【领域驱动设计】一些技术建模的思想和设计方法论
一、限定设计
【建模技术】:限定
【价值】:
- 解决的还是模型和需求的一致性问题。我们之前说过,模型驱动设计还非常强调实现和模型要保持一致,也就是模型中的改变总能体现在代码和数据库设计里。
【案例】:
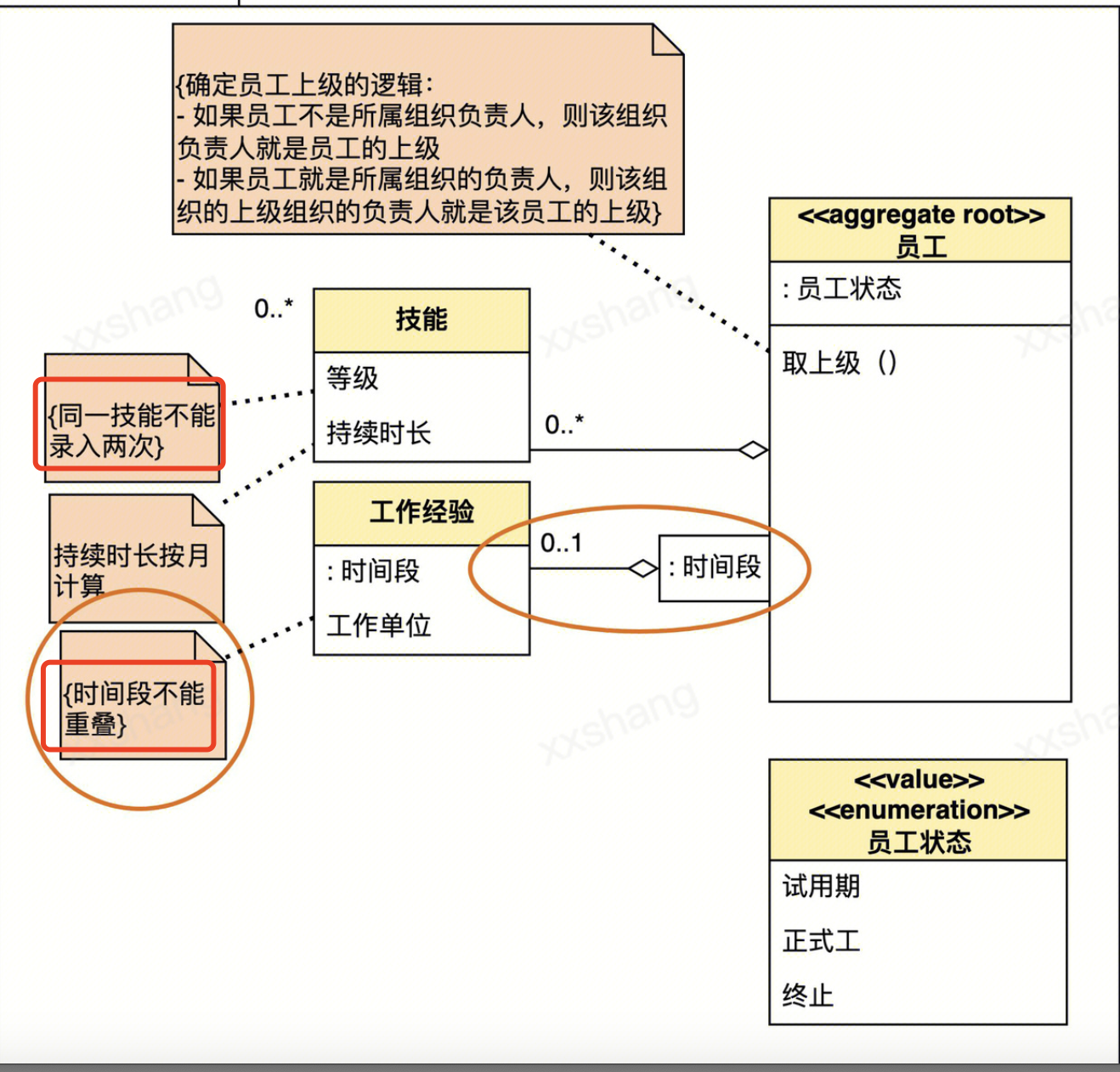
- 员工和工作经验之间有一个一对多关联。现在,在员工那一端加了一个小方框,里面写了“: 时间段”,而另一端的多重性,由原来的“0..*”神奇地变成了“0..1”。
- 这种方式所表达的意思是说,对于一个员工而言,任何一个时间段,要么没有工作经验,要么有一条工作经验,但不能有多条工作经验。换句话说,总体上看,一个员工可以有多条工作经验,但限定在一个时间段的话,那么最多就只能有一条工作经验了。
