
【消息中间件】Kafka消息中间件概念了解
一、生产者,消费者,主体,分区,borker
1、生产者
- 生产消息方
2、消费者
- 从主题中的分区拉取消息进行消费
3、消费者群组
- 具有共同消费目标的一组消费者组成的组,他们之间对消费目标的主体分区进行所有权分配,横向扩大消费能力。
4、主题
- 同一类消息的存储队列,类比数据库中的表。
5、分区
- 对同一类消息的存储队列进行横向扩容,类比数据库中的分表。
6、broker
- kafka集群中的一个机器节点称之为1个boker
7、broker持久化特性(保留消息)
- 保留一定期限(保留最近7天,超过7天的信息被删除掉),保留的字节数达到多大值,超过会被删除。那个先到,触发执行那个策略。

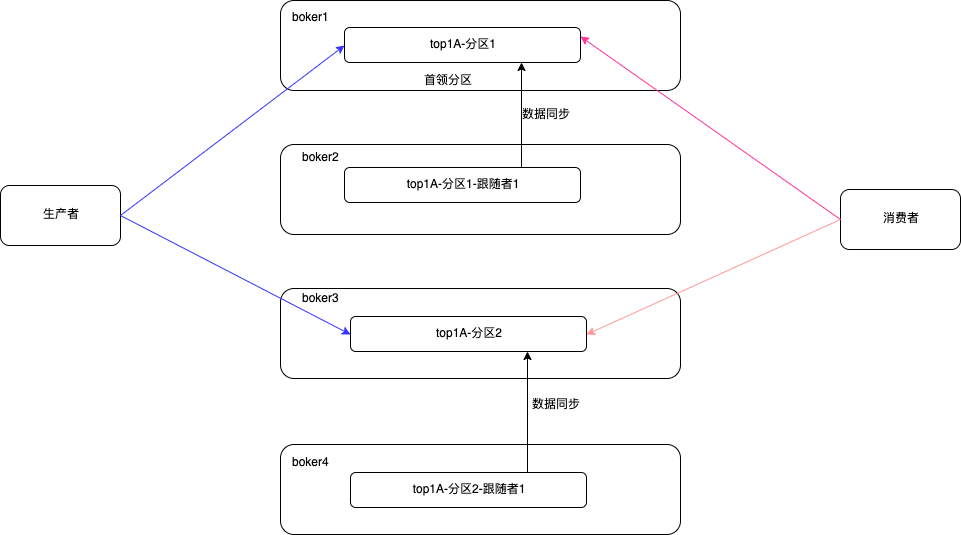
二、控制器,分区首领,跟随者副本
2.1、控制器
- 负责分区首领选举和分区首领角色的故障转移。
- 将topic的分区分配给指定的borker;
- 监控boroker的可用性
- kafka集群中的所有节点时刻监控控制器的可用性,一旦控制器故障,则从剩余的boker节点内重新选举一个新的控制器。
2.2、分区首领
- 也叫首领副本,所有生产者和消费者,以及跟随者副本都请求分区首领完成自身角色的功能。
2.3、跟随者副本
- 是首领分区的消息的副本,保证数据的容错性。集群中某一个boker宕机,该borker上的分区首领时效,则会被控制器感知到,再次从跟随者副本节点中重新选举出一个跟随者副本。
三、消息组成
3.1、主题
- 消息的地址
3.2、分区
- 用于指定分区
3.3、消息的键
- 用于分区路由的值
3.4、消息的值
- 消息内容
3.5、序列化器
- 对发送消息进行序列化为字节数组
3.6、反序列化器
- 对消费的消息通过反序列化,生成消息的内容
四、生产者

消息发送可重试,可批量发送,消息可压缩
1、发送方式
-
发送并忘记,不关注发送的结果
-
同步发送,等待结果
-
异步发送,等待回调
2、配置相关
-
acks:表示客户端响应消息发送是否成功的度量。acks=0,生产者只负责发送,不关心消息是否发送成功。acks=1,集群的分区首领节点收到消息并响应,保证分区首领节点接收到消息。acks=all,只有当所有参与复制的分区节点全部收到消息,生产者才会收到来自服务端的响应。
-
buffer.memory:表示生产者内存缓冲区的大小,生产者用它来缓冲发送到服务器的消息。如果程序发送消息的速度大于发送到服务器的速度,会导致生产者内存空间不足。这个时候send方法要么被阻塞,要么抛出异常。取决于block.on.buffer.full参数。在0.9.0.0替换成了max.block.ms,表示可以阻塞一段时间,等待缓冲区有空间。
-
compression.type:消息发送时,默认不会压缩。概述可以设置为snappy,gzip或者lz4.
