

程序的三种基本控制结构及其相关概念
1.C语言的三种基本结构
顺序结构:从头到尾一句接着一句的执行下来,直到执行完最后一句;
选择结构:到某个节点后,会根据一次判断的结果来决定之后向哪一个分支方向执行;
循环结构:循环结构有一个循环体,循环体里是一段代码。对于循环结构来说,关键在于根据判断的结果,来决定循环体执行多少次;
注:在逻辑上有一种布尔类型,只有两个值,即真和假。
C语言的判断表达式最终的值就是一个bool类型,这个判断表达式的bool值就决定了选择结构如何选择,循环结构如何循环;
2、顺序结构:顺序结构很简单,一般我们遇到的除了选择结构和循环结构外,都是顺序结构;
3、选择结构:C语言中常用的选择结构主要有以下两种:
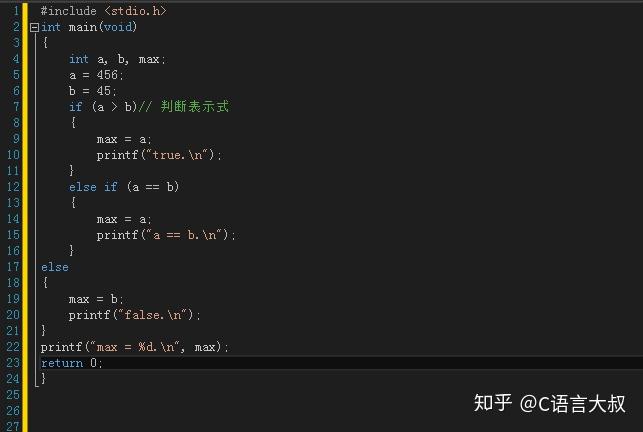
(1) if else:引入关键字:if else else if
if (bool值) // 如果bool值为真,则执行代码段1,否则执行代码段2
{
代码段1
}
else
{
代码段2
}
if (bool值1) // 如果bool值1为真,则执行代码段1,否则判断bool值2是否为真
{
代码段1
}
else if (bool值2) // 若bool值2为真则执行代码段2,否则直接执行代码段3
{ // 开头的if和结尾的else都只能有一个,但是中间的else if可以有好多个
代码段2
}
else
{
代码段3
}
例如:
4、循环结构:C语言中常用的循环结构主要有以下三种:
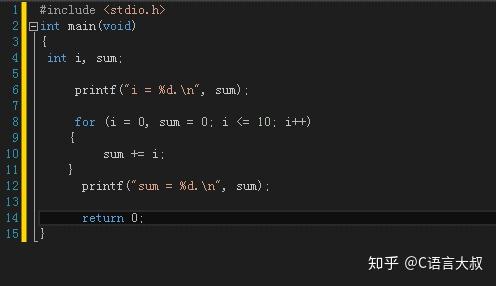
(1) for:
for (循环控制变量初始化; 循环终止条件; 循环控制变量增量)
{
循环体
}
循环执行步骤:第一,先进行循环控制变量初始化;
第二,执行循环终止条件,如果判断结果为真,则进入第三步;如果为假则循环终止并退出;
第三,执行循环体;
第四,执行循环控制变量增量,转入第二步;
注:for循环()中的三部分除了循环终止条件外,其他两部分都可以省略,但标准的for循环中,应该把循环控制变量的初始化,增量都放在()当中,并且在循环体中绝对不应该更改循环控制变量;
例如计算1+2+3+····+10
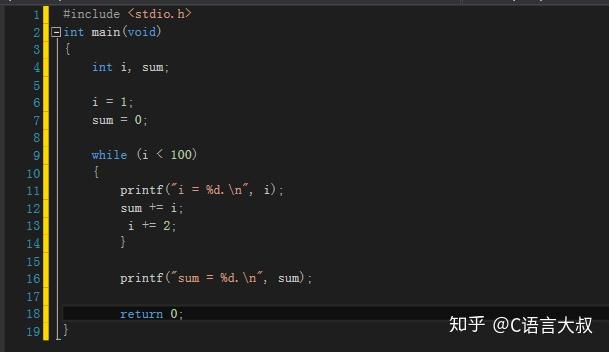
(2) while:
循环控制变量初始化
while(循环终止条件)
{
循环体
循环控制变量增量
}
循环执行步骤:第一,先进行循环控制变量初始化(在while之前);
第二,判断循环终止条件,如果判断结果为真,则进入第三步;如果为假则不执行循环体;
第三,执行循环体;
第四,执行循环控制变量增量,转入第二步;