【实现方案】:
- 代码层面:基于Map来实现约束规则
- 存储层面:基于数据库的唯一索引来实现规则约束
二、泛化设计
【概念】
- 领域建模层面的泛化,大体上相当于面向对象设计中的继承和多态。
- 如果你学习过“设计模式”的话,还记得刚开始的“痛苦”吗?其实,整本《设计模式》,无非是教你怎么灵活运用多态罢了。
- 而在领域建模层面,与《设计模式》对应的就是《分析模式》。整本《分析模式》也无非是教你怎么成为使用泛化的高手。
【说明】
- 假定 C 是父类,A 和 B 是它的子类,那么对应到自然语言,可以有四种说法。
-
- 第一种:A 和 B 统称为 C,例如,甜粽子和咸粽子统称为粽子。
- 第二种:C 可以分成 A 和 B 两类,例如,粽子可以分成甜粽子和咸粽子两类。
- 第三种:一个 A 是一个 C,一个 B 也是一个 C,例如,一个甜粽子是一个粽子,一个咸粽子也是一个粽子。
- 第四种:A 和 B 具有共性,表示共性的概念称为 C,例如,甜粽子和咸粽子具有共性,表示共性的概念称为粽子。
这四种说法表面上不同,实际上表达了完全相同的含义,都可以用同样的泛化关系来表示。
在建模的抽象过程中,我们还经常遇到隐式概念的显式化,从而引入新的词汇,丰富了统一语言,也深化了对领域知识的理解。
- 在建模的抽象过程中,我们还经常遇到隐式概念的显式化,从而引入新的词汇,丰富了统一语言,也深化了对领域知识的理解。
【案例说明】
