【服务建设】过载&雪崩
1.过载介绍
何为过载,即当前负载已经超过系统的最大处理能力。
过载后果:
会导致部分服务不可用,如果处置不当,极有可能引起服务完全不可用,乃至雪崩。
过载原因:
“过载”的出现,不同系统模型的具体原因都会有所不同,例如CPU跑慢,频率读写导致IO瓶颈,内存耗尽,请求量突增等。但究其根本原因,可以归结为两点:
-
处理能力的下降
-
请求量的上升
保护行为:
任何问题的保护行为可以依据事件发生的阶段分为:
-
发生前,预防
-
发生时,处置
-
发生后,恢复
2.雪崩介绍
一个应用中,任意一个点的不可用或者响应延时都有可能造成服务不可用。当hang住的请求会很快耗尽系统的资源,当该类请求越来越多,占用的计算机资源越来越多的时候,会导致系统瓶颈出现,造成其他的请求同样不可用,最终导致业务系统崩溃。
服务雪崩效应:是一种因服务提供者的不可用导致服务器调用者的不可用,并将不可用逐渐放大的过程。
雪崩原因:
造成雪崩原因可以归结为以下三个:
-
服务提供者不可用(硬件故障,程序Bug,缓存击穿,用户大量请求)
-
重试加大流量(用户重试,代码逻辑重试)
-
服务调用者不可用(同步等待造成的资源耗尽)
最终的结果就是一个服务不可用导致一系列服务的不可用,而这种后果往往无法预料
应对策略:
-
流量控制(网关限制,用户交互限流,关闭重试)
-
改进缓存模式(缓存预加载,用户改为异步刷新)
-
服务自动扩容
-
服务调用者降级服务(资源隔离,对依赖服务进行分类,不可用服务的调用快速失败(一般通过超时机制,熔断器和熔断后的降级方法来实现))
4 过载预防
在过载发生前的预防,就需在系统设计之初,依据具体的业务模型可以考虑预防过载的措施:
1、 优化服务处理流程,降低处理资源消耗,提升自身处理能力;例如CPU消耗型服务,是否可以考虑优化算法,提升处理能力。
2、 分离处理模块;将负载分担到不同的模块或者服务器;例如IO是瓶颈的服务,考虑是否可以将IO模块进行分离。
3、 负载均衡;将请求量分流,降低单服请求量。
4、 轻重模块分离;重要模块单独部署和处理,防止模块之间的互相影响。
5、 前端防御;在前端控制请求频率,缓解后端压力;例如客户端可以做保护措施,控制聊天频率,点击操作失败,可以延时一段时间,才允许用户继续点击;前端服务发现后端出现过载问题,可选择性拒绝服务,降低后端压力。
6、 使用缓冲区;缓冲区的使用,可以帮我们抵挡请求量的抖动,但缓冲区的使用同样也有很多技巧,并非越大越好。首先需要考虑内存,cpu等资源的开销,业务的模型是否需要这么大的缓冲区。例如缓冲区过大,处理完整个缓冲区,都需要几十秒,而前端等待超时则为几秒,那么每次处理缓冲区的内容,都是旧的,前端认为都是超时,服务完全不可用。另外是后端却又处理成功,会导致系统信息不对称,从而导致更为严重的问题,例如,在游戏中购买道具的场景,前端扣用户的钱,认为超时失败而不给用户发对应的物品,后端却又执行成功了,严重运营问题就此产生。
7、 做好监控,及时告警;例如当CPU达到80%时,当处理请求超出一定阈值时,及时告警,做好扩容,优化等其他准备。
当然依据业务模型的不同,还有很多预防的措施,依然是前述做到知底,才能够找出适合自身的方法。
5 过载保护
处理过载的方法有许多,适用于不同的业务场景,并无绝对的最优方案,合适的才是最好的,但能匹配上“合适”一词,是对系统整体和经验的一个考验。下面介绍一些常用的处理方案以及我们是如何做的:
Ø 请求量阈值控制
在系统部署上线之前,预估好系统的处理能力,限定最大同时能够处理的请求量、流量或者链接数。当请求量快接近于最大处理能力时,则告警,超过范围,则触发拒绝请求机制。由此可见对于阈值的设置是一个很关键的环节,阈值过高,依然可能导致过载,阈值过低,则又导致负载上不去。阈值的设置也会是一个不断调优的过程。该方法的优点和缺陷都很明显。
