kvill ans”;并把这个字符串的地址赋给了str,就是因为String的”不可变”产生了很多临时变量,这也就是为什么建议用StringBuffer的原 因了,因为StringBuffer是可改变的。
下面是一些String相关的常见问题:
String中的final用法和理解
final StringBuffer a = new StringBuffer("111");
final StringBuffer b = new StringBuffer("222");
a=b;//此句编译不通过 final StringBuffer a = new StringBuffer("111");
a.append("222");// 编译通过
可见,final只对引用的"值"(即内存地址)有效,它迫使引用只能指向初始指向的那个对象,改变它的指向会导致编译期错误。至于它所指向的对象的变化,final是不负责的。
2.代码中的字符串常量在编译的过程中收集并放在class文件的常量区中,如"123"、"123"+"456"等,含有变量的表达式不会收录,如"123"+a。
3.JVM 在加载类的时候,根据常量区中的字符串生成常量池,每个字符序列如"123"会生成一个实例放在常量池里,这个实例是不在堆里的,也不会被GC,这个实例 的value属性从源码的构造函数看应该是用new创建数组置入123的,所以按我的理解此时value存放的字符数组地址是在堆里,如果有误的话欢迎大 家指正。
4.使用String不一定创建对象
在 执行到双引号包含字符串的语句时,如String a = "123",JVM会先到常量池里查找,如果有的话返回常量池里的这个实例的引用,否则的话创建一个新实例并置入常量池里。如果是 String a = "123" + b (假设b是"456"),前半部分"123"还是走常量池的路线,但是这个+操作符其实是转换成[SringBuffer].Appad()来实现的,所以最终a得到是一个新的实例引用,而且a的value存放的是一个新申请的字符数组内存空间的地址(存放着"123456"),而此时"123456"在常量池中是未必存在的。
要注意: 我们在使用诸如String str = "abc";的格式定义类时,总是想当然地认为,创建了String类的对象str。担心陷阱!对象可能并没有被创建!而可能只是指向一个先前已经创建的对象。只有通过new()方法才能保证每次都创建一个新的对象
5.使用new String,一定创建对象
在执行String a = new String("123")的时候,首先走常量池的路线取到一个实例的引用,然后在堆上创建一个新的String实例,走以下构造函数给value属性赋值,然后把实例引用赋值给a:

public String(String original) {
int size = original.count;
char[] originalValue = original.value;
char[] v;
if (originalValue.length > size) {
// The array representing the String is bigger than the new
// String itself. Perhaps this constructor is being called
// in order to trim the baggage, so make a copy of the array.
int off = original.offset;
v = Arrays.copyOfRange(originalValue, off, off+size);
} else {
// The array representing the String is the same
// size as the String, so no point in making a copy.
v = originalValue;
}
this.offset = 0;
this.count = size;
this.value = v;
}
从中我们可以看到,虽然是新创建了一个String的实例,但是value是等于常量池中的实例的value,即是说没有new一个新的字符数组来存放"123"。
如果是String a = new String("123"+b)的情况,首先看回第4点,"123"+b得到一个实例后,再按上面的构造函数执行。
6.String.intern()
String 对象的实例调用intern方法后,可以让JVM检查常量池,如果没有实例的value属性对应的字符串序列比如"123"(注意是检查字符串序列而不是 检查实例本身),就将本实例放入常量池,如果有当前实例的value属性对应的字符串序列"123"在常量池中存在,则返回常量池中"123"对应的实例 的引用而不是当前实例的引用,即使当前实例的value也是"123"。
public native String intern();
存 在于.class文件中的常量池,在运行期被JVM装载,并且可以扩充。String的 intern()方法就是扩充常量池的 一个方法;当一个String实例str调用intern()方法时,Java 查找常量池中 是否有相同Unicode的字符串常量,如果有,则返回其的引用,如果没有,则在常 量池中增加一个Unicode等于str的字符串并返回它的引用;看示例就清楚了
public static void main(String[] args) {
String s0 = "kvill";
String s1 = new String("kvill");
String s2 = new String("kvill");
System.out.println( s0 == s1 ); //false
System.out.println( "**********" );
s1.intern(); //虽然执行了s1.intern(),但它的返回值没有赋给s1
s2 = s2.intern(); //把常量池中"kvill"的引用赋给s2
System.out.println( s0 == s1); //flase
System.out.println( s0 == s1.intern() ); //true//说明s1.intern()返回的是常量池中"kvill"的引用
System.out.println( s0 == s2 ); //true
}
最 后我再破除一个错误的理解:有人说,“使用 String.intern() 方法则可以将一个 String 类的保存到一个全局 String 表中 ,如果具有相同值的 Unicode 字符串已经在这个表中,那么该方法返回表中已有字符串的地址,如果在表中没有相同值的字符串,则将自己的地址注册到表中”如果我把他说的这个全局的 String 表理解为常量池的话,他的最后一句话,”如果在表中没有相同值的字符串,则将自己的地址注册到表中”是错的:
public static void main(String[] args) {
String s1 = new String("kvill");
String s2 = s1.intern();
System.out.println( s1 == s1.intern() ); //false
System.out.println( s1 + " " + s2 ); //kvill kvill
System.out.println( s2 == s1.intern() ); //true
}
在这个类中我们没有声名一个”kvill”常量,所以常量池中一开始是没有”kvill”的,当我们调用s1.intern()后就在常量池中新添加了一 个”kvill”常量,原来的不在常量池中的”kvill”仍然存在,也就不是“将自己的地址注册到常量池中”了。
s1==s1.intern() 为false说明原来的”kvill”仍然存在;s2现在为常量池中”kvill”的地址,所以有s2==s1.intern()为true。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号