爬虫
常用语法
最常见的Markdown格式选项和键盘快捷键 [3] :
| 输出后的效果 | Markdown | 快捷键 |
|---|---|---|
| Bold | text | Ctrl/⌘ + B |
| Emphasize | text | Ctrl/⌘ + I |
| Link | title | Ctrl/⌘ + K |
| Inline Code | code |
Ctrl/⌘ + Shift + K |
| Image | Ctrl/⌘ + Shift + I | |
| List | * item | Ctrl + L |
| Blockquote | > quote | Ctrl + Q |
| H1 | # Heading | |
| H2 | ## Heading | Ctrl/⌘ + H |
| H3 | ### Heading | Ctrl/⌘ + H (x2) |
标题
标题能显示出文章的结构。行首插入1-6个 # ,每增加一个 # 表示更深入层次的内容,对应到标题的深度由 1-6 阶。
-
H1 :# Header 1
-
H2 :## Header 2
-
H3 :### Header 3
-
H4 :#### Header 4
-
H5 :##### Header 5
-
H6 :###### Header 6
文本样式
(带“*”星号的文本样式,在原版Markdown标准中不存在,但在其大部分衍生标准中被添加)
-
链接 :Title
-
加粗 :*Bold*
-
斜体字 :*Italics*
-
*高亮 :==text==
-
段落 : 段落之间空一行
-
换行符 : 一行结束时输入两个空格
-
列表 :* 添加星号成为一个新的列表项。
-
引用 :> 引用内容
-
内嵌代码 :
alert('Hello World'); -
画水平线 (HR) :--------
-
方框:- [ ] -
图片
使用Markdown将图像插入文章,你需要在Markdown编辑器输入 。 这时在预览面板中会自动创建一个图像上传框。你可以从电脑桌面拖放图片(.png, .gif, .jpg)到上传框, 或者点击图片上传框使用标准的图像上传方式。 如果你想通过链接插入网络上已经存在的图片,只要单击图片上传框的左下角的“链接”图标,这时就会呈现图像URL的输入框。想给图片添加一个标题, 你需要做的是将标题文本插图中的方括号,e.g;.