-
retries:在消息发送失败时,重发消息的次数。生产者在每次重试前都等待100ms.也可以通过retry.backoff.ms改变这个时间间隔。
-
batch.size:同一主题,发送至统一分区,一次性可发送消息的总大小,按照字节数计算。批次不满也会被发送出去。
-
linger.ms:生产者发送批次前等待更多消息加入批次的时间,会在批次放满或linger.ms达到上限时把批次发送出去。
-
client.id:可以是任意字符串,用于标示消息来源。
-
max.in.flight.requests.per.connection:指定生产者在收到服务器响应之前可以发送多少个消息。值越高,占用内从越高。设置为1,保证消息按照发送顺序写入服务器,即使发生了重试。
-
timeouts.ms:指定了borker等待同步副本返回消息确认的时间。如果在指定时间内没有到同步副本返回消息确认的时间,返回一个错误。
-
request.timeout.ms:生产者在发送数据时,等待服务器返回响应的超时时间。
-
metadata.fetch.timeouts.ms:生产者获取元数据等待服务器返回响应的超时时间.
-
max.blocks.ms:生产者调用send(),partitionsFor()方法获取数据生产者的阻塞时间。当发送者缓冲区或没有可用的元数据时,这些方法会阻塞多长时间,达到阻塞时间,抛出异常。
-
max.request.size:该参数标识控制生产者发送消息的大小。boker端也可以控制接收到消息的大小message.max.bytes
-
receive.buffer.bytes和send.buffer.bytes:这两个参数分别指定TCP socket接收和发送数据包的缓冲区大小。如果他们设置为-1,使用操作系统默认值。可以适当调增该值,因为跨数据中心的网络一般都有比较高的延迟和比较低的带宽。
五、消费者
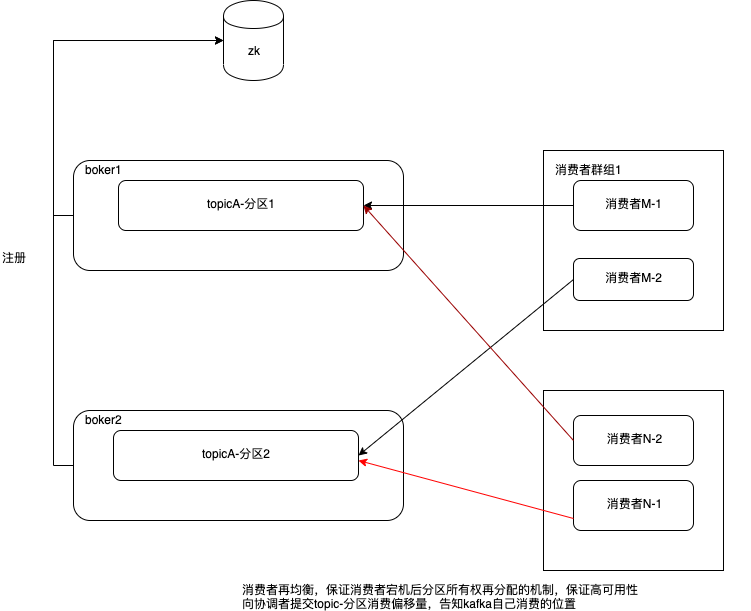
消费者群组和分区再均衡,为消费者群组带来高可用性和伸缩性。
消费者通过向被指派为群组协调器的borker发送心跳,来维持自己的活跃性,保障自己和分区的所有权关系。
第一种方式:如果一个消费者发生崩溃,并停止读取消息,群组协调器会等待几秒钟,确认它死亡了才会触发再均衡。
第二种方式:消费者在死亡期间,不会消费消息,在清理资源时,他会告诉协调器,他退出群组,触发协调器再均衡。
1、分配分区是怎样一个过程
(1)消费者加入群组时,会向群组协调器发送一个JoinGroup请求。第一个加入群组的消费者将成为群主。群主从协调器那里获得群组的成员列表(列表包含了所有最近发送过心跳的消费者,他们被认为是活跃的),并负责给每一个消费者分配分区。它使用了一个实现了PartitionAssignor接口的类来决定哪些分区应该被分配给哪个消费者。
(2)分配完毕后,群主会把分配情况列表发送给群组协调器,协调器再把这些信息发送给所有的消费者,每个消费者只能看到自己的分配信息。然后按自己所有权的分区,消费消息。
2、订阅主题和轮询
(1)订阅主题:支持指定订阅和正则表达式订阅。
