【java多线程】jdk的线程池
一、JDK的线程池的核心参数
- int corePoolSize :线程池中的核心线程数
- int maximumPoolSize :线程池中的最大线程数
- long keepAliveTime :除核心线程数以外,其他空闲线程最大存活的时间
- TimeUnit unit :存活时间的单位
- BlockingQueue<Runnable> workQueue :存放任务的队列
- ThreadFactory threadFactory:线程池生产线程的工厂类
- RejectedExecutionHandler handler:当队列已满线程池拒绝任务的策略
- boolean allowCoreThreadTimeOut :是否允许核心线程超时(这个为true,当核心线程空闲到keepAliveTime后,会被回收。 为false时,核心线程空闲会一直阻塞在队列上等待新任务)
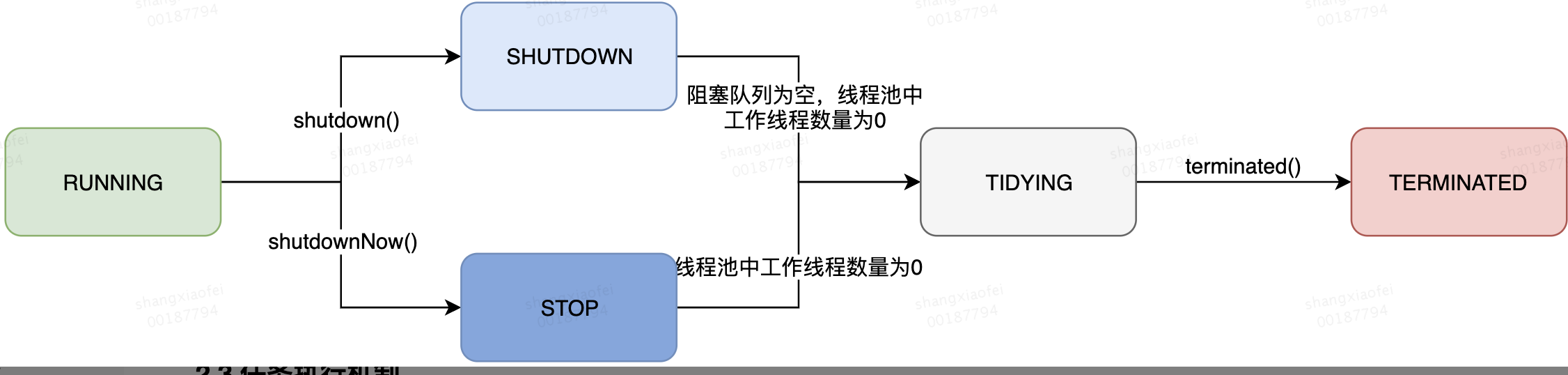
二、JDK的线程池的状态
|
运行状态 |
状态描述 |
线城池状态的表示 |
|---|---|---|
|
RUNNING |
能接受新提交的任务,并且也能处理阻塞队列中的任务; |
RUNNING = -1 << 29 |
|
SHUTDOWN |
关闭状态,不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务。 |
SHUTDOWN = 0 << 29 |
|
STOP |
不能接受新任务,也不处理队列中的任务,会中断正在处理任务的线程。 |
STOP = 1 << 29 |
|
TIDYING |
如果所有的任务都已终止了,workerCount (有效线程数) 为0 |
TIDYING = 2 << 29 |
|
TERMINATED |
在terminated() 方法执行完后进入该状态 |
TERMINATED = 3 << 29 |
RUNNING -1<<29==>11100000 00000000 00000000 00000000
SHUTDOWN 0<<29==>00000000 00000000 00000000 00000000
STOP 1<<29 ==>00100000 00000000 00000000 00000000
TIDYING 2<<29 ==>01000000 00000000 00000000 00000000
TERMINATED 3<<29 ==>01100000 00000000 00000000 00000000
CAPACITY (1<<29)-1 ==>00011111 11111111 11111111 11111111
//这个代表线程的控制器:int类型为32位。 其中高3位表示线程池的状态,低29位表示线城池中的线程数量。


private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
//计算线城池中的数量:ctl & CAPACITY 也就意味着:线程池中线程的最大
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int runStateOf(int c) { return c & ~CAPACITY; } //计算当前运行状态 private static int workerCountOf(int c) { return c & CAPACITY; } //计算当前线程数量 private static int ctlOf(int rs, int wc) { return rs | wc; } //通过状态和线程数生成ctl
