常用模块
一. random模块
1.取随机小数
1.1random.random() 取0-1之间的随机小数
1 print(random.random())
2 # 0.38718361352206576
3 # 0.11848180963339394
1.2 random.uniform(a,b) 取a-b之间的随机小数
1 print(random.uniform(1,3))
2 # 2.2563287106900045
3 # 1.8587743420445906
2.取随机整数
功能:彩票,抽奖
1 random.randint(a,b) 取a-b之间的随机整数,顾头也顾尾
1 print(random.randint(1,5))
2 # 5
3 # 3
2.2random.randrange(a,b,c) 在a-b之间没隔c个数之间的数随机取值,顾头不顾尾
1 print(random.randrange(1,10,2))
2 # 9
3 # 1
3.从列表中随机抽取一个值
功能:抽奖
3.1 random.choic() 从列表中随机抽取一个值
1 lis=['a','b',(1,2,3),2]
2 print(random.choice(lis))
3 # 2
4 # b
3.2 random.sample(a,b) 从a列表中随机抽取b个值
1 lis=['a','b',(1,2,3),2]
2 print(random.sample(lis,2))
3 # [(1, 2, 3), 2]
4 # ['b', 2]
4. 打乱列表顺序
功能:洗牌
1 lis=['a','b',(1,2,3),2] #是改变原列表的顺序,而不是产生新的列表,为了节省空间
2 random.shuffle(lis)
3 print(lis) #['b', 2, (1, 2, 3), 'a']
例题:随机生成验证码
四位数字验证码:


1 s=''
2 for i in range(4):
3 a=random.randint(0,9)
4 s+=str(a)
5 print(s)
六位数字验证码:
1 s=''
2 for i in range(6):
3 a=random.randint(0,9)
4 s+=str(a)
5 print(s)
函数版本的数字验证码:
1 def func(n):
2 s=''
3 for i in range(n):
4 a=random.randint(0,9)
5 s+=str(a)
6 print(s)
7 func(4)
8 func(6)
六位数字和字母的验证码:
1 s=''
2 for i in range(6):
3 alpha_upper=random.randint(97,122)
4 alpha_lower=random.randint(65,90)
5 num=random.randint(0,9)
6 result=random.choice([chr(alpha_upper),chr(alpha_lower),num])
7 s+=str(result)
8 print(s)
函数版本
1 def func(n=4):
2 s=''
3 for i in range(n):
4 alpha_upper=random.randint(97,122)
5 alpha_lower=random.randint(65,90)
6 num=random.randint(0,9)
7 result=random.choice([chr(alpha_upper),chr(alpha_lower),num])
8 s+=str(result)
9 print(s)
10 func(4)
11 func(6)
可以选择是否要字母的函数版
1 def func(n=6,alpha=True):
2 import random
3 s=''
4 for i in range(n):
5 if alpha==True:
6 alpha_upper=chr(random.randint(65,90))
7 alpha_lower=chr(random.randint(97,122))
8 num=random.randint(0,9)
9 resule=random.choice([alpha_upper,alpha_lower,str(num)])
10 s+=resule
11 else:
12 num = random.randint(0, 9)
13 s += str(num)
14 return s
15 print(func(n=4,alpha=False))
发红包
1 def func(money,num):
2 # import random
3 # lis=[]
4 # for i in range(int(num)):
5 # d=random.uniform(0,int(money))
6 # lis.append(d)
7 # lis=sorted(lis)
8 # # print(lis)
9 # for i in range(int(num)):
10 # content=input('请输入抢:')
11 # if content=='抢':
12 # if i==0:
13 # print(lis[0])
14 # else:
15 # print(lis[i]-lis[i-1])
16 # else:
17 # print('输入错误!')