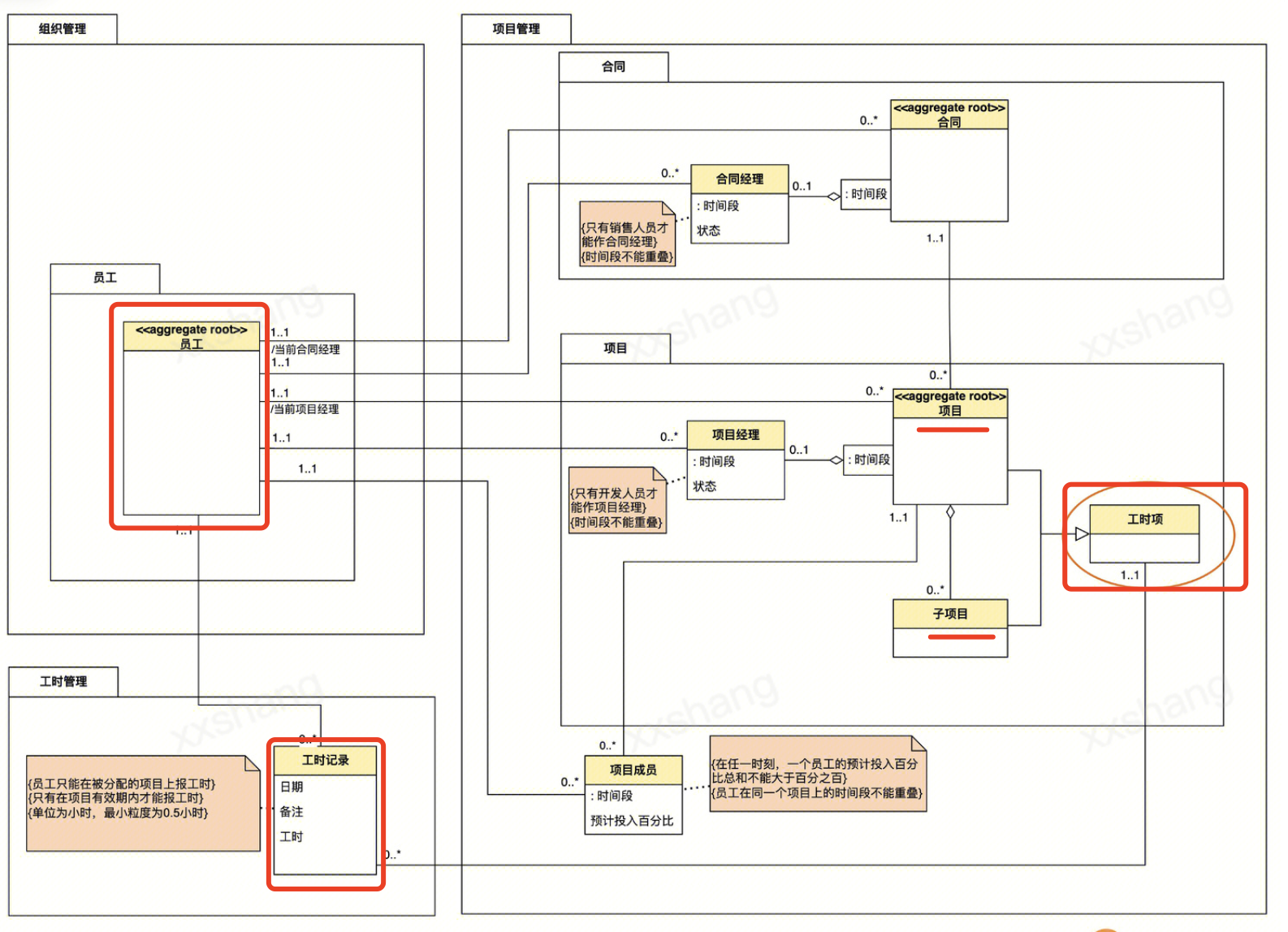
员工上报工时记录,可以上报总项目的工时记录,也可以上报子项目工时记录,也可以上报一个和项目无关的工时记录。
随着项目复杂度越来越高,引入了新的业务规则,需要进行进一步抽象。
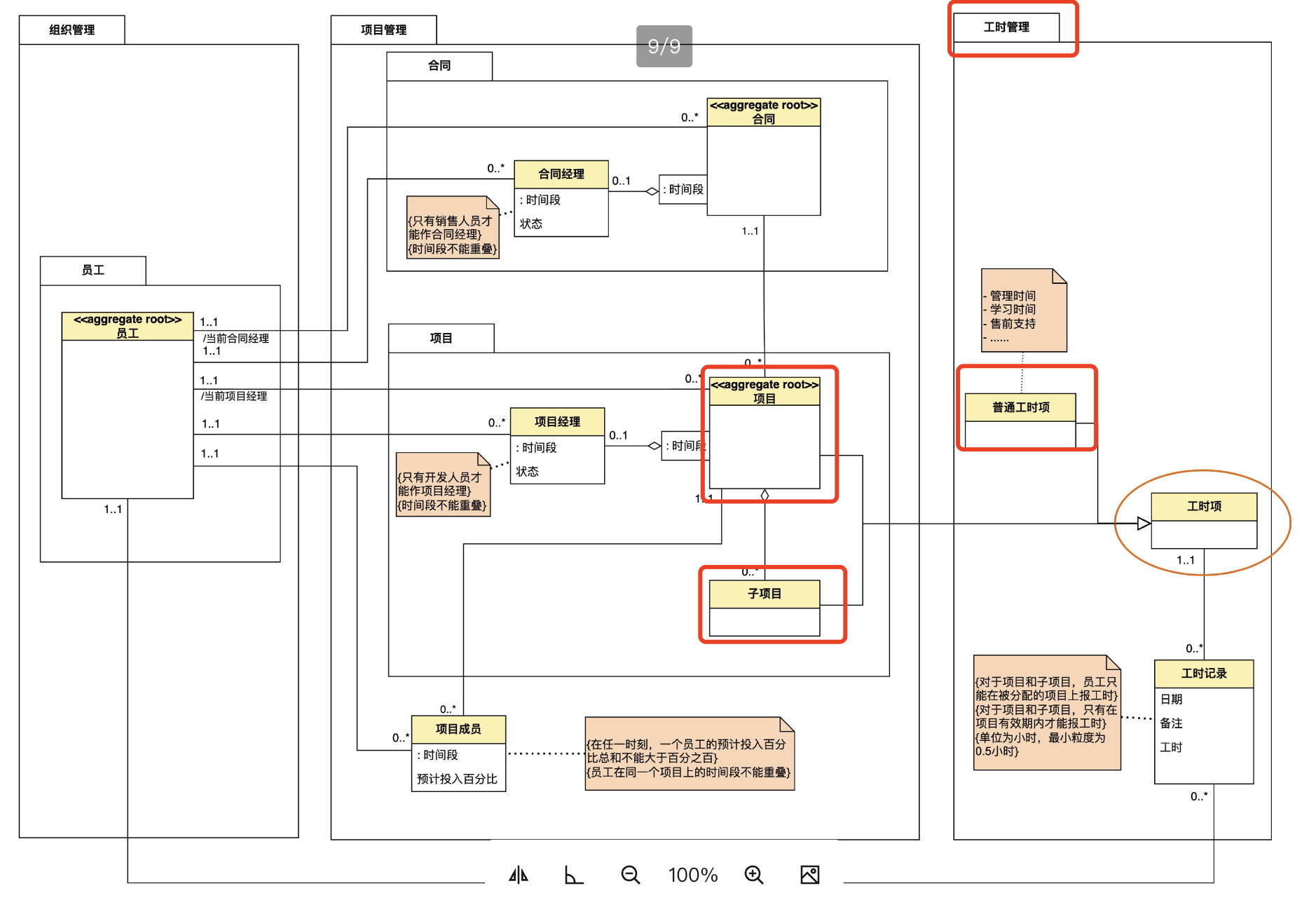
进一步抽象。 工时项,是对子项目,总项目,普通工时 的泛化
【权衡是否要泛化的衡量视角】
接下来,再讨论一下权衡泛化的两个视角:业务视角和技术视角
- 【业务视角】:实际上是业务人员和技术人员都理解的视角。站在这个视角,我们要考虑:引入泛化后,有没有在模型里增加新的知识,有没有使模型更加简洁,更容易理解?