脚注
脚注不存在于标准Markdown中。
使用这样的占位符号可以将脚注添加到文本中:1. 另外,你可以使用“n”而不是数字的n所以你可以不必担心使用哪个号码。在您的文章的结尾,你可以如下图所示定义匹配的注脚,URL将变成链接:
`这里是脚注[^1]``[^1]: 这里是脚注的内容` `这里是脚注[^n]``[^n]: 这里是脚注的内容`
写代码
添加内嵌代码可以使用一对回勾号 alert('Hello World').对于插入代码, Ghost支持标准的Markdown代码和GitHub Flavored Markdown (GFM) [4] 。标准Markdown基于缩进代码行或者4个空格位:
` ``<``header``> `` ``<``h1``>{{title}}</``h1``>`` ``</``header``>`
GFM 使用三个回勾号```
`´´´``<``header``>`` ``<``h1``>{{title}}</``h1``>``</``header``>`
层级
用'-'和缩进控制
二.jupyter应用:基于浏览器的可视化工具
注:需要anaconda 集成环境
1.快捷键
Shift+Enter : 运行本单元,选中下个单元 Ctrl+Enter : 运行本单元 Alt+Enter : 运行本单元,在其下插入新单元 shift+tab : 打开帮助文档 Y:单元转入代码状态 M:单元转入markdown状态 A :在上方插入新单元 B:在下方插入新单元 X:剪切选中的单元 Shift +V:在上方粘贴单元
2.可视化工具的运行
选择 jupyter
默认浏览器会直接启动(或输入jupyter notebook 启动)
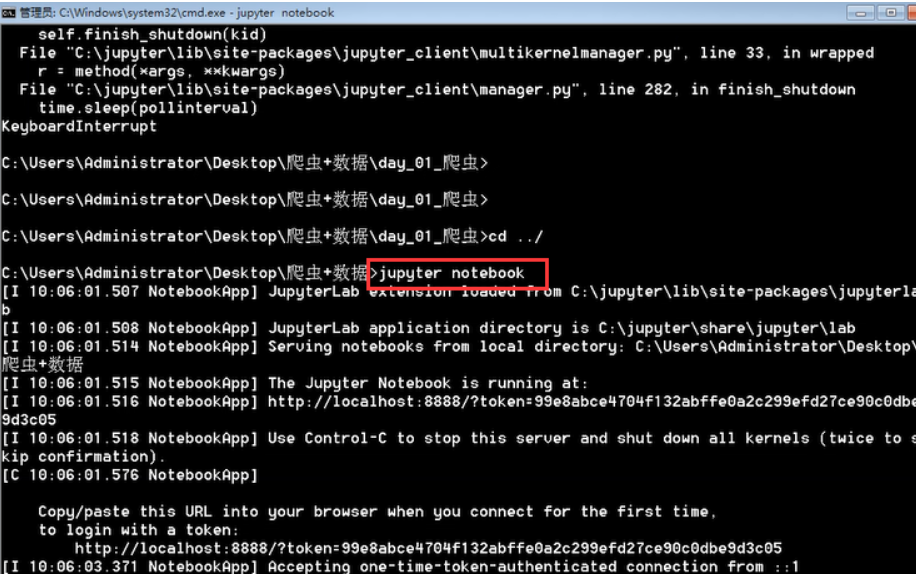
得到可视化工具页面

3.代码只要在同一个原文件中就可以,没有上下之分

注:等号前要有空格
三.爬虫
1.定义
通过编写程序,模拟浏览器上网,让其去互联网上爬取数据的过程
2.分类
- 通用爬虫 :常用于搜索引擎中 - 聚焦爬虫 :爬取局部数据 - 增量式 :只爬取最新的内容
3.反爬机制
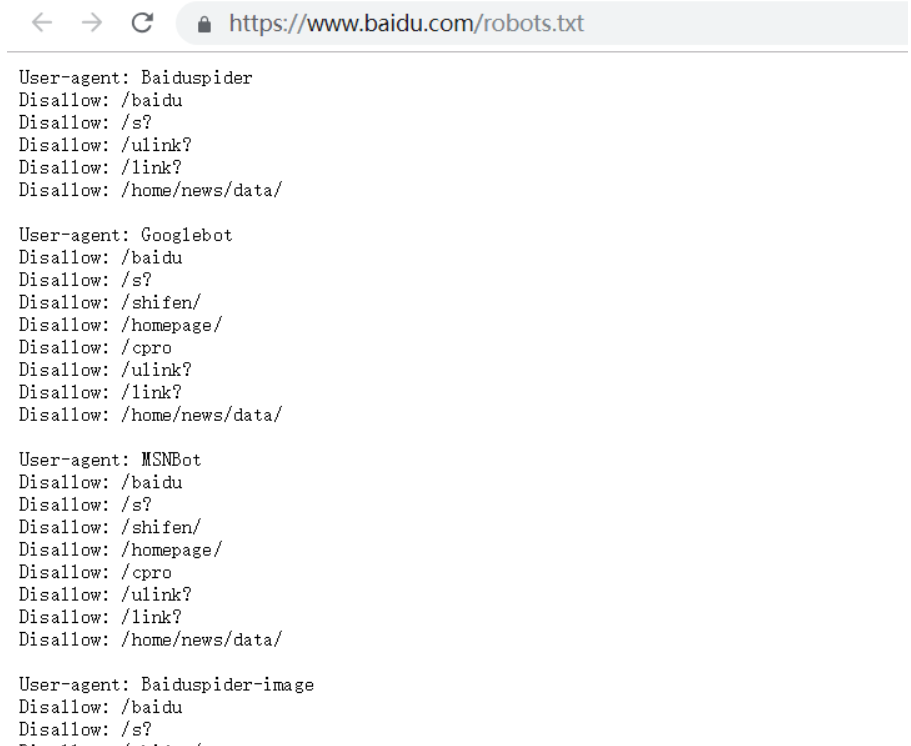
##反爬机制一
robots.txt协议:第一个反爬机制,一个网站约束了什么数据可爬,什么数据不可爬
4.folder:软件形式的抓包工具
打开(双击)