三、JDK的线程池的调度机制
任务调度是线程池的主要入口,当用户提交了一个任务,接下来这个任务将如何执行都是由这个阶段决定的。了解这部分就相当于了解了线程池的核心运行机制。
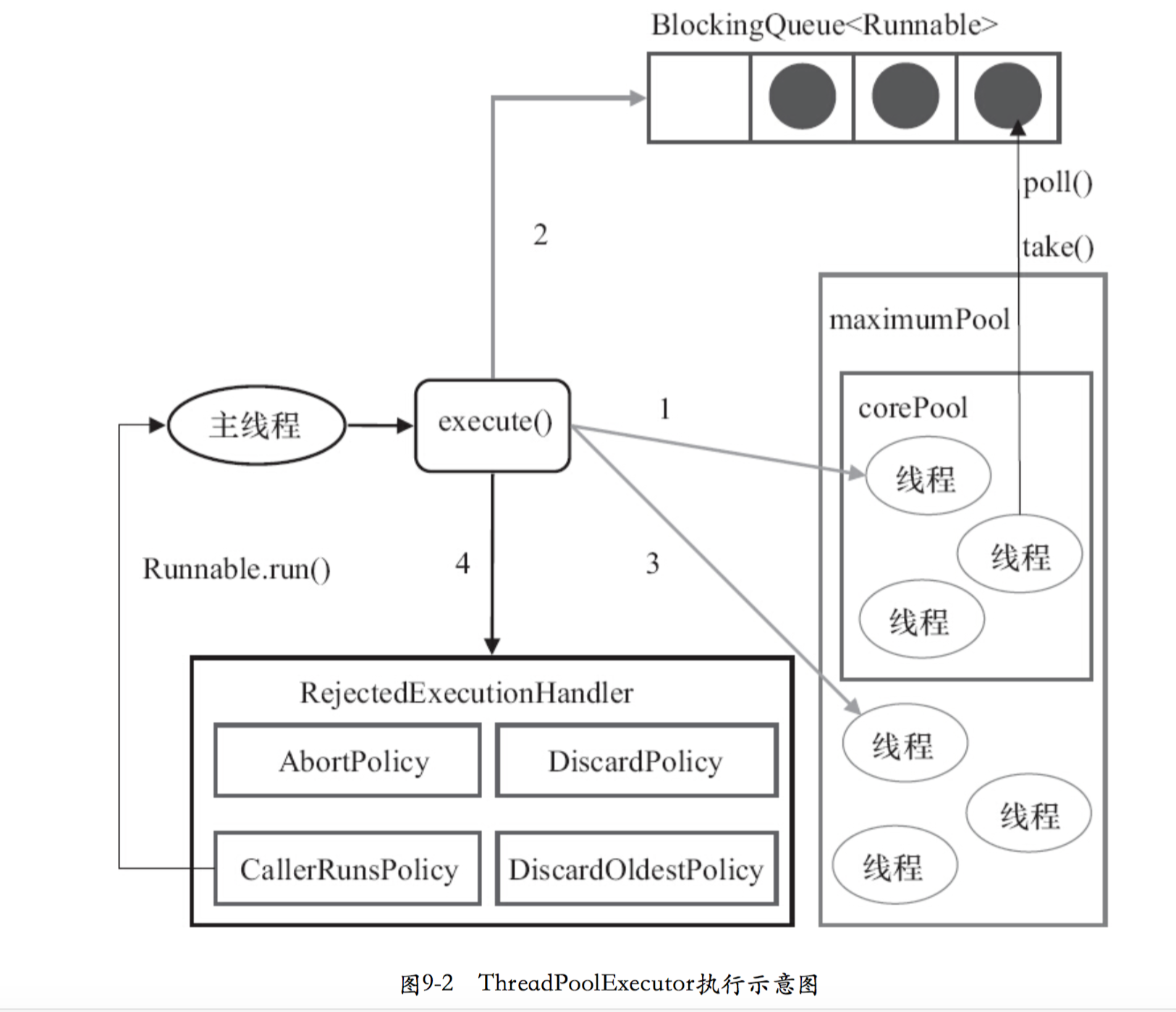
首先所有任务的调度都是由execute方法完成的,这部分完成的工作是,检查现在线程池的运行状态、运行线程数、运行策略,决定接下来执行的流程,是直接申请线程执行或是缓冲到队列中执行亦或是直接拒绝该任务,其执行过程如下:
-
首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
-
如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
-
如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
-
如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
-
如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
四、JDK的线程池的任务缓存(阻塞队列成员)
|
名称 |
描述 |
|---|---|
|
ArrayBlockingQueue |
一个用数组实现的有界阻塞队列,此队列按照先进先出(FIFO)的原则对元素进行排序。支持公平锁和非公平锁。 |
|
LinkedBlockingQueue |
一个由链表结构组成的有界队列,此队列按照先进先出(FIFO)的原则对元素进行排序。此队列的默认长度为Integer.MAX_VALUE,所以默认创建的该队列有容量危险。 |
|
PriorityBlockingQueue |
一个支持线程优先级排序的无界队列,默认自然序进行排序,也可以自定义实现compareTo()方法来指定元素排序规则,不能保证同优先级元素的顺序。 |
|
DelayQueue |
一个实现PriorityBlockingQueue实现延迟获取的无界队列,在创建元素时,可以指定多久才能从队列中获取当前元素。只有延时期满后才能从队列中获取元素。 |
|
SynchronousQueue |
一个不存储元素的阻塞队列,每一个put操作必须等待take操作,否则不能添加元素。支持公平锁和非公平锁。SynchronousQueue的一个使用场景是在线程池里。Executors.newCachedThreadPool()就使用了SynchronousQueue,这个线程池根据需要(新任务到来时)创建新的线程,如果有空闲线程则会重复使用,线程空闲了60秒后会被回收。 |
|
LinkedTransferQueue |
一个由链表结构组成的无界阻塞队列,相当于其它队列,LinkedTransferQueue队列多了transfer和tryTransfer方法。 |
|
LinkedBlockingDeque |
一个由链表结构组成的双向阻塞队列。队列头部和尾部都可以添加和移除元素,多线程并发时,可以将锁的竞争最多降到一半。 |
五、JDK的线程池的拒绝策略
接口:java.util.concurrent.RejectedExecutionHandler