- 【技术视角】:就要考虑这个模型是否能自然、直接地映射到设计模型和代码。我们沿用上面关于马的例子来说明。先看一看下面这张图。
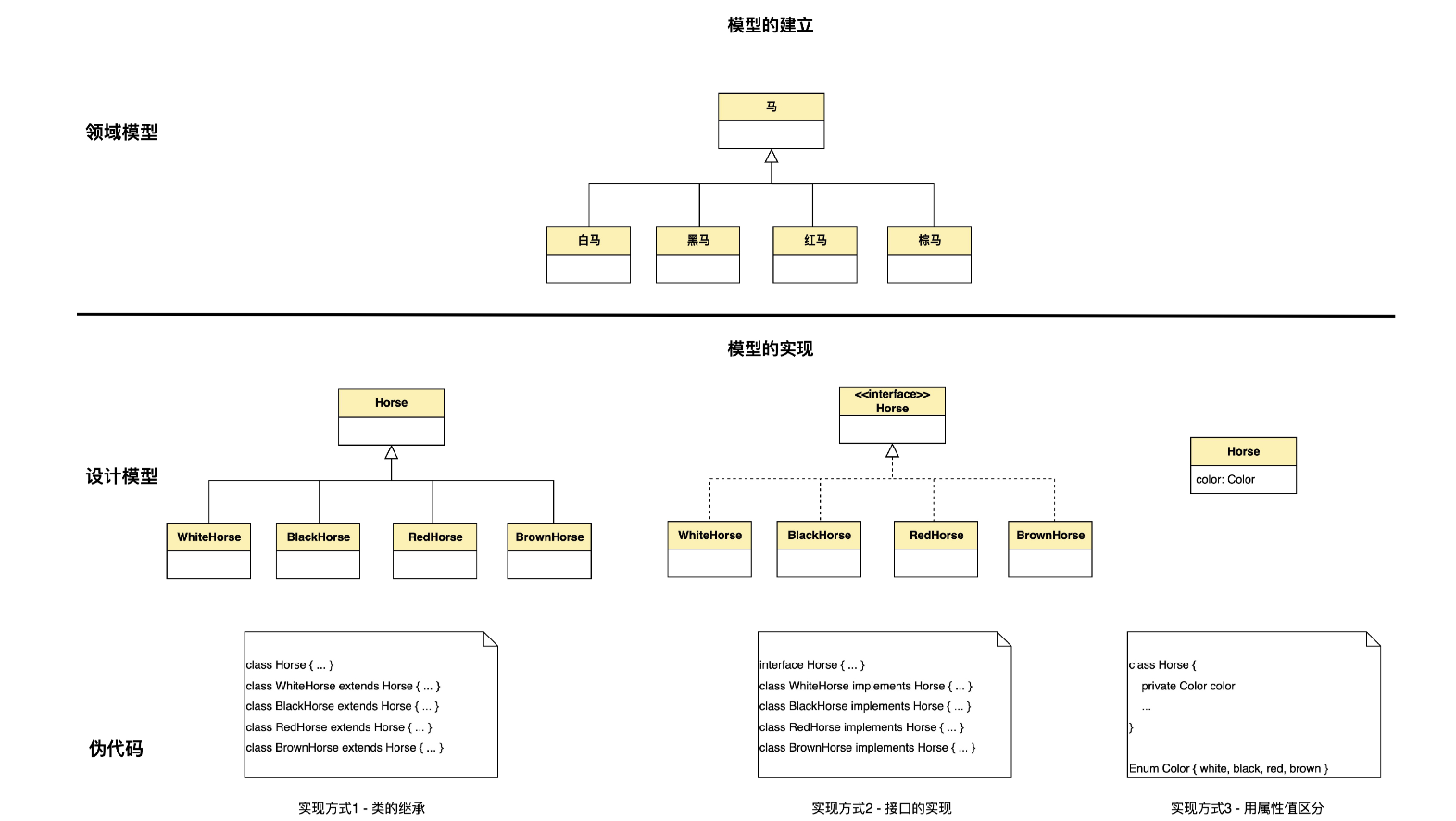
- 第一种:是使用类的继承。领域模型中的父类、子类,和实现中的父类、子类直接对应。这里有一个微妙的地方,要注意区分。在领域模型里,表示泛化的空三角符号就是分类的意思。而在设计模型里,这个空三角符号表示的则是面向的对象设计和编程中的“继承”。而继承,只是实现泛化的方式中的一种。它的特点在于,必须有不同种类的特性或者不同的操作。如果仅仅是某个属性值不同造成的泛化,那么用继承就不合适了。
- 第二种:是接口的实现。如果各个子类在属性和操作实现方面没有共性,但有相同的操作接口,就使用这种方式。
- 第三种:是用特性的值来区分,这时候在实现层面,就没有父类和子类之分了。
显然,领域模型中的泛化,转化成类的继承和接口的实现这两种方式,图的形式很接近,是比较直接的;而转化成特性值区分的方式,就没这么直接了。
当架构师看到,领域模型中的某部分可以用泛化和特性值两种方式建模的时候,就可以“偷偷地”想一下,考虑到简洁性、可理解性、可维护性等方面,在实现层面采用哪种方式更合适呢?
