【数据库原理】数据模型
一、数据模型
1、数据模型的概念
模型:是现实世界特征的模拟和抽象表达
数据模型
-
对现实世界数据特征的抽象,描述的是数据的共性能内容。
-
是模型化数据和信息的工具,也是数据库系统的核心和基础
-
满足三点:(1)比较真实的模拟现实世界(2)容易为人们理解(3)便于在计算机上实现
2、数据的特征
静态特征:数据的基本结构,数据间的联系,数据取值范围的约束
动态特征:对数据可以进行符合一定规则的操作。
3、数据模型组成要素
数据结构:描述的是系统的静态特征,即数据对象的数据类型、内容、属性以及数据对象之间的联系。
数据操作:描述的是系统的动态特征
数据约束:描述数据结构中数据间的语法和语义关联
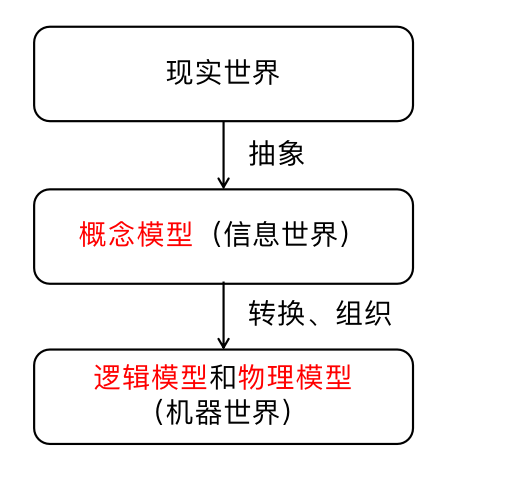
二、数据模型-概念模型
-
概念层是数据抽象级别的最高层。
-
概念层数据模型,也称为数据的概念模型或信息模型,这类模型主要用于数据库的设计阶段。
-
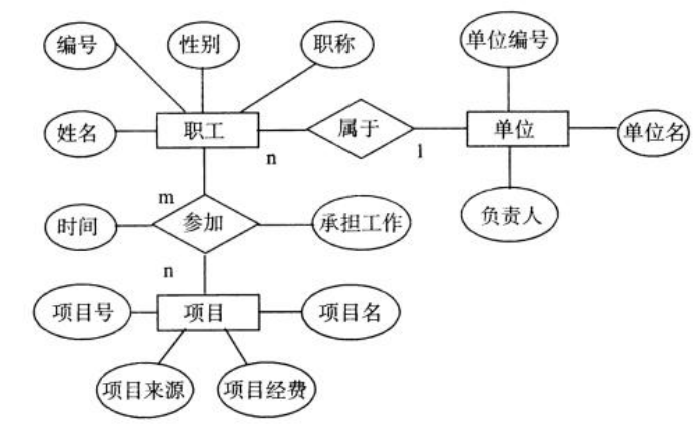
E-R图:概念层数据模型的其中一种表现方式
1、信息世界涉及的基本概念
实体(Entity):比如学生
属性(Arribute):比如姓名
码或键(key):比如学号
实体型(Entity Type):学生的类型(实体+属性)
实体集(Entity Set):一群学生的集合
域(Domain):数据的范围,比如性别,只有男和女。
联系(Relationship):数据实体之间的关系,学生属于哪个班级
2、数据模型有型(type)和值(value)两个概念
型(type):表头,比如姓名,年龄,籍贯
值(value):表行,比如张三,26,北京
三、数据模型-逻辑模型
逻辑层是数据抽象级别的中间层。
逻辑层数据模型,也称为数据的逻辑模型。任何DBMS都是基于某种逻辑数据模型。
1、层次模型
-
是最早使用的一种数据模型
-
有且仅有一个结点没有父结点,称作根结点
-
其他结点有且仅有一个父结点
2、网状模型
-
以网状结构表示实体与实体间的联系
-
允许结点有多于一个父结点
-
可以有一个以上的结点没有父结点
3、关系模型(数据库重点学习)
用二维表结构来表示实体间的联系。