用户也可以实现该接口,自定义拒绝策略。
|
名称 |
描述 |
|---|---|
|
ThreadPoolExecutor.AbortPolicy |
丢弃任务并抛出RejectedExecutionException异常。 这是线程池默认的拒绝策略,在任务不能再提交的时候,抛出异常,及时反馈程序运行状态。如果是比较关键的业务,推荐使用此拒绝策略,这样子在系统不能承载更大的并发量的时候,能够及时的通过异常发现。 |
|
ThreadPoolExecutor.DiscardPolicy |
丢弃任务,但是不抛出异常。 使用此策略,可能会使我们无法发现系统的异常状态。建议是一些无关紧要的业务采用此策略。 |
|
ThreadPoolExecutor.DiscardOldestPolicy |
丢弃队列最前面的任务,然后重新提交被拒绝的任务。是否要采用此种拒绝策略,还得根据实际业务是否允许丢弃老任务来认真衡量。 |
|
ThreadPoolExecutor.CallerRunsPolicy |
由调用线程(提交任务的线程)处理该任务。这种情况是需要让所有任务都执行完毕,那么就适合大量计算的任务类型去执行,多线程仅仅是增大吞吐量的手段,最终必须要让每个任务都执行完毕。 |
六、线程池中woker线程的管理
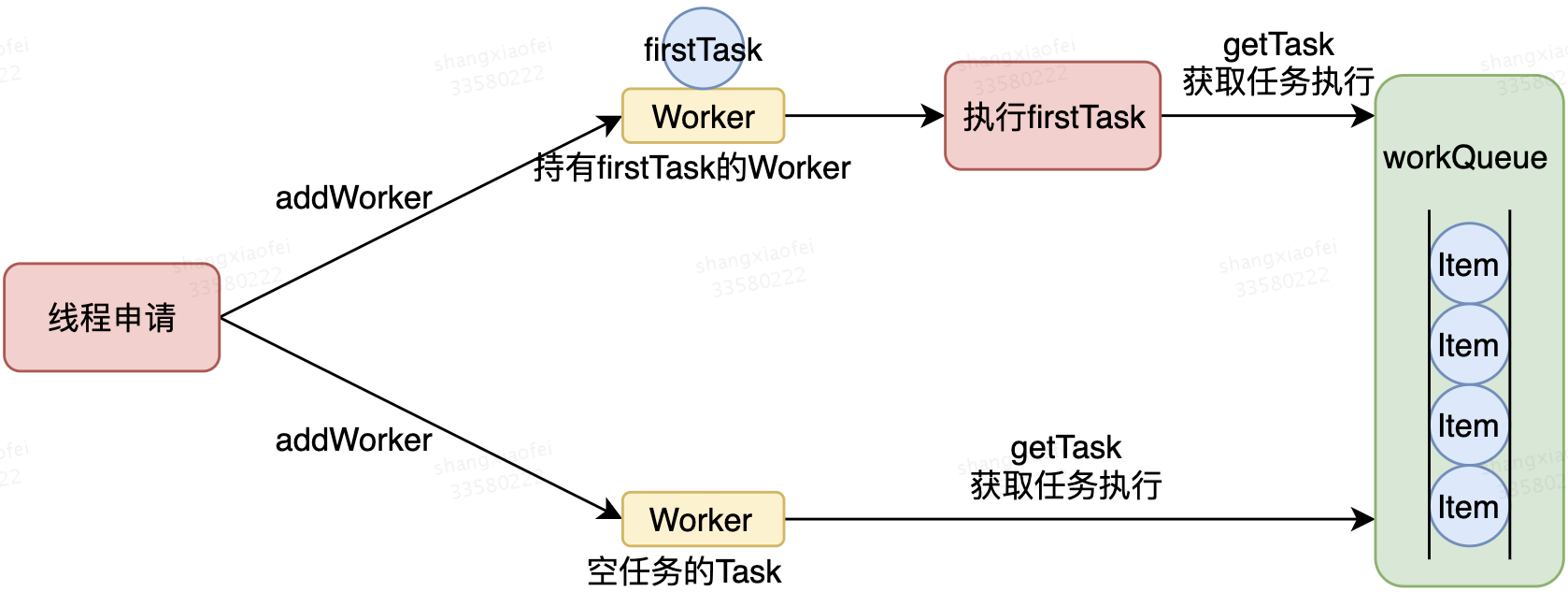
线程池为了掌握线程的状态维护线程的生命周期,设计了线程池内的工作线程Worker。我们来看一下它的部分代码:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable { /** * This class will never be serialized, but we provide a * serialVersionUID to suppress a javac warning. */ private static final long serialVersionUID = 6138294804551838833L; /** Thread this worker is running in. Null if factory fails. */ final Thread thread; /** Initial task to run. Possibly null. */ Runnable firstTask; /** Per-thread task counter */ volatile long completedTasks; /** * Creates with given first task and thread from ThreadFactory. * @param firstTask the first task (null if none) */ Worker(Runnable firstTask) { setState(-1); // inhibit interrupts until runWorker this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this); } /** Delegates main run loop to outer runWorker */ public void run() { runWorker(this); } }