比如计算100以内所有奇数的和 :
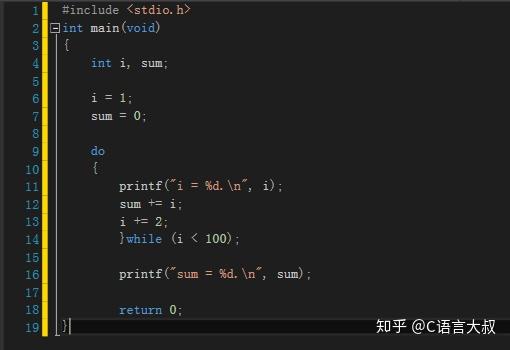
(3) do while:
循环控制变量初始化
do
{
循环体
循环控制变量增量
}while (循环终止条件);
循环执行步骤:第一,先进行循环控制变量初始化(在do while之前);
第二,执行循环体;
第三,执行循环控制变量增量;
第四,判断循环终止条件,如果判断结果为真,则返回第二步;如果为假则直接退出循环;
例如计算100以内所有奇数的和:
C语言基本语句的使用(赋值、条件、循环、switch、break、continue语句)
一、赋值语句
赋值语句形如:
变量=表达式;
变量=变量=变量=·······=表达式;
计算功能大部分是由赋值语句实现。
赋值运算符=,将右侧表达式(右值)的值赋给左侧变量(左值)
赋值过程中的类型转换
浮点型→整型:先取整,舍弃小数部分,再赋值
整型→浮点型:数值不变,以浮点数形式存储到变量
double→float:双精度转单精度,以4字节存储,若超出float范围则出错
float→double:数值不变,以8字节存储,有效位数扩展到15位
字符型→整型:将字符的ASCII代码赋给整型变量
字节多的整型→字节少的整型:将其低字节原封不动送给被赋值变量(即发生“截断”)
要避免此类情况,因为赋值后数值可能发生失真。
赋值表达式与赋值语句:
赋值表达式末尾没有分号,赋值语句末尾必须有分号。
在一个表达式中可以包含一个或多个赋值表达式,但绝不能包含赋值语句。
变量赋初值
一般不是在编译阶段完成(只有静态存储变量和外部变量的初始化是在编译阶段完成的),而是在程序运行时执行本函数时赋予初值的,相当于执行一个赋值语句。
如int a =3;相当于int a;a=3;
二、条件语句 ----- 同 上面的选择结构+switch csae
三、循环语句 ----- 同上面的循环结构
(2) switch case:引入关键字:switch case break default
switch语句原理是跳转到case X位置执行剩下的语句,直到最后或者遇见break为止。因此在每一条语句最后+break即可。
因此不加break的话将会执行跳转到的case本身以及以下所有的语句。
switch的执行是按照从小到大的顺序执行的,最后执行default语句,
如果default后面带有break,那么程序就会正常跳出switch,否则,
程序会继续向后执行switch语句!也就是说,不管default放在什么
位置,它总是在最后一个处理,然后继续向下处理!
所以,最后的处理办法,避免出现以外结果的最好办法就是每一个case
以及default语句都要加一个break!
