【数据结构和算法】【体系化学习】-字符串的匹配算法
一、暴力匹配算法 Brute Force
定义两个概念,分别是主串和模式串。
比方说,我们在字符串 A 中查找字符串 B,那字符串 A 就是主串,字符串 B 就是模式串。我们把主串的长度记作 n,模式串的长度记作 m。因为我们是在主串中查找模式串,所以 n>m。
最简单、最暴力的字符串匹配算法,BF 算法的思想可以用一句话来概括,那就是,我们在主串中,检查起始位置分别是 0、1、2....n-m 且长度为 m 的 n-m+1 个子串,看有没有跟模式串匹配的。
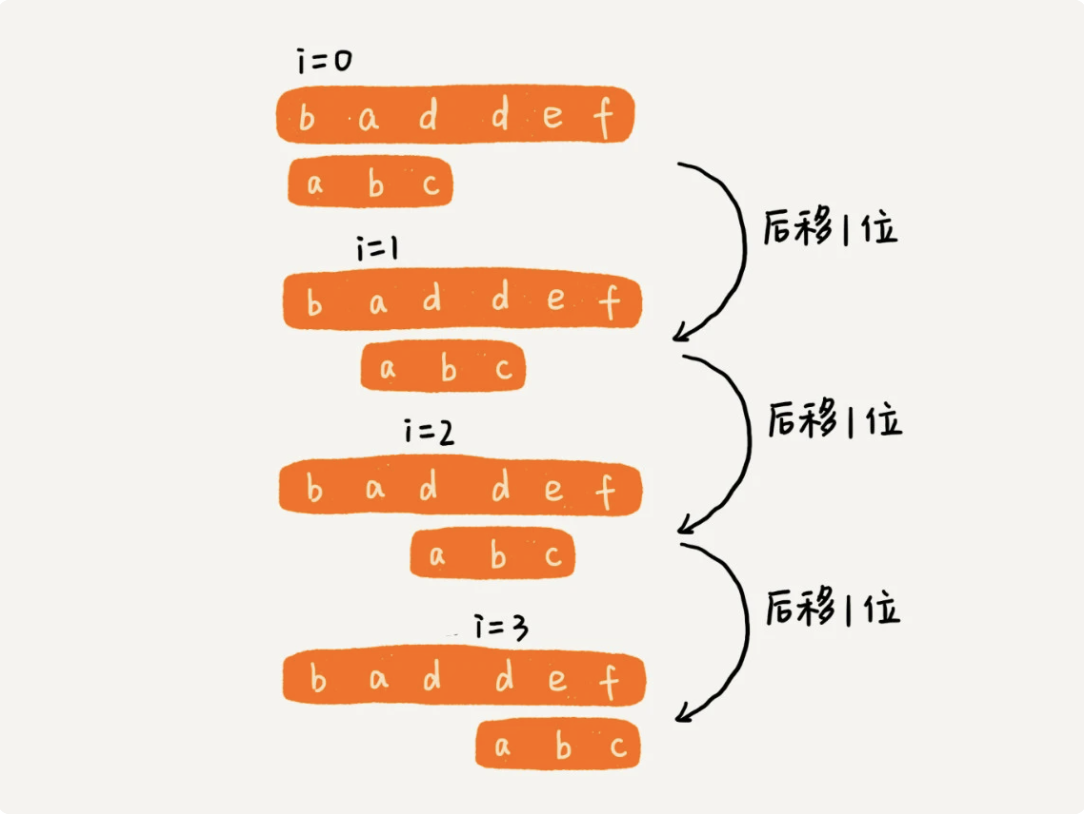
1.1.代码示意


public class StringContains { /** * 暴力匹配字符串是否存在另一个字符串中 * * @param sources * @param target * @return */ public boolean containsBruteForce(String sources, String target) { if (StringUtils.isBlank(sources) || StringUtils.isBlank(target)) { return false; } int sourceLength = sources.length(); int targetLength = target.length(); if (sourceLength < targetLength) { return false; } //计算主串截止匹配的 【开始下标】 int end = sourceLength - targetLength; //循环遍历主串 for (int i = 0; i <= end; i++) { //声明主串移动的下标 int sourcesIndex = i; //声明本次匹配是否成功的标记 boolean isMatch = true; //从第一个元素开始-循环模式串 for (int j = 0; j < targetLength; j++) { //主串的下标字符 和 模式串 对应的下标字符进行比对,相等则进行下一个字符的比对 if (!(sources.charAt(sourcesIndex) == target.charAt(j))) { //不相等,则表示主串从当前i开始的位置不包含模式串,跳出循环,从主串的下一个开始位置进行匹配 isMatch = false; break; } //对应下标字符相等,进行下一个下标位置字符的比对 sourcesIndex++; } if (isMatch) { //说明匹配成功,跳出循环,并退出 return true; } } //从主串所有开始位置都匹配了,未找到模式串,返回false,退出 return false; } }
二、暴力匹配算法RK-(Rabin-Karp算法)
2.1、算法图解