18 # func(100,10)
二.时间模块(time)
时间格式:
字符串数据类型 格式化时间:2018-8-18 2018/08/18
结构化时间
时间戳时间 浮点型数据类型 154655862586.656463
时间戳时间是计算机能够识别的时间,字符串时间是人能看懂的时间,结构化时间是用来操作时间的
时间戳.时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
print(time.time()) #1534754474.7657013
字符串
1 print(time.strftime('%Y-%m-%d %H:%M:%S')) #2018-08-20 16:54:31
结构化时间
1 print(time.localtime()) #time.struct_time(tm_year=2018, tm_mon=8, tm_mday=20, tm_hour=16, tm_min=56, tm_sec=15, tm_wday=0, tm_yday=232, tm_isdst=0)
2 struct_time=time.localtime()
3 print(struct_time)
4 print(struct_time.tm_mon) #8
5 tm_wday=0是一周的第几天,周一是第零天
时间格式之间的转换:
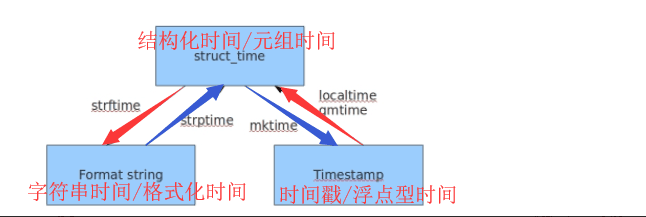
把时间戳时间1434757080.275697转换成字符串时间
1 struct_time=time.localtime(1434757080.275697)
2 print(time.strftime('%Y-%m-%d %H:%M:%S',struct_time))
把字符串时间1434757080.275697转换成时间戳时间
1 struct_time=time.strptime('2015-06-20 07:38:00','%Y-%m-%d %H:%M:%S')
2 print(time.mktime(struct_time))
计算时间差:
1 struct_time1=time.strptime('2018-8-8','%Y-%m-%d')
2 a=time.mktime(struct_time1)
3 struct_time2=time.strptime('2016-6-9','%Y-%m-%d')
4 b=time.mktime(struct_time2)
5 c=a-b
6 print(c)
7 struct_time3=time.gmtime(c)
8 print(struct_time3.tm_year)
9 print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time3.tm_year-1970,struct_time3.tm_mon-1,
10 struct_time3.tm_mday-1,struct_time3.tm_hour,
11 struct_time3.tm_min,struct_time3.tm_sec))
三.sys模块(和python解释器打交道)
1.sys.argv #argv的第一个参数是python这个命令后面的值,在cmd或terminal中可以验证
sys.argv的作用就是可以避免程序一开始就停下来,利于抢占CPU
1 print(sys.argv)
2 user=sys.argv[1]
3 pwd=sys.argv[2]
4 if user=='a' and pwd=='b':
5 print('成功')
6 else:
7 print('失败')
2.sys.path(显示导入的模块所在的位置路径,但不能直接找到,而是他的上一层)
1 print(sys.path)
模块是存在在硬盘上的,一但import了这个模块,这个模块才会到内存中,一个模块能否顺利导入全看sys.path中有没有这个模块存在
自定义模块导入模块的时候,需要关注sys.path
3.sys.modules
1 print(sys.modules) #是我们导入到内存中所有模块的名字
2 print(sys.modules['re']) #<module 're' from 'C:\\Program Files\\Python36\\lib\\re.py'>
四.os模块(和操作系统交互的模块)
1.文件夹/文件相关
1 os.makedirs('dir1/dir2')#创建多个文件夹(多层)
2 os.mkdir('dir3') #只能创建单个文件夹
3 os.rmdis('dir1/dir2') #只能删除单个文件夹
4 os.removedirs('dir1/dir2') #可以删除多个多层文件,若dir1下除了dir2还有其他文件不删dir1
5 os.listdir('C:/Users') #显示当前文件夹下的所有文件和子目录
6 os.remove() #删除一个文件
7 os.rename() #重命名一个文件
8 os.stat() #获取文件的相关信息
1 st_mode: inode 保护模式
2 st_ino: inode 节点号。
3 st_dev: inode 驻留的设备。
4 st_nlink: inode 的链接数。
5 st_uid: 所有者的用户ID。
6 st_gid: 所有者的组ID。
7 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
8 st_atime: 上次访问的时间。
9 st_mtime: 最后一次修改的时间。
10 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
2.操作系统命令相关
1 os.system('dir') #执行的是字符串类型的命令行代码(shell命令),没有返回值 (exec) 2 os.popen('dir') #执行的是字符串类型的命令行代码(shell命令) ,并获取执行结果 (eval)