default在switch开头:
(1)若所有case都不满足条件,则执行default,并执行default语句之后的case语句,直到break或结束,
(2)
default在switch中间:
若所有case都不满足条件,同上,直接执行default语句,并执行default语句之后的case语句,直到break或结束,
(3)
default在switch末尾:
若所有case语句都不满足条件,则执行default语句,结束;若有case满足,则执行case语句直到遇到break或switch语句结束
switch (变量) // 执行到这一句时,变量的值是已知的
{ // switch case语句执行时,会用该变量的值依次与各个case后的常数去对比,试图找到第一个匹配项,找到匹配的项目后,
case 常数1: //就去执行该case对应的代码段,如果没找到则继续下一个case,直到default
代码段1;// 如果前面的case都未匹配,则default匹配。
break;
case 常数2:
代码段2;
break;
……
default:
代码段n;
break;
}
注:第一,case中必须是常数,而且必须是整形;
第二,一般来说,每个case中代码段后都必须有一个break;
第三,case之后一般都会有default,虽然语法上允许没有default,但是建议写代码时一定要写;
例如: 结构化设计-选择结构示例代码 switch case演示
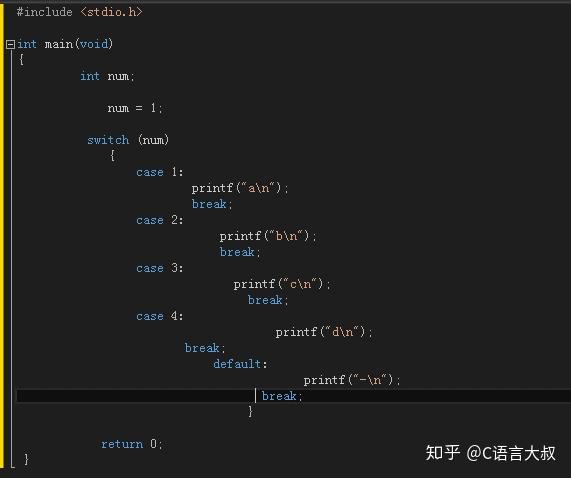
(3) if else和switch case的区别:if else适合对比条件较复杂,但是分支比较少的情况,switch case适合那种对比条件简单,但是分支较多的情况;
通常的做法是:在适合使用switch case的情况下会优先使用switch case,如果不适合则使用if else;
switch(表达式)
{
case 常量表达式1:语句1;
....
case 常量表达式2:语句2;
default:语句;
}
break语句和continue语句
break和continue都是用来控制循环结构的,主要是停止循环
break用于完全结束一个循环,跳出循环体执行循环后面的语句。
break语句既能用在switch中,又能用在循环体中。
continue语句只能用于循环体中。
continue和break有点类似,区别在于continue只是终止本次循环,接着还执行后面的循环,break则完全终止循环。
可以理解为continue是跳过当次循环中剩下的语句。执行下一次循环
C语言中没有boolean类型
* 在C语言中,关系运算的结果为"真"就返回1,"假"就返回0
inta1 =5>4;// 1inta2 =5<4;// 0
* 还需注意的是,在C语言中,任何非0值都为"真",只有0值才为"假"
控制语句
用于完成一定的控制功能
if()….else… //条件语句
for()… //循环语句
while()… //循环语句
do…while() //循环语句
continue //结束本次循环语句
break //中止执行switch或循环语句
switch //多分支选择语句
return //从函数返回语句
goto //转向语句,在结构化程序中基本不用goto语句
()表示括号中是一个“判别条件”,“…”表示内嵌的语句
1.C语言中空语句一般有哪些用途?
1.纯粹消耗cpu时间,起到延时的作用
2.为了程序的结构清楚,可读性好,以后扩充新功能方便。有些公司的编码规范要求,对于if/else语句等,如果分支不配对的话,需要用空语句进行配对,
2.在if语句中,使用布尔变量应注意什么?
不可将布尔变量直接与TRUE、FALSE或者1、0进行比较,根据定义,零值为假(FALSE),任何非零值都是真(TRUE),假设布尔变量名字为flag,它与零值比较的标准if语句为
if(flag)或者if(!flag)
C语句可分为以下五类:
1 表达式语句; 2 函数调用语句; 3 控制语句;
4 复合语句; 5 空语句。
1) 表达式语句
表达式语句由表达式加上分号“;”组成。其一般形式为:
表达式;
执行表达式语句就是计算表达式的值。例如 c=a+a;
2) 函数调用语句
由函数名、实际参数加上分号“;”组成。其一般形式为:
函数名(实际参数表);
例如 printf("Hello !");
3) 控制语句
控制语句用于控制程序的流程,以实现程序的各种结构方式。它们由特定的语句定义符组成。C语言有九种控制语句。 可分成以下三类:
条件判断语句:if语句、switch语句;
循环执行语句:do while语句、while语句、for语句;
转向语句:break语句、goto语句、continue语句、return语句。
