【算法】缓存FIFO,LFU,LRU
一、FIFO算法
FIFO(First in First out),先进先出。其实在操作系统的设计理念中很多地方都利用到了先进先出的思想,比如作业调度(先来先服务),为什么这个原则在很多地方都会用到呢?因为这个原则简单、且符合人们的惯性思维,具备公平性,并且实现起来简单,直接使用数据结构中的队列即可实现。
在FIFO Cache设计中,核心原则就是:如果一个数据最先进入缓存中,则应该最早淘汰掉。也就是说,当缓存满的时候,应当把最先进入缓存的数据给淘汰掉。在FIFO Cache中应该支持以下操作;
get(key):如果Cache中存在该key,则返回对应的value值,否则,返回-1;
set(key,value):如果Cache中存在该key,则重置value值;如果不存在该key,则将该key插入到到Cache中,若Cache已满,则淘汰最早进入Cache的数据。
举个例子:假如Cache大小为3,访问数据序列为set(1,1),set(2,2),set(3,3),set(4,4),get(2),set(5,5)
则Cache中的数据变化为:
(1,1) set(1,1)
(1,1) (2,2) set(2,2)
(1,1) (2,2) (3,3) set(3,3)
(2,2) (3,3) (4,4) set(4,4)
(2,2) (3,3) (4,4) get(2)
(3,3) (4,4) (5,5) set(5,5)
那么利用什么数据结构来实现呢?
下面提供一种实现思路:
利用一个双向链表保存数据,当来了新的数据之后便添加到链表末尾,如果Cache存满数据,则把链表头部数据删除,然后把新的数据添加到链表末尾。在访问数据的时候,如果在Cache中存在该数据的话,则返回对应的value值;否则返回-1。如果想提高访问效率,可以利用hashmap来保存每个key在链表中对应的位置。
二、LFU算法
LFU(Least Frequently Used)最近最少使用算法。它是基于“如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小”的思路。
注意LFU和LRU算法的不同之处,LRU的淘汰规则是基于访问时间,而LFU是基于访问次数的。举个简单的例子:
假设缓存大小为3,数据访问序列为set(2,2),set(1,1),get(2),get(1),get(2),set(3,3),set(4,4),
则在set(4,4)时对于LFU算法应该淘汰(3,3),而LRU应该淘汰(1,1)。
那么LFU Cache应该支持的操作为:
get(key):如果Cache中存在该key,则返回对应的value值,否则,返回-1;
set(key,value):如果Cache中存在该key,则重置value值;如果不存在该key,则将该key插入到到Cache中,若Cache已满,则淘汰最少访问的数据。
为了能够淘汰最少使用的数据,因此LFU算法最简单的一种设计思路就是 利用一个数组存储 数据项,用hashmap存储每个数据项在数组中对应的位置,然后为每个数据项设计一个访问频次,当数据项被命中时,访问频次自增,在淘汰的时候淘汰访问频次最少的数据。这样一来的话,在插入数据和访问数据的时候都能达到O(1)的时间复杂度,在淘汰数据的时候,通过选择算法得到应该淘汰的数据项在数组中的索引,并将该索引位置的内容替换为新来的数据内容即可,这样的话,淘汰数据的操作时间复杂度为O(n)。
另外还有一种实现思路就是利用 小顶堆+hashmap,小顶堆插入、删除操作都能达到O(logn)时间复杂度,因此效率相比第一种实现方法更加高效。
如果哪位朋友有更高效的实现方式(比如O(1)时间复杂度),不妨探讨一下,不胜感激。
三、LRU算法
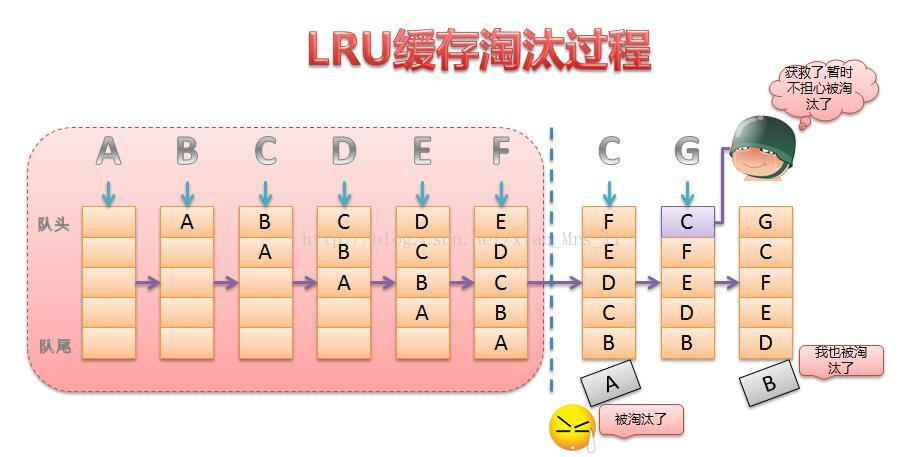
- 题目大意:为LRU Cache设计一个数据结构,它支持两个操作:
1)get(key):如果key在cache中,则返回对应的value值,否则返回-1
2)set(key,value):如果key不在cache中,则将该(key,value)插入cache中(注意,如果cache已满,则必须把最近最久未使用的元素从cache中删除);如果key在cache中,则重置value的值。
- 解题思路:题目让设计一个LRU Cache,即根据LRU算法设计一个缓存。在这之前需要弄清楚LRU算法的核心思想,LRU全称是Least
Recently Used,即最近最久未使用的意思。在操作系统的内存管理中,有一类很重要的算法就是内存页面置换算法(包括FIFO,LRU,LFU等几种常见页面置换算法)。事实上,Cache算法和内存页面置换算法的核心思想是一样的:都是在给定一个限定大小的空间的前提下,设计一个原则如何来更新和访问其中的元素。下面说一下LRU算法的核心思想,LRU算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
而用什么数据结构来实现LRU算法呢?可能大多数人都会想到:用一个数组来存储数据,给每一个数据项标记一个访问时间戳,每次插入新数据项的时候,先把数组中存在的数据项的时间戳自增,并将新数据项的时间戳置为0并插入到数组中。每次访问数组中的数据项的时候,将被访问的数据项的时间戳置为0。当数组空间已满时,将时间戳最大的数据项淘汰。
这种实现思路很简单,但是有什么缺陷呢?需要不停地维护数据项的访问时间戳,另外,在插入数据、删除数据以及访问数据时,时间复杂度都是O(n)。
那么有没有更好的实现办法呢?
那就是利用链表和hashmap。当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1。这样一来在链表尾部的节点就是最近最久未访问的数据项。
总结一下:根据题目的要求,LRU Cache具备的操作:
1)set(key,value):如果key在hashmap中存在,则先重置对应的value值,然后获取对应的节点cur,将cur节点从链表删除,并移动到链表的头部;若果key在hashmap不存在,则新建一个节点,并将节点放到链表的头部。当Cache存满的时候,将链表最后一个节点删除即可。
2)get(key):如果key在hashmap中存在,则把对应的节点放到链表头部,并返回对应的value值;如果不存在,则返回-1。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号