配置
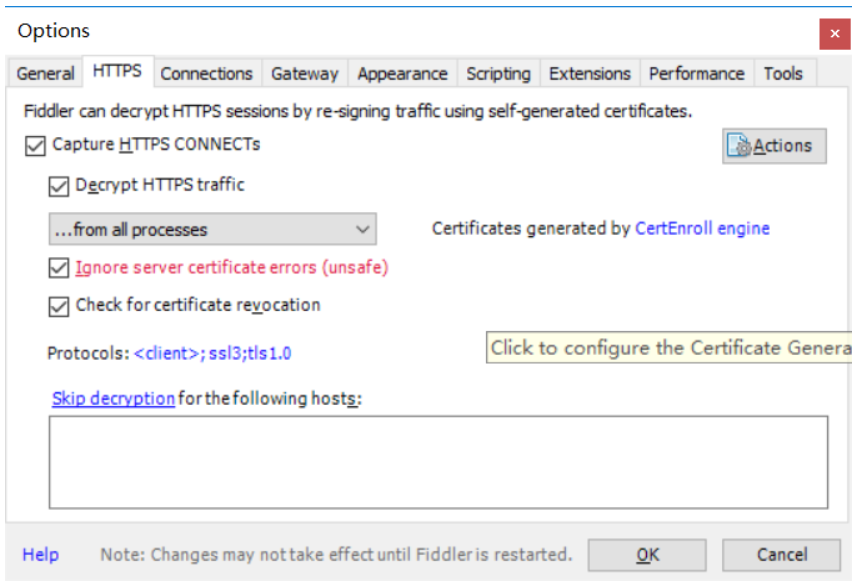
选择tools中的options
https配置
重启fiddler
功能
请求头信息
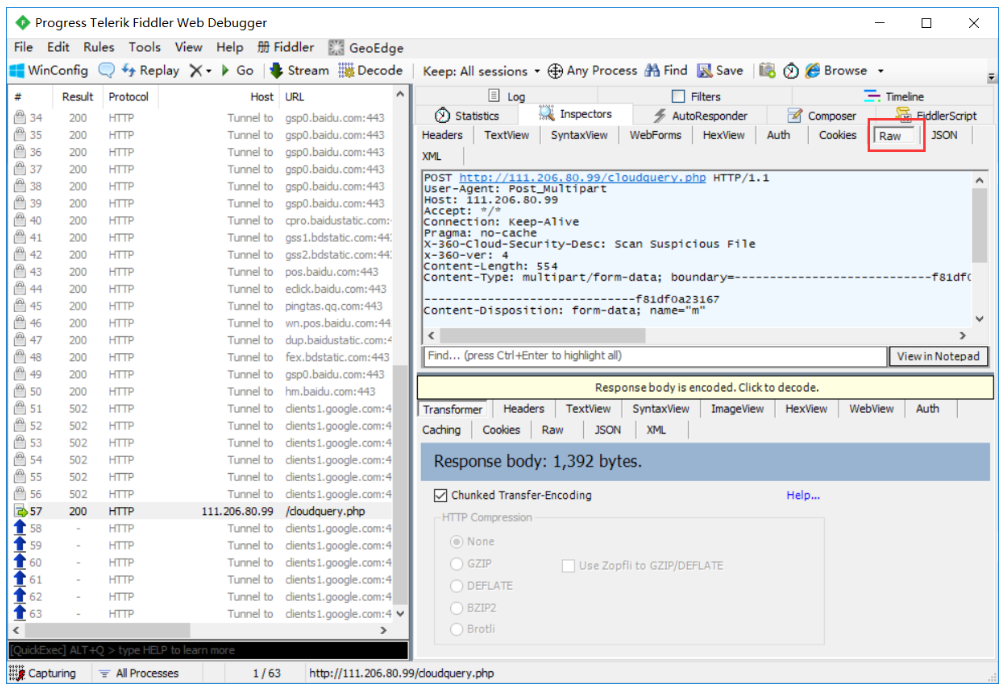
当前请求所携带的参数

响应头信息
响应的json数据
向右箭头代表post请求,向左代表get请求

5.http和https协议
常用的请求头信息
User-Agent:请求载体的身份标识 Connection:close/keep alive #连接的状态
常用的相应头信息
Content-Type:告诉浏览器返回的数据类型
四.requests模块的使用
1.request模块代码编写流程
1.指定url 2.发起请求 3.获取相应对象中的数据 4.持久化存储
2.抓取搜狗指定词条相关页面
import requests url='https://www.sogou.com/web' content=input("请输入搜索内容:") params={ "query":content } #指定url,发起请求 response=requests.get(url=url,params=params).text#获取相应对象中的数据 with #持久化存储open('./sogou.html','w',encoding='utf-8') as f: f.write(response) print("爬取完成!!!") 注:不同参数的数据格式 .txt #以字符串形式存储 .content #存储二进制数据 .json() #获取json字符串
3.抓取百度翻译相关页面
import requests url='https://fanyi.baidu.com/sug' content=input("请输入翻译内容:") params={ "kw": content } response=requests.get(url=url,params=params).json() print(response) print("爬取完成!!!") #结果 请输入翻译内容:美少女 {'errno': 0, 'data': [{'k': '美少女', 'v': 'beautiful young girl;nymph;'}, {'k': '美少女战士', 'v': 'Sailor Moon;'}]} 爬取完成!!!