4) 复合语句
把多个语句用括号{}括起来组成的一个语句称复合语句。
在程序中应把复合语句看成是单条语句,而不是多条语句。例如:
{ x=y+z; a=b+c; printf("%d%d", x, a); } 定义的变量只在该复合//语句中起作用
5) 空语句
只有分号“;”组成的语句称为空语句。空语句是什么也不执行的语句。在程序中空语句可用来作空循环体。例如:while( getchar()!='\n' );
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
运算符的优先级:
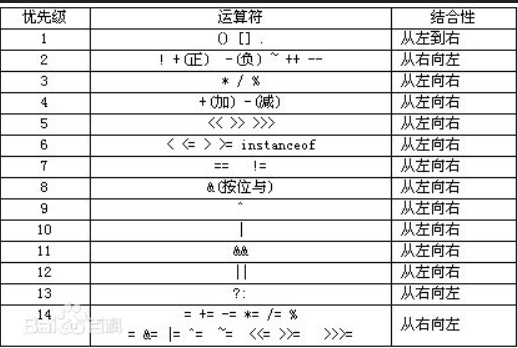
常用:
!>++ -- >* / % >+ - >== !=>& ^ | &&>=
即:非>算术运算符>逻辑运算符>赋值运算
数组:
为什么需要数组--à为了解决大量同类型数据的存储和使用问题。
数组的所有变量类型必须相同,不可能第一个元素是整型,第二个是浮点型。所有变量所占用的字节必须相等。
数组创建实例:
//例1
int arr1[10];
//例2
char arr2[10];
float arr3[10];
double arr4[10];
注意:数组创建 [ ] 中要给一个常量才可以,不能使用变量,不能为空,不能为0。
例如:
int count = 10;
int arr2[count];//不能正常创建
数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)。
int arr1[10] = {1,2,3};//不完全初始化默认没有初始化处为0
int arr2[ ] = {1,2,3,4};
int arr3[5] = {1,2,3,4,5};
char arr4[3] = {‘a’,98,’c’};
char arr5[ ] = {‘a’ , ‘b’ , ‘c’};
char arr6[ ] = “abcdef”;
….
数组的数组名其实就是数组首元素的地址。
因此,我们可以通过对数组名+整数的运算,就可以获得到数组中的每个元素的地址。
int i = 0;
int arr[10] = { 0 };
for (i = 0; i < sizeof(arr) / sizeof(arr[0]); ++i)
{
printf("$arr[%d] = %p\n", i, &arr[i]);
printf("%p\n", arr + i);
}
二维数组的初始化
二维数组的创建:
//数组创建
int arr[3][4];
char arr[3][5];
double arr[2][4];
//数组初始化
int arr[3][4] = { 1,2,3,4 };
int arr[3][4] = { {1,2},{4,5} };
int arr[][4] = { {2,3},{4,5} };
二维数组在内存中也是连续存储的。
输出/输入 字符串:
puts gets putchar getchar函数和的特点和区别。
puts( )函数用来向标准输出设备(屏幕)写字符串并换行, 其调用格式为: puts(s);
其中s为字符串变量(字符串数组名或字符串指针)地址,puts()函数的作用与语printf("%s\n", s)相同。
gets()函数用来从标准输入设备(键盘)读取字符串直到回车结束, 但回车符不e69da5e887aae799bee5baa6e997aee7ad9431333337393533属于这个字符串。其调用格式为: gets(s);
s为字符串变量(字符串数组名或字符串指针)。
gets(s)函数与scanf("%s", &s)相似, 但不完全相同, 使用scanf("%s", &s) 函数输入字符串时存在一个问题, 就是如果输入了空格会认为输入字符串结束, 空格后的字符将作为下一个输入项处理, 但gets() 函数将接收输入的整个字符串直到回车为止。
putchar函数只能用于单个字符的输出,且一次只能输出一个字符。getchar函数只能用于单个字符的输入,一次输入一个字符。程序的功能是输入一个字符,显示一个字符。
++a和a++的区别是什么?
加加a的意思是先加后取值。
a加加的意思是先取值后增加。
说一下c语言的头文件和用途。
头文件存放了原型函数的定义。这个文件又称为库文件。
比如说printf和scanf存放在stdio.h里面。
c语言中函数的通常格式是怎样的?
C语言的函数,包含4个部分。
返回值, 函数名, 参数, 函数体。
int test(imt y, int z)
{
return y+z;
什么是指针的指针?
指针的指针是指一个指向指针所在地址的指针。
int a=5, *x=&a, **y=&x;
C程序算法的意义是什么?