优点:
-
建立在严格的数学概念的基础上
-
概念单一
-
存取路径对用户透明,有更高的数据独立性,更好的安全保密性
4、面向对象模型
-
既是概念模型又是逻辑模型
-
表达能力丰富,对象可复用、维护方便

四、数据模型-物理层数据模型
-
物理层数据模型,也称为数据的物理模型
-
描述数据在存储介质上的组织结构,是逻辑模型的物理实现;
-
是数据库最底层的抽象;
-
设计目标是提高数据库性能和有效利用存储空间。
五、数据模型中概念层数据模型,逻辑层数据模型,物理层数据模型的关系
-
这三个不同的数据模型之间既相互独立,又存在着关联。
-
从现实世界到概念模型的转换是由数据库设计人员完成的;
-
从概念模型到逻辑模型的转换可以由数据库设计人员完成,也可以用数据库设计工具协助设计人员完成;
-
从逻辑模型到物理模型的转换主要是由数据库管理系统完成的
六、关系型数据库的概述
1关系数据模型
组成要素
关系数据模型的组成要素:关系数据结构,关系数据操作集合,关系完整性约束
关系数据结构
(1)二维表:
也称为关系,是一个二维的数据结构,由表名、列、若干行数据组成。 每个表有唯一的表名,表中每一行数据描述一条具体的记录值。
(2)关系(也等于一张表):
一个关系逻辑上对应一张二维表,可以为每个关系取一个名称进行表示、
基本表(数据库实际存在的表),查询表(导出虚表),视图表(导出虚表)
(3)列(属性)(字段)
也称为字段(Field)或属性(Attribute)。
表名必须唯一; 字段名必须唯一, 不同表中可以出现相同的字段名;
属性=列,属性的个数称为关系的元或度, 列的值称为属性值,其取值范围称为值域
(4)行(元组)(记录)
也称为元组(Tuple)或记录(Record)。表中的数据按行存储。
分量(Component)=具体的数据项
元组(行)中的一个属性值,称为分量。
(5)码或键

(6)域
域(Domain) 表示属性的取值范围。
(7)数据类型
数据类型(Data Type) 每个列都有相应的数据类型,它用于限制(或容许)该列中存储的数据。
(8)数据模式
-
关系模式(Relation Schema)=表头 关系模式是型(type),关系是值(value),
-
即关系模式是对关系的描述。
-
关系模式是静态的、稳定的,
-
关系是动态的、随时间不断变化的。
(9)关系数据库(Relation Database) 所有关系的集合,构成一个关系数据库。
以关系模型作为数据的逻辑模型,并采用关系作为数据组织方式的一类数据库,其数据库操作建立在关系代数的基础上。
3.2、函数依赖与关键字
函数依赖是什么?关系中属性间的对应关系
函数依赖的定义:设R为任一给定关系,如果对于R中属性X的每一个值,R中的属性Y只有唯一值与之对应,则称X函数决定Y或称Y函数依赖于X,记作X→Y。其中X称为决定因素。
对于关系R中的属性X和Y,若X不能函数决定Y,记作X -/→Y。
函数依赖的分类
-
完全函数依赖(候选码(联合唯一索引属性集))
-
部分函数依赖 超码(包含唯一索引的属性集))
-
传递函数依赖 X-/-> Y
二、三范式
定义:一个低一级范式的关系模式通过模式分解(Schema Decomposition)(拆分)可以转换为若干个高一级范式的关系模式的集合,这种过程就叫规范化(Normalization)。
范式解决的问题:存储数据的冗余高 ,插入操作异常, 删除操作异常
第一范式(1NF)
设R为任一给定关系,如果R中每个列与行的交点处的取值都是不可再分的基本元素,则R为第一范式。 (单元格存储的值为最小单元,不可分割)
第二范式(2NF)
设R为任一给定关系,若R符合范式一 (1NF), 且其所有非主属性都完全函数依赖于候选关键字,则R为第二范式。 (消除部分函数依赖,除了联合唯一索引键的其他属性,完全依赖联合唯一索引键,)
第三范式(3NF)
设R为任一给定关系,若R为2NF, 且其每一个非主属性都不传递函数依赖于候选关键字,则R为第三范式。(消除传递函数依赖,表中的非主属性都是一个类型的数据)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号