优点:识别和处理简单;
缺点:阈值的设定需要一定的经验,会有一定的难度,同时如果处理能力发生变化时,阈值就很难动态发生变化。
Ø 监控系统资源
服务器监控CPU,内存等资源的使用情况,设定阈值,超出阈值,则可以认为过载,从而触发拒绝请求机制。
优点:使用动态的资源数据,从相对根本的原因上识别过载,而无需过多关心具体的业务处理;
缺点:一是处理相对复杂;二是在某些场景下,资源数据的耗尽并不意味着出现过载的情况。例如服务开了较大的内存池,看起来内存资源耗尽了,实际上负载是足够的,又如现在都是多核服务器跑着多进程或者多线程的服务,单一的CPU耗尽也不能够代表服务就出现过载,但又可能产生过载,这就和具体业务有关;三是在某些场景下,出现过载的情况,也不一定会耗尽资源,例如当前所有的服务都在等待之中(可能是后端的回复或者其他),同样也不会对CPU、内存、io、网络等资源造成影响,但依然进入了过载。总体来说该方式适合的场景相对会简单点。
Ø 检测请求到达时间
依据请求处理的时延来判断是否过载。记录请求到达的时间戳,和处理请求结束的时间戳,得到请求到达自身服务器处理的时延,超出阈值,则可判定为超时失效,可以直接丢弃。使用独立模块读取系统缓冲区中数据,打上时间戳,存入消息缓冲区,在处理时,超过一定时延的请求,则拒绝处理,因为可以认为即使处理了也是无用的。从中可以看出时间戳很关键(为啥会单独提出这个问题,因为在后续的方案设计中,时间戳依然是解决过载问题的关键点,此处先卖个关子)。
A、 时间戳如果使用本地读取时刻调用系统的时间函数获取,就没有考虑消息包到达系统缓冲区的时间,因此是万万不能这样做。
B、 到可以通过ioctl调用SIOCGSTAMP的接口,获得时间戳,但这会加大系统开销,原因是每次recv完,都需要重新设置一下ioctl一次。并且不是线程安全的。
C、 使用socket选项SO_TIMESTAMP,通过带外数据获取到数据到达系统缓冲区的时间。
其处理方式如下图所示:

通过这种方式已经能够很好地解决负载问题,通过如此,并不需要设置过于繁琐的配置或者去识别过载的问题,目前此方法在SPP的框架中在使用。个人觉得可能存在的一些问题在于:
1、 完全使用时间戳过期的方式来判断,并不一定适合所有场景,假设处理耗时过长,而在缓冲区中也呆了较长时间,但请求量并不大,服务器未过载,在处理一些需要强写入的情况下,单靠该机制也会稍许欠妥。但如果加入一些协议上层机制,告诉该消息务必执行,也是可避免的。
2、 在出现过载的情况之下,很可能会导致整体的服务都会产生一个固定的延时,因为每次抛弃到可执行的范围内,至少会有一个超时时间范围内的延时,如果是较长的服务链的话,最前面的等待服务很可能会出现超时,因此其延时的设置相对也很困难,过小就太过灵敏,过大就会出现刚所述的问题。
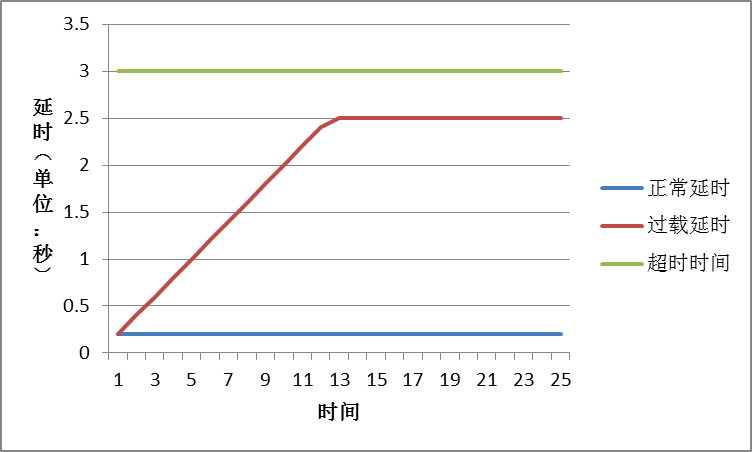
3、 该方式只是管理了到达本服务器缓冲区之后的问题,并没有考虑整条服务链上的延时,很可能到达本服务器缓冲区时,就已经过期了,并且有可能这些数据在对端缓冲区已经产生了堆积,但到本端,并不会判断其过期。
4、 剩下还有一些内容可以做更多优化:另外SO_TIMESTAMP使用的是系统时间,会受系统时间修改的影响,但这个问题也不大,因为即使修改了,影响的只是本次系统缓冲区的数据。其他可以考虑业务的轻重程度,做按服务来丢弃。
参考链接:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号