Worker这个工作线程,实现了Runnable接口,并持有一个线程thread,一个初始化的任务firstTask。thread是在调用构造方法时通过ThreadFactory来创建的线程,可以用来执行任务;firstTask用它来保存传入的第一个任务,这个任务可以有也可以为null。如果这个值是非空的,那么线程就会在启动初期立即执行这个任务,也就对应核心线程创建时的情况,如果这个值是null,那么也就是需要创建一个线程去执行任务列表(workQueue)中的任务,也就是非核心线程的创建。
Worker执行任务的模型如下图所示:
线程池需要管理线程的生命周期,需要在线程长时间不运行的时候进行回收。线程池使用一张hashset表去持有线程的引用,这样可以通过添加移除引用这样的操作来控制线程的生命周期。这个时候重要的就是如何判断线程是否正在运行。
Worker是通过继承AQS 同步管理器,使用其独占锁特性来实现的这个功能。没有使用可重入锁ReentrantLock,而是使用独占锁AQS。为的就是利用AQS不可重入的特性去反应线程现在的执行状态。
-
lock方法一旦获取了独占锁,表示当前线程正在执行任务中;
-
如果正在执行任务,则不应该中断线程;
-
如果该线程现在不是独占锁的状态,也就是空闲的状态,说明它没有在处理任务,这时可以对该线程进行中断;
-
线程池在执行shutdown方法或tryTerminate方法时会调用interruptIdleWorkers方法来中断空闲的线程,interruptIdleWorkers方法会使用tryLock方法来判断线程池中的线程是否是空闲状态;如果线程是空闲状态则可以安全回收。
Worker线程工作机制
1、woker的工作流程
- woker线程会循环从阻塞队列中获取任务。
- 当线程数大于核心线程,则woker从队列获取任务是按超时方式获取:超时时间为线程允许存活的时间(超时后线程被回收)。
- 当线程数小于核心线程数,则woker按永久阻塞的方式获取任务
2、线程被回收
- 当woker线程的锁状态是无锁的时候,才允许回收。woker线程回收自己,run方法执行结束,从线程池的hashset表中移除。
- 线程被回收分两种情况:突然被回收(线程任务执行抛异常)和正常回收(1、队列中无任务,线程存活时间到期 2、线程被中断)。
- woker突然回收,且线程池状态为运行状态:当前线程被回收,则会重新向线程池中添加一个新线程。
- woker正常回收,存活时间到达或线程被中断,且线程池状态为运行状态:会判断当前线程池中的线程数量是否小于核心线程数。如果小于则重新向线程池中新增一个worker
七、调度线程池
八、线程池中线程数的大小计算方式
线程池核心的问题就在于:线程池的参数并不好配置,线程池最关键的构造参数在于corePoolSize、maximumPoolSize,workQueue三个参数的设置,它们最大程度的决定了线程池的任务分配和线程分配策略。然而这三个参数并不好配,一方面线程池的运行机制不是很好理解,配置合理需要强依赖开发人员的个人经验和知识,另一方面,线程池执行的情况和任务类型相关性较大,IO密集型和CPU密集型的任务运行起来的情况差异非常大,这导致业界并没有一些成熟的经验策略帮助开发人员参考,下面罗列了几个业界线程池参数配置方案:
|
方案 |
问题 | |
|---|---|---|
| 1 |
cup的个数(Ncpu)=当前机器的cpu核数(number of CPUs) cup的利用率(Rcpu)=目标cpu的利用率(0<= 利用率<=1) cpu的等待时间和计算时间百分比(W/C)=cpu的等待时间/cpu的计算时间