4.抓取豆瓣电影数据
import requests url='https://movie.douban.com/j/chart/top_list' params={ "type": "5", "interval_id": "100:90", "action":"", "start": "1", "limit": "100" } response=requests.get(url=url,params=params).json() print(response) print("爬取完成!!!")
5.获取肯德基指定地点餐厅数量信息
import requests url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' content=input("请输入要查询的地址:") params={ "cname": "", "pid": "", "keyword": content, "pageIndex": "1", "pageSize": "10", } response=requests.get(url=url,params=params).json() print(response) #结果 #请输入要查询的地址:北京 {'Table': [{'rowcount': 69}], 'Table1': [{'rownum': 1, 'storeName': '育慧里', 'addressDetail': '小营东路3号北京凯基伦购物中心一层西侧', 'pro': 'Wi-Fi,店内参观,礼品卡', 'provinceName': '北京市', 'cityName': '北京市'}, {'rownum': 2, 'storeName': '京通新城', 'addressDetail': '朝阳路杨闸环岛西北京通苑30号楼一层南侧', 'pro': 'Wi-Fi,店内参观,礼品卡,生日餐会', 'provinceName': '北京市', 'cityName': '北京市'}, {'rownum': 3, 'storeName': '黄寺大街', 'addressDetail': '黄寺大街15号北京城乡黄寺商厦', 'pro': 'Wi-Fi,店内参观,礼品卡,生日餐会', 'provinceName': '北京市', 'cityName': '北京市'}, {'rownum': 4, 'storeName': '四季青桥', 'addressDetail': '西四环北路117号北京欧尚超市F1、B1', 'pro': 'Wi-Fi,店内参观,礼品卡,生日餐会', 'provinceName': '北京市', 'cityName': '北京市'}, {'rownum': 5, 'storeName': '亦庄', 'addressDetail': '北京经济开发区西环北路18号F1+F2', 'pro': 'Wi-Fi,店内参观,礼品卡,生日餐会', 'provinceName': '北京市', 'cityName': '北京市'}, {'rownum': 6, 'storeName': '石园南大街', 'addressDetail': '通顺路石园西区南侧北京顺义西单商场石园分店一层、二层部分', 'pro': 'Wi-Fi,店内参观,礼品卡', 'provinceName': '北京市', 'cityName': '北京市'}, {'rownum': 7, 'storeName': '北京站广场', 'addressDetail': '北京站一层', 'pro': '礼品卡', 'provinceName': '北京市', 'cityName': '北京市'}, {'rownum': 8, 'storeName': '北京南站', 'addressDetail': '北京南站候车大厅B岛201号', 'pro': '礼品卡', 'provinceName': '北京市', 'cityName': '北京市'}, {'rownum': 9, 'storeName': '北清路', 'addressDetail': '北京北清路1号146区', 'pro': 'Wi-Fi,店内参观,礼品卡', 'provinceName': '北京市', 'cityName': '北京市'}, {'rownum': 10, 'storeName': '大红门新世纪肯德基餐厅', 'addressDetail': '海户屯北京新世纪服装商贸城一层南侧', 'pro': 'Wi-Fi,店内参观,礼品卡', 'provinceName': '北京市', 'cityName': '北京市'}]}
6.抓取生产许可证相关数据
##反爬机制二:User-Agent
import requests id_list=[] url='http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList' headers={ "User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36' } page=input("查询几页:") for i in range(1,int(page)+1): params={ "on": "true", "page": i, "pageSize": "15", "productName": "", "conditionType": "1", "applyname": "", "applysn": "", } object_list=requests.post(url=url,params=params,headers=headers).json()["list"] for object in object_list: id_list.append(object["ID"]) for id in id_list: url='http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById' params={ "id": id } response=requests.post(url=url,params=params,headers=headers).json() print(response)
注:第二个反爬机制,UA反爬
反爬方式:模拟浏览器的useragent
7.爬取图片内容
方式一:通过requests模块
import requests url='https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=1695604879,3405317932&fm=26&gp=0.jpg' response=requests.get(url=url).content with open('./meishaonv.jpg','wb') as f: f.write(response) print('爬取完成!!!')