哈希算法设计的非常有技巧了。我们假设要匹配的字符串的字符集中只包含 K 个字符,我们可以用一个 K 进制数来表示一个子串,这个 K 进制数转化成十进制数,作为子串的哈希值。表述起来有点抽象,我举了一个例子,看完你应该就能懂了。比如要处理的字符串只包含 a~z 这 26 个小写字母,那我们就用二十六进制来表示一个字符串。我们把 a~z 这 26 个字符映射到 0~25 这 26 个数字,a 就表示 0,b 就表示 1,以此类推,z 表示 25。在十进制的表示法中,一个数字的值是通过下面的方式计算出来的。对应到二十六进制,一个包含 a 到 z 这 26 个字符的字符串,计算哈希的时候,我们只需要把进位从 10 改成 26 就可以。

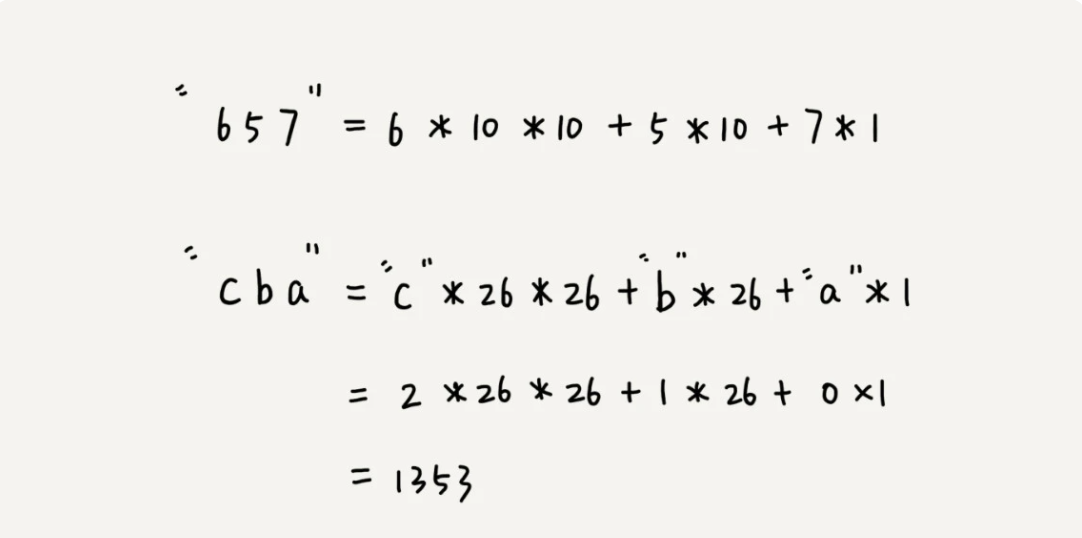
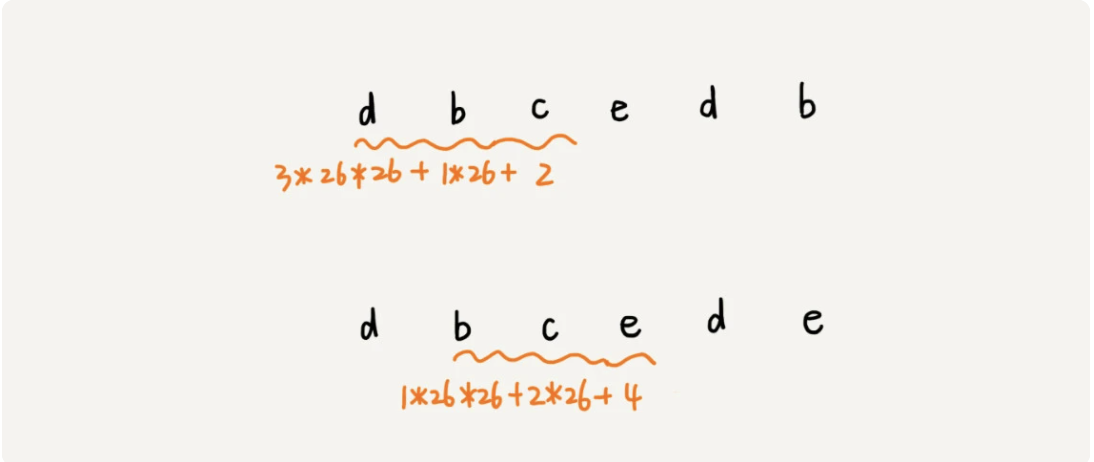
从这里例子中,我们很容易就能得出这样的规律:相邻两个子串 s[i-1]和 s[i](i 表示子串在主串中的起始位置,子串的长度都为 m),对应的哈希值计算公式有交集,也就是说,我们可以使用 s[i-1]的哈希值很快的计算出 s[i]的哈希值。如果用公式表示的话,就是下面这个样子:

不过,这里有一个小细节需要注意,那就是 26^(m-1) 这部分的计算,我们可以通过查表的方法来提高效率。我们事先计算好 26^0、26^1、26^2……26^(m-1),并且存储在一个长度为 m 的数组中,公式中的“次方”就对应数组的下标。当我们需要计算 26 的 x 次方的时候,就可以从数组的下标为 x 的位置取值,直接使用,省去了计算的时间。
哈希算法的冲突概率要相对控制得低一些,如果存在大量冲突,就会导致 RK 算法的时间复杂度退化,效率下降。极端情况下,如果存在大量的冲突,每次都要再对比子串和模式串本身,那时间复杂度就会退化成 O(n*m)。但也不要太悲观,一般情况下,冲突不会很多,RK 算法的效率还是比 BF 算法高的。
2.2、代码示意(该代码设计的hash算法和上文描述不一致,主要是为了阐述上文的算法思想)
public class StringContains { private static Map<String, Integer> mapHash = new HashMap<>(); static { mapHash.put("a", 0); mapHash.put("b", 1); mapHash.put("c", 2); mapHash.put("d", 3); mapHash.put("e", 4); mapHash.put("f", 5); mapHash.put("g", 6); mapHash.put("h", 7); mapHash.put("i", 8); mapHash.put("j", 9); mapHash.put("k", 10); mapHash.put("l", 11); mapHash.put("m", 12); mapHash.put("n", 13); mapHash.put("o", 14); mapHash.put("p", 15); mapHash.put("q", 16); mapHash.put("r", 17); mapHash.put("s", 18); mapHash.put("t", 19); mapHash.put("u", 20); mapHash.put("v", 21); mapHash.put("w", 22); mapHash.put("x", 23); mapHash.put("y", 24); mapHash.put("z", 25); } /** * 