(2)轮询是消费者核心api。轮询处理所有消费者细节,包括:群组协调,分区再均衡,发送心跳,获取数据。
3、消费者相关配置
-
fetch.min.bytes:从服务器获取记录的最小字节数
-
fetch.max.wait.ms:指定broker的等待时间,默认500ms.如果没有足够数据满足fetch.min.bytes,则返回当前所有可用数据。
-
max.partition.fetch.bytes:指定消费者服务器在broker上每个分区返回的最大字节数。默认值未1MB。如果1个主题20个分区。和5个消费者。每个消费者至少需要4Mb的空间保存接受消息。
-
session.timeout.ms:该属性指定了消费者在被认为死亡前可以与服务器断开连接的时间,默认为3s.这个配置和heartbeat.interval.ms指定poll()方法向协调者发送心跳的间隔紧密相关。session.timeout.ms指定多长时间可以不发心跳。heartbeat.interval.ms指定多长时间发送一次心跳。一般heartbeat.interval.ms是session.timeout.ms的1/3
-
auto.offset.reset:消费者在读取一个没有偏移量或偏移量无效的分区的情况下该作何处理。默认值为latest,意思是消费者将从最新的记录开始读取数据(在消费启动之后生成的最新记录)。另一个值是earliest,意思是说,在偏移量无效的情况下,消费者将从分区的起始位置开始读取记录。
-
enable.auto.commit:该属性指定消费者是否自动提交偏移量。如果设置为true。为了尽量避免出现重复数据和数据丢失,可以把它设置为false,由自己控制合适提交偏移量。还可以通过控制auto.commit.interval.ms属性来控制提交频率。
-
partition.assignment.strategy:PartitionAssignor根据给定的消费者和主体,决定哪些分区应该被分配给哪个消费者。kafka有两个默认策略。Range:把主体若干个连续分区分配给消费者。比如C1,C2订阅了主题T1,T1有3个分区,C1得到0,1分区,C2得到2分区。 RoundRobin:分区和主体依次匹配,保证每个消费者分配到相同的分区,最多差1个分区。
-
client.id:boker用他来标识从客户端发送过来的消息,通常被用在日志度量指标和配额里。
-
max.poll.records:该数据行用于控制单次调用call()方法返回的记录数量。可以帮助你控制在轮询里需要处理的数据量。
-
receive.buffer.bytes和send.buffer.bytes:socket在读写数据时用到的TCP缓冲区,也可以设置大小。如果他们设置为-1,默认使用操作系统的默认值。如果生产者和消费者与boker处于不同的数据中心,可以适当增大这些值。
3、提交偏移量
同步提交,异步提交
批量消费消息的缘故。偏移量延迟提交,当消费者宕机,则会出现重复消费。偏移量过早提交,会导致消息会数据丢失

 浙公网安备 33010602011771号
浙公网安备 33010602011771号