方式二:通过urllib模块
import urllib url='https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=1695604879,3405317932&fm=26&gp=0.jpg' urllib.request.urlretrieve(url=url,filename='meishaonv2.jpg')
五.数据解析
1.通过正则解析
(1)正则模块补充
re.M 多行匹配
import re content=''' sadasf sdgdfg sdgfd tghj ''' re.findall("^s.*",content,re.M) #['sadasf', 'sdgdfg', 'sdgfd']
re.S 整体作为一行匹配
import re content=''' sadasf sdgdfg sdgfd tghj ''' re.findall("^.*",content,re.S) #['\nsadasf\nsdgdfg\nsdgfd\ntghj\n']
re.I 忽略大小写
import re content='''sadasf sdgdfg sdgfd tghj ''' re.findall("^S",content,re.I)
(2)爬取糗事百科中所有图片
import re content='''sadasf sdgdfg sdgfd tghj ''' re.findall("^S",content,re.I)
2.通过bs4解析
(1)环境准备
pip3 install lxml #解析器 pip3 install bs4
(2)bs4的解析原理
1.将要进行解析的原码加载到bs对象 2.调用bs对象中相关的方法或属性进行原码中相关标签的定位 3.将定位到的标签之间存在的文本或属性值提取
(3)bs4的方法与属性
(1)根据标签名查找 soup.a 只能找到所有符合要求的标签第一个 (2)获取属性(值) soup.a.attrs 获取a的所有属性和属性值,返回一个字典 soup.a.attrs['href'] 获取a的href属性值 soup.a["href"] 获取a的href属性值的简写 (3)获取内容 soup.a.string 获取a标签中直系文本数据 soup.a.text 获取a标签的非直系文本数据 soup.a.get_text() 同上 (4)找到第一个符合要求的标签 soup.find('a') 找到第一个a标签 soup.find('a',title='xxx') soup.find('a',alt='xxx') soup.find('a',class_='xxx') soup.find('a',id='xxx') (5)找到所有符合要求的标签 soup.find_all('a') 找到所有a标签 soup.find_all('a',title='xxx') soup.find_all('a',alt='xxx') soup.find_all('a',class_='xxx') soup.find_all('a',id='xxx') (6)根据选择器选择指定的内容(返回值永远是列表) select:soup.select("#xxx") 常见选择器: 标签选择器:(a) 类选择器:(.) id选择器:(#) 层级选择器: div .dudu #gh .name div>p>.acd>#hjk
(4)爬取诗词名句网的三国演义
import requests from bs4 import BeautifulSoup url='http://www.shicimingju.com/book/sanguoyanyi.html' headers={ "User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36' } response_str=requests.get(url=url,headers=headers).text soup=BeautifulSoup(response_str,'lxml') title_list=soup.select('.book-mulu > ul > li > a') with open('sanguoyanyi.txt','w',encoding='utf-8') as f: for title in title_list: title_str=title.string f.write(title_str) content_url='http://www.shicimingju.com'+title['href'] content=requests.get(url=content_url,headers=headers).text soup=BeautifulSoup(content,'lxml') content_list=soup.select('.chapter_content > p') for cont in content_list: cont_str=cont.string f.write(cont_str) f.close() print("爬取完成!!")