设计的hash算法是每个字符对应的数字之和进行累加 * s[i] * s[i-1] * 的hash计算的公式 * hash(s[i]) = hash(s[i-1]) - s[i-1]首字母的映射值 + s[i]尾巴字母的映射值 * * @param sources * @param target * @return */ private boolean constantsBF(String sources, String target) { int targetHash = 0; int sourcesHash = 0; int targetLength = target.toCharArray().length; int sourcesLength = sources.toCharArray().length; int m = sourcesLength-targetLength; for(int i=0;i<=m;i++){ if(i==0){ for(int j=i;j<targetLength;j++){ targetHash = targetHash + mapHash.get(String.valueOf(target.toCharArray()[j])); sourcesHash = sourcesHash + mapHash.get(String.valueOf(sources.toCharArray()[j])); } //如果hash计算相同,则比较是否相等(解决hash冲突问题) if(targetHash == sourcesHash){ boolean result= compareContent(sources.toCharArray(),target.toCharArray(),0); if(result){ return true; } } }else{ //abcdf bc sourcesHash = sourcesHash - mapHash.get(String.valueOf(sources.toCharArray()[i-1])) + mapHash.get(String.valueOf(sources.toCharArray()[i+targetLength-1])); //如果hash计算相同,则比较是否相等(解决hash冲突问题) if(targetHash == sourcesHash){ boolean result= compareContent(sources.toCharArray(),target.toCharArray(),i); if(result){ return true; } } } } return false; } private boolean compareContent(char[] sources,char[] target,int sourcesStartIndex){ for(int i=0;i<target.length;i++){ if(!(sources[sourcesStartIndex] == target[i])){ return false; } sourcesStartIndex++; } return true; } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号