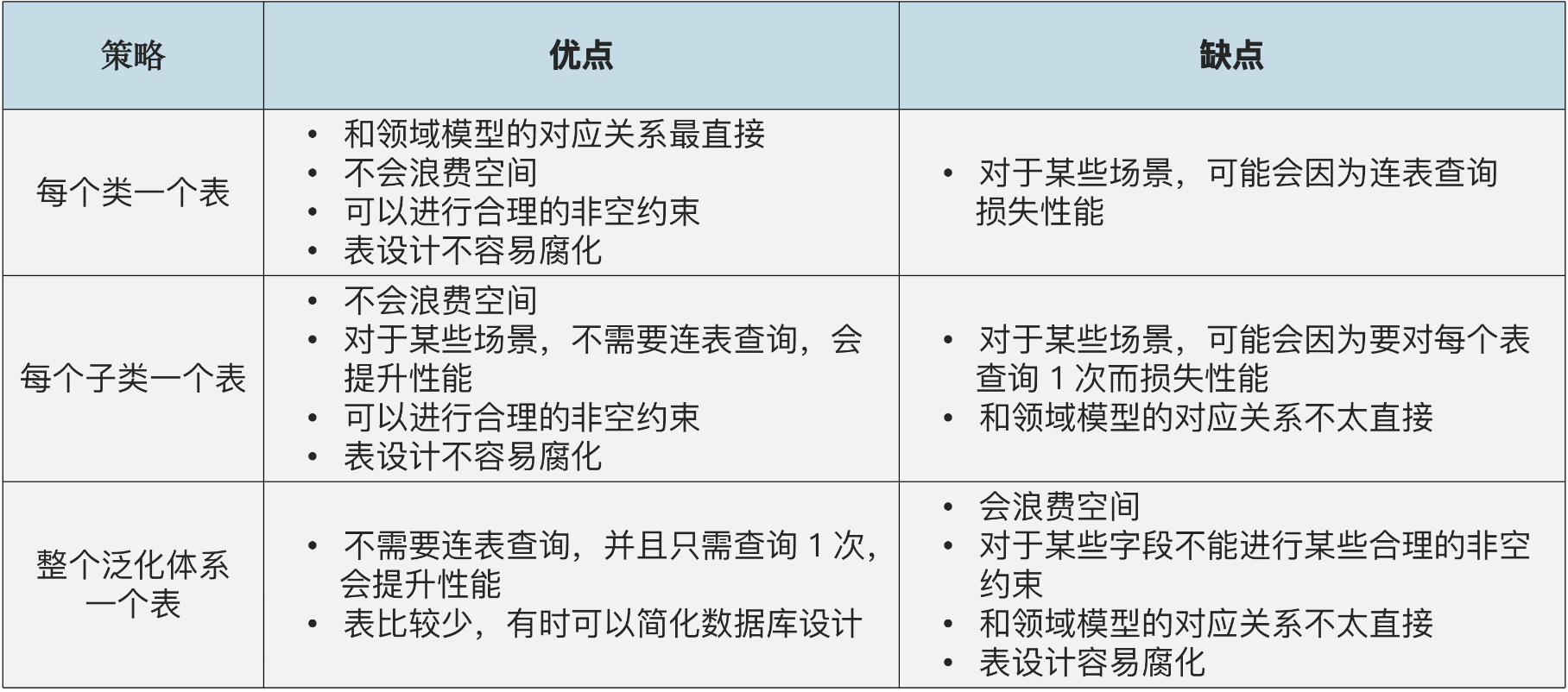
【泛化在数据库的实现的策略和优缺点的对比】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号