MySQL索引
前言
索引是为了帮助MySQL高效查询的一种数据结构,存储在文件系统中。
一、索引种类
- 主键索引
主键是一种唯一性索引,使用primarykey指定,一个表只能有一个主键,即使不手动指定,MySQL也会默认生成。 - 唯一索引
索引列的所有值只能出现一次,但必须唯一。可以为null。 - 组合索引
多个列组成的索引,用于组合搜索。 - 普通索引
基本的索引类型,可以为空,可以不唯一。 - 全文索引
全文索引的类型为fulltext,可以在varchar、char、text类型的列上创建。
二、MyIasm和InnoDB选择B+树的原因
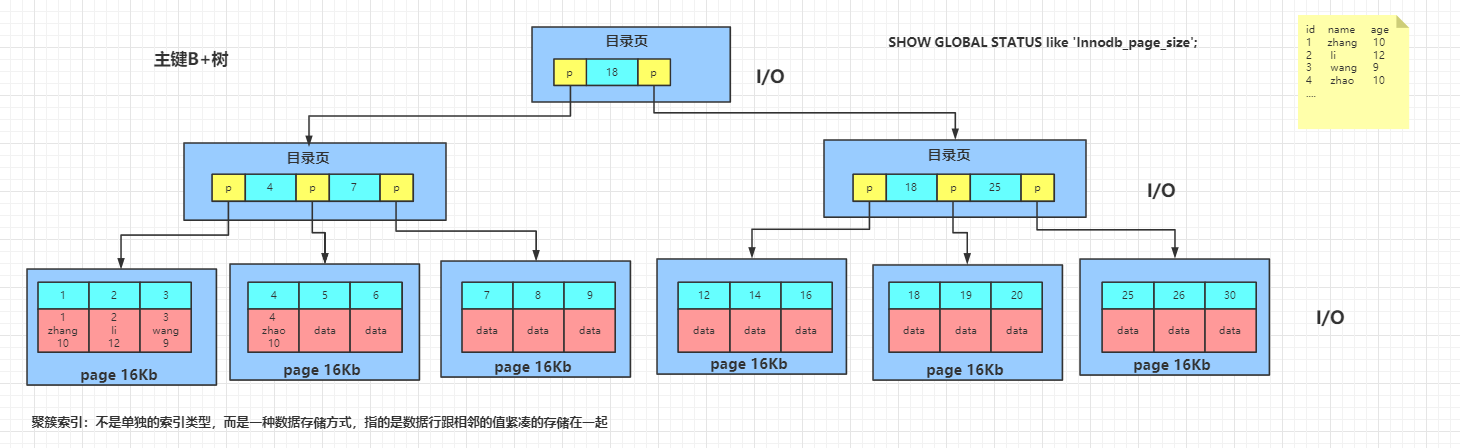
MySQL针对InnoDB引擎来说,使用的是B+树的数据结构形式,是B树的变种。相较于B树,最大的区别是数据节点全部存放于叶子节点,此时,非叶子节点可以存更多的指向下一页的地址。因为每一页默认是16Kb,如果在目录页存放数据,就会造成指向下一页的地址变少,增加磁盘IO次数,造成深度加深。所以说,选择B+树的根本原因就是减少树的深度,减少磁盘IO次数。当然,选择B+树还有一个原因是,从左至右,叶子节点是顺序排列的。
三、最佳左前缀法则、回表、覆盖索引、索引下推
1. 最佳左前缀法则
假设,我们给表添加组合索引 name,age。那么sql会先根据name字段查询数据之后,再根据age查询数据。
select * from user where name='zhang' and age = 10; // 使用到索引
select * from user where name='zhang'; // 使用到索引
select * from user where age = 10 and name='zhang'; // 使用到索引,由于优化器的存在,会优化sql,让其使用到索引。
select * from user where age = 10; // 没有使用到索引
select * from user where name like '%ang';// 没有使用到索引,最左不知道根据哪些字符串查找
select * from user where name like 'zha%'; // 使用到索引,根据最左的zha来进行查找
2. 回表
假设,我们给表的name字段添加索引,执行select * form where name = 'zhang';时,我们会在name索引树上查找叶子节点,找到对应的数据的主键id,然后根据主键id去主键索引树上查找对应的数据,然后返回给客户端。进行了6次磁盘IO。

3. 覆盖索引
执行select id form where name = 'zhang';时,根据上图所示,可以直接找到相应的id,直接返回给客户端。
给(username, age)建立索引,查询的列数据都在叶子节点上,不用回表。执行select username , age from user where username = 'Java' and age = 22,直接返回结果给客户端。
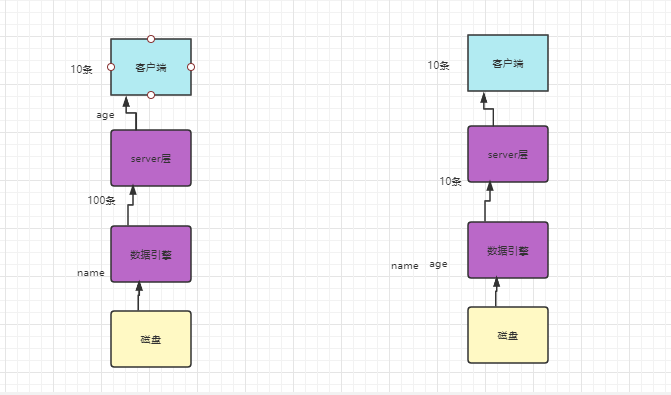
4. 索引下推
对于执行select * from where name='zhang' and age=10时,如果没有索引下推,我们会先根据name查询100条数据到server层,然后再server层根据age过滤数据结果10条,返回给客户端。
而针对索引下推来说,会根据name和age查询,将最终的10条记录查询到server层,最后返回给客户端。
没有使用索引的常见情况
- 有or,必须在or的所有字段加索引
- 符合索引不符合最左匹配
- like 以 % 开头
- 需要类型转换。比如varchar不带引号
- where中索引列有运算
- where中索引列使用了函数
- 如果mysql觉得全表扫描更快时,不使用索引(数据少)
索引优化细节
- 当使用索引列进行查询的时候尽量不要使用表达式,把计算放到业务层而不是数据库层。
- 尽量使用主键查询,而不是其他索引,因此不会发生回表查询
- 使用前缀索引,要如何控制索引长度
- 使用索引扫描排序
- union all,in,or都能够使用索引,但推荐使用in
- 范围列可以用到索引
- 强制类型转换会全表扫描
- 更新十分频繁,数据区分度不高的字段上不宜建立索引
- 创建索引的列,不允许为null,可能会得到不符合预期的结果
- 当需要进行表连接的时候,最好不要超过三张表,因为需要join的字段,数据类型必须一致
- 能使用limit的时候尽量使用limit
- 单表索引建议控制在5个以内
- 组合索引字段数不允许超过5个

 浙公网安备 33010602011771号
浙公网安备 33010602011771号