算法的意义在于提高程序的执行效率,是注重空间的节省,还是注重时间的节省,是写算法时需要考虑的因素。
}
能不能在整型中存放32768这个数?
整数类型可以存放从-32768~32767之间的任何数值。但是32768不在这个范围之内。这个时候modifier是我们需要的东西。Long Int数据类型就可以存放这个数。
在c语言中,什么时候会用到空指针?
有三种情况,在c语言中会用到空指针。
作为一个错误值。
作为一个监测值。
在一个递归数据结构中终止indirection。
在函数定义的时候何时用void?
当函数没有返回值时,可以用void。
什么是输出重定向?
输出重定向是指把程序的输出,除了输出在屏幕上以外的另外选择, 比如说,输出到一个文件里。
算法题:
1.题目:计算100以内所有奇数的和。
算法思想:通过C语言的循环结构,实现100以内所有奇数的和。将循环控制变量的初值设置为1,因为100以内的奇数是从1开始。在定义一个sum求和的变量,循环控制变量每次的增量为2,sum记录最终的和,当满足循环终止条件后,退出循环,并输出sum。

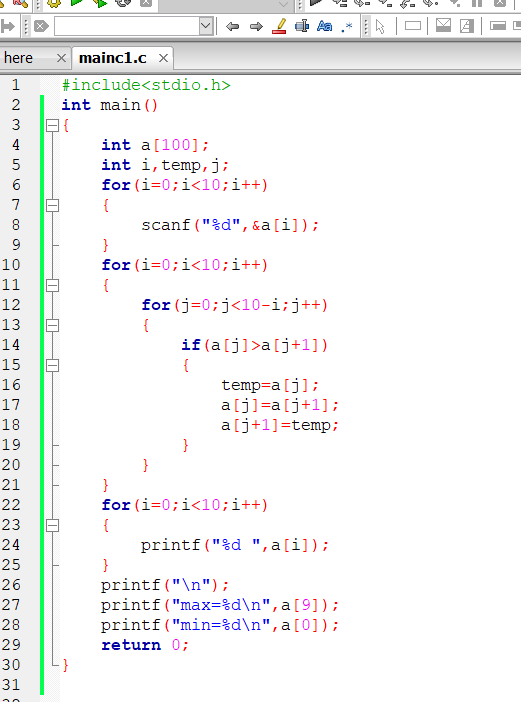
2.编写程序实现下述功能,从键盘中输入10个数,对这10个数,从小到大排序,并输出最大最小值。
算法思想:
① 首先我们使用循环语句,通过使用scanf函数,实现对10个数的输入。
② 通过使用排序算法,对10个数进行排序。(这里使用冒泡排序)
③ 最后将10个数按照从小到大的顺序,存放在数组里,并且输出最大最小值。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
指针:
指针的概念
指针变量的概念:
指针数组:
最基础的指针:
int a;
int *p=&a;
说明:声明了一个int 变量a,然后声明一个int 的指针,*p指向a的地址,&也就是取地址符号,而*是指针中,去内容的符号。
与const在一起的时候。
char * const p; // 指针不可改,也就说指针只能指向一个地址,不能更改为其他地址
char const * p; // 所指内容不可改,也就是说*p是常量字符串
char const * const p; // 内容和指针都不能改
const char * const p; // 同上...内容和指针不能改
说明:*在const右面就说明内容不能修改
*在const左面就说明就说明指针不能改。
2.区别三个指针运算:
*p++: 先取p的值,P再向后移一位
(*p)++ :先取p的值,p的值在+1
*(p++): 效果同*p++
3.指针和数组之间的联系
A.char a[10]=”china”;
B . char a[10],*p=a; p=”china”;
C . char *a;a=”china”;
D . char a[10],*p; p=a=”china;” 错误:数组名称是一个常量,不能赋值
4. 指针

5.指针的运算
7.关键字 的使用
static:①在函数内定义静态局部变量,该变量存在内存的静态区,所以即使该函数运行结束,静态变量的值也不会被销毁。
②静态变量只能在声明它的源文件中使用。
const:①声明常变量,使得指定的变量不能被修改。
例:const int a=5;//a的值一直是5,不能被修改
②修饰函数返回值,使得函数的返回值不能被修改。
③修饰函数形参,使得形参在函数内不能被修改。
extern:用于修饰变量或函数,表明该变量或函数都是在别的文件中定义的,提示编译器在其他文件中寻找定义。
sizeof:等于对象或类型所占的内存字节数。
8.