3 os.getcwd() #current work dir获取当前工作目录
4 os.chdir('D:') 切换当前的工作目录
3.路径相关
1 功能1:把路径中不符合规范的'/'改成操作系统默认的格式(Windows默认的是'\',Linux默认的是'/')
2 path=os.path.abspath('C:/Users/Administrator/PycharmProjects/untitled3/day18w4/练习.py')
3 print(path) #C:\Users\Administrator\PycharmProjects\untitled3\day18w4\练习.py
4
5 功能2:把能够找到的相对路径改成绝对路径
6 path=os.path.abspath('练习.py')
7 print(path) #C:\Users\Administrator\PycharmProjects\untitled3\day18w4\练习.py
1 os.path.split() #把一个路径分成两段得到的是一个元组,元组的第二项是路径的最后一段(文件或文件夹)
2 os.path.dirname() #os.path.split()的第一项
3 os.path.basename() ##os.path.split()的第二项
4 os.path.exists() #判断文件或文件夹是否存在 用于用户登录代码中,防止用户第二次登录时再次创建文件而发生错误
5 os.path.isabs() #判断一个路径是否是绝对路径
6 os.path.isdir() #判断这个路径找到的是不是一个文件夹
7 os.path.isfile() #判断这个路径找到的是不是一个文件
8 '\@'.join(path) #将''中的每一个东西拼接到给的路径的每一个元素后面,不包括\/
9 os.path.join('c:', path) # 将两个路径拼接成一个路径,与上面不同的是这个可以兼容linx(/)和windows(\)
10 os.path.getatime() #返回这个文件的最后访问时间
11 os.path.getmtim() #返回这个文件的最后修改时间
12 os.path.getsize() #查看文件大小(所有的文件夹至少都是4096个字节)
使用python代码来统计一个文件夹中所有文件的大小
def func(path):
size=0
name_list=os.listdir(path)
for name in name_list:
path_abs=os.path.join(path,name)
if os.path.isdir(path_abs):
size_inner=func(path_abs)
size +=size_inner
else:
size+=os.path.getsize(path_abs)
return size
ret=func('C:/Users/Administrator/PycharmProjects/untitled3')
print(ret)
1 lst=[r'C:/Users/Administrator/PycharmProjects/untitled3',]
2 # size_sum=0
3 # while lst:
4 # path=lst.pop()
5 # path_list=os.listdir(path)
6 # for name in path_list:
7 # abs_path=os.path.join(path,name)
8 # if os.path.isdir(abs_path):
9 # lst.append(abs_path)
10 # else:
11 # size_sum+=os.path.getsize(abs_path)
12 # print(size_sum)
五.序列化模块
为什么要序列化
为什么要把其他数据类型转换成字符串呢
能够在网络上传输的只能是bytes,能够存储在文件里的只有bytes和str
1.json模块
在内存中做数据转换
1 json.dumps() #序列化
2 json.loads() #反序列化
3
4 # dic={'专业的':'我','业余的':'别人'}
5 # ret=json.dumps(dic,ensure_ascii=False) #序列化
6 # print(ret) #{"\u4e13\u4e1a\u7684": "\u6211", "\u4e1a\u4f59\u7684": "\u522b\u4eba"}
7
8 # ret1=json.loads(ret) #反序列化
9 # print(ret1) #{'专业的': '我', '业余的': '别人'}
1 # 向文件中记录字典
2 # dic={'专业的':'我','业余的':'别人'}
3 # ret=json.dumps(dic,ensure_ascii=False)
4 # with open('json_file','a',encoding='utf-8') as f:
5 # f.write(ret) #{"专业的": "我", "业余的": "别人"}
6
7 #从文件中读取文件
8 # with open('json_file','r',encoding='utf-8') as f:
9 # str_dic=f.read()
10 # print(json.loads(str_dic)) #{'专业的': '我', '业余的': '别人'}
11 # 可以在json_file的字典中手动添加其他的键值对,但是引号必须要用双引号,单引号是不识别的而且会报错
直接将数据类型写入文件
1 json.dump()
2 json.load()
3 # 直接将数据类型写入文件
4 # dic={'专业的':'我','业余的':'别人'}