保持处理器的理想利用率的最佳池大小是 Nthreads=Ncpu*Rcpu*(1+W/C)
|
出自《Java并发编程实践》 该方案偏理论化。首先,线程计算的时间和等待的时间要如何确定呢?这个在实际开发中很难得到确切的值。另外计算出来的线程个数逼近线程实体的个数,Java线程池可以利用线程切换的方式最大程度利用CPU核数,这样计算出来的结果是非常偏离业务场景的
任务类型:cpu密集型任务,则线程数=Ncpu +1 任务类型:I/O密集型任务,则线程数= (W/C+1)* Ncpu |
| 2 |
核心线程数=2*cpu的个数 最大线程数=25*cpu的个数 |
没有考虑应用中往往使用多个线程池的情况,统一的配置明显不符合多样的业务场景。 |
| 3 |
核心线程数=Tps*time 最大线程数=tps*time*(1.7-2) |
这种计算方式,考虑到了业务场景,但是该模型是在假定流量平均分布得出的。业务场景的流量往往是随机的,这样不符合真实情况。 |
调研了以上业界方案后,我们并没有得出通用的线程池计算方式,这样就导致了下面两个问题:
-
程序开发期难以敲定合适的线程池参数配置;
-
程序运行期难以更改线程池参数,需要重新修改程序再重新上线,投入成本巨大;
九、二进制的原码,反码,补码是什么意思
什么叫补码呢?这得从原码,反码说起。
原码:一个整数,按照绝对值大小转换成的二进制数,称为原码。
比如 00000000 00000000 00000000 00000101 是 5的 原码。
反码:将二进制数按位取反,所得的新二进制数称为原二进制数的反码。
取反操作指:原为1,得0;原为0,得1。(1变0; 0变1)
比如:将00000000 00000000 00000000 00000101每一位取反,得11111111 11111111 11111111 11111010。
称:11111111 11111111 11111111 11111010 是 00000000 00000000 00000000 00000101 的反码。
反码是相互的,所以也可称:
11111111 11111111 11111111 11111010 和 00000000 00000000 00000000 00000101 互为反码。
补码:反码加1称为补码。
也就是说,要得到一个数的补码,先得到反码,然后将反码加上1,所得数称为补码。
比如:00000000 00000000 00000000 00000101 的反码是:11111111 11111111 11111111 11111010。
那么,补码为:
11111111 11111111 11111111 11111010 + 1 = 11111111 11111111 11111111 11111011
所以,-5 在计算机中表达为:11111111 11111111 11111111 11111011。转换为十六进制:0xFFFFFFFB。
再举一例,我们来看整数-1在计算机中如何表示。
假设这也是一个int类型,那么:
1、先取1的原码:00000000 00000000 00000000 00000001
2、得反码: 11111111 11111111 11111111 11111110
3、得补码: 11111111 11111111 11111111 11111111

 浙公网安备 33010602011771号
浙公网安备 33010602011771号