9.二维数组
万能公式:a[i]=*(a+i)

算法题:
- 排序算法:快速排序
基本思想:①先从数列中取出一个数作为基准数,一般选数列的第一个数作为基准。
②分区过程,将比这个数大的数全都放到它的右边,小于或等于它的数全都放在它的左边。
③再对左右区间重复上述操作,直到各区间只有一个数。
2.冒泡排序
冒泡法排序的算法:从数组头部开始,不断比较相邻的两个元素的大小,让较大的元素逐渐往后移动(交换两个元素的值),直到数组的末尾。
经过第一轮的比较,就可以找到最大的元素,并将它移动到最后一个位置。第一轮结束后,继续第二轮。
仍然从数组头部开始比较,让较大的元素逐渐往后移动,直到数组的倒数第二个元素为止。
经过第二轮的比较,就可以找到次大的元素,并将它放到倒数第二个位置。
以此类推,进行n-1(n 为数组长度)轮“冒泡”后,就可以将所有的元素都排列好。
int i,j,temp,a[n];
for( i=0;i<n-1;i++)
for( j=0;j<n-1-i;j++)
if(a[j]>a[j+1]){ //相邻两个元素作比较,如果前面元素大于后面,进行交换
temp = a[j+1];
a[j+1] = a[j];
a[j] = temp;
}
3.选择排序
每一次从待排序的数据元素中选出最小(或最大)的一个元素,
将其和数组第一个元素交换位置,
然后,再从剩余未排序元素中继续寻找最小(大)元素,
将其与数组第二个元素进行交换。以此类推,直到全部待排序的数据元素排完。
int i,j,temp,a[n],min;
for(int i=0;i<n-1;i++)
{
min=a[i];
for( j=i+1;j<n;j++)
if(a[min]>a[j])
min=j;
temp = a[i];
a[i] = a[min];
a[min] = temp;
}
4.哥德巴赫猜想:任何一个不小于6的偶数均可表示为两个奇素数之和。素数就是只能被1和自身整除的正整数。注意:1不是素数,2是素数。
又因为这样的分解不唯一(例如24可以分解为5+19,还可以分解为7+17),要求必须输出所有解中p最小的解。
算法描述:从主函数传递给函数一个大于等于六的偶数,设置一个变量i,让i的初值为2,大安小于等于要判断的数m除以2时,判断i是否为素数,若为素数继续判断m-i是否为素数,若m-i也为素数,则执行输出语句m=i + m-i,跳出循环即可。若i和m-i不全是素数,则让i自增1,继续判断i和m-i是否全为素数,直至成功输出,结果跳出循环即可。
# include <stdio.h>
# include <math.h>
int main()
{
int prime(int n);
void goldbach(int m);
int num;
int f=1;
while(f)
{
printf("input number:\n");
scanf("%d",&num);
if((num%2==0)&&(num>=6))
f=0;
else
printf("重新输入:\n");
}
goldbach(num);
return 0;
}
int prime(int n)
{
int i,flag=1;
if(n==1)
return 0;
for(i=2;i<=sqrt(n);i++)
{
if(n%i==0)
flag=0;
}
return flag;
}
void goldbach(int m)
{
int i,b;
for(i=2;i<=m/2;i++)
{
if(prime(i))
{
if(prime(m-i))
{
printf("%d=%d+%d\n",m,i,m-i);
break;
}
}
}
}
5,输出菲波拉契数列第n项(1,1,2,3,5,8…)
算法描述:从主函数中传给该函数需要输出的项数n,若n=1或2返回1,若n大于二,递归调用该函数,返会以n-1为参调用该函数与以n-2为参调用该函数的和。在主函数中输出结果。
int Fibon1(int n)
{
if (n == 1 || n == 2)
{
return 1;
}
else
{
return Fibon1(n - 1) + Fibon1(n - 2);
}
}
int main()
{
int n = 0;
int ret = 0;
scanf("%d", &n);
ret = Fibon1(n);
printf("ret=%d", ret);
return 0;
6.插入排序
插入排序的核心思想是:从头开始,每次头元素作为 “哨兵” 依次和后面的元素
进行比较,(假设从小到大排列)后面大的元素和“哨兵”比较,如果后面的元素比“哨兵”大则交换,每比较一
次,都会从比较位置,向首元素方向进行,因此,该排序算法效率并不高,时间复杂度为O(n2)