5 # with open('json_file','a',encoding='utf-8') as f:
6 # json.dump(dic,f)
7
8 # with open('json_file','r',encoding='utf-8') as f:
9 # print(json.load(f))
json的dump和load是直接操作文件的,而dumps和loads是操作内存的
但是json模块能够处理的数据类型是非常有限的:字符串,列表,字典(字典中的可以只能是字符串),int,如果是其他数据类型的话,无法精确的反序列化
因为这些数据类型在所有语言中都是通用的,在python中序列化了,在Java等其他语言环境中也可以反序列化
1 dic={'专业的':'我','业余的':'别人'}
2 # with open('json_file','a',encoding='utf-8') as f:
3 # json.dump(dic,f)
4 # json.dump(dic,f)
5 # json.dump(dic,f)
6 # json.dump(dic,f)
7 # with open('json_file','r',encoding='utf-8') as f:
8 # print(json.load(f))#支持多次dump,但不支持多次load
9
10 # dic={'专业的':'我','业余的':'别人'}
11 # with open('json_file','a',encoding='utf-8') as f:
12 # str_dic=json.dumps(dic)
13 # f.write(str_dic+'\n')
14 # f.write(str_dic+'\n')
15 # f.write(str_dic+'\n')
16 # with open('json_file','r',encoding='utf-8') as f:
17 # for line in f:
18 # print(json.loads(line.strip()))
1 data = {'username':['李华','二愣子'],'sex':'male','age':16}
2 json_dic2 = json.dumps(data,sort_keys=True,indent=4,separators=(',',':'),ensure_ascii=False)
3 print(json_dic2)
2.pickle模块 (只能在python中使用)
⑴pickle支持在python中的几乎所有数据类型
1 dic={(1,2,3):{'a','b'},1:'abc'}
2 ret=pickle.dumps(dic) #
⑵ dumps序列化的结果只能是字节,此时的字节解码了也看不懂,只有pthon能认识
1 dic={(1,2,3):{'a','b'},1:'abc'}
2 ret=pickle.dumps(dic) #
3 # print(ret) #b'\x80\x03}q\x00(K\x01K\x02K\x03\x87q\x01cbuiltins\nset\nq\x02]q\x03(X\x01\x00\x00\x00bq\x04X\x01\x00\x00\x00aq\x05e\x85q\x06Rq\x07K\x01X\x03\x00\x00\x00abcq\x08u.'
4 ret1=pickle.loads(ret)
5 print(ret1) #{(1, 2, 3): {'a', 'b'}, 1: 'abc'}
⑶ 只能在python中使用
1 dic={(1,2,3):{'a','b'},1:'abc'}
2 with open('pickle_file','wb') as f:
3 pickle.dump(dic,f)
4 �}q (KKK�qcbuiltins
5 set
6 q]q(X bqX aqe�qRqKX abcqu.
7
8 with open('pickle_file','rb') as f:
9 ret=pickle.load(f)
10 print(ret) #{(1, 2, 3): {'a', 'b'}, 1: 'abc'}
⑷在和文件操作的时候,需要用rb,wb的模式打开文件
(5)pickle可以多次dump和load
1 dic1={(1,2,3):{'a','b'},1:'abc'}
2 dic2={(1,2,3):{'a','b'},2:'abc'}
3 dic3={(1,2,3):{'a','b'},3:'abc'}
4 with open('pickle_file','wb') as f:
5 pickle.dump(dic1,f)
6 pickle.dump(dic2,f)
7 pickle.dump(dic3,f)
8 with open('pickle_file','rb') as f:
9 ret=pickle.load(f)
10 print(ret)
11 ret = pickle.load(f)
12 print(ret)
13 ret = pickle.load(f)
14 print(ret)
15 {(1, 2, 3): {'b', 'a'}, 1: 'abc'}
16 {(1, 2, 3): {'b', 'a'}, 2: 'abc'}
17 {(1, 2, 3): {'b', 'a'}, 3: 'abc'}
18
19 with open('pickle_file','rb') as f:
20 while True:
21 try:
22 ret = pickle.load(f)
23 print(ret)
24 except EOFError:
25 break
26 {(1, 2, 3): {'a', 'b'}, 1: 'abc'}
27 {(1, 2, 3): {'a', 'b'}, 2: 'abc'}
28 {(1, 2, 3): {'a', 'b'}, 3: 'abc'}
改变世界,改变自己!