#include <stdio.h>
#define SWAP(X,Y) X=X+Y;Y=X-Y;X=X-Y
//按最坏的时间复杂度
int main(int argc, char *argv) {
int a[10] = {10,9,8,7,6,5,4,3,2,1};
for (int i = 1; i < 10; i++) {
int j = i;
while ((j > 0) && a[j] < a[j - 1])
{
SWAP(a[j], a[j - 1]);
j -= 1;
}
}
for (int i = 0; i < 10; i++) {
printf("%d ",a[i]);
}
printf("\n");
}
//快速排序
void quick_sort(int s[], int l, int r)
{
if (l < r)
{
//Swap(s[l], s[(l + r) / 2]); //将中间的这个数和第一个数交换 参见注1
int i = l, j = r, x = s[l];
while (i < j)
{
while(i < j && s[j] >= x) // 从右向左找第一个小于x的数
j--;
if(i < j)
s[i++] = s[j];
while(i < j && s[i] < x) // 从左向右找第一个大于等于x的数
i++;
if(i < j)
s[j--] = s[i];
}
s[i] = x;
quick_sort(s, l, i - 1); // 递归调用
quick_sort(s, i + 1, r);
}
}
2.将大写字母转换为小写字母 ASCII+32

DAY4
关于函数: ①函数就是C语言的模块,一块一块的,有较强的独立性,可以相互调用。②函数就是一系列的C语句的集合,能完成某个特定的功能。需要该功能的时候直接调用该函数即可。方便代码重用。③函数有利于程序的模块化,这实际上就是面向过程的思想。面向过程语言的最基本单位不是语句,而是函数。
④包含了一个函数头和一个函数块。
函数头指定了函数的名称,返回值的类型以及参数的类型和名称(如果参数有的话);函数块中的语句明确了该函数要做的事。
⑤C语言不仅提供了极为丰富的库函数,还允许用户定义自己的函数,用户可以将自己的算法编成一个个相对独立的模块,

⑥类型即返回值类型,可以是void或者任何对象类型,但不可以是数组类型。
参数声明,是一个以逗号分隔、由函数参数声明组成的列表。如果该函数没有参数需要传入,则这个列表可以为空,或者仅有关键字void。
⑦递归必须要满足的两个条件就是:要有递归公式+要有终止条件
递归的优缺点:
优点:简化程序设计、结构简洁清晰、可读性强、容易理解
缺点:速度慢,运行效率低,对存储空间的占用比循环多。
⑧如果函数的实参是变量的地址,那么函数就可以通过指针直接获取该原始变量,并修改原始变量的值。
关于文件:文件是数据源的一种,最主要的作用是保存数据。
①
l 通常把显示器称为标准输出文件,printf就是向文件输出数据。
l 通常把键盘称为标准输入文件,scanf就是从这个文件读取数据。

② 打开文件获取文件的有关信息
文件名、文件状态、当前读写位置等,这些文件会保存到一个FILE类型的结构体变量中。
③ 关闭文件就是断开与文件之间的联系,释放结构体变量,同时禁止对该文件进行操作。
④ 打开文件:
FILE *fp = fopen("D:\\demo.txt","rb+");
⑤ 关闭文件:
int fclose(FILE *fp);
⑥ 字符读取函数fgetc
fgetc 是 file get char 的缩写,意思是从指定的文件中读取一个字符。fgetc() 的用法为:
int fgetc (FILE *fp);
⑦ 字符写入函数fputc
fputc 是 file output char 的所以,意思是向指定的文件中写入一个字符。fputc() 的用法为:
int fputc ( int ch, FILE *fp );
⑧ 以块数据的方式读写文件
fread() 函数用来从指定文件中读取块数据。所谓块数据,也就是若干个字节的数据,可以是一个字符,可以是一个字符串,可以是多行数据,并没有什么限制。fread() 的原型为:
size_t fread ( void *ptr, size_t size, size_t count, FILE *fp );
fwrite() 函数用来向文件中写入块数据,它的原型为:
size_t fwrite ( void * ptr, size_t size, size_t count, FILE *fp );

 浙公网安备 33010602011771号
浙公网安备 33010602011771号