python 用 panda 实现列联表(交叉表)实例详解
交叉表(cross-tabulation,简称crosstab)是⼀种⽤于计算分组频率的特殊透视表。
语法详解:
pd.crosstab(index, # 分组依据
columns, # 列
values=None, # 聚合计算的值
rownames=None, # 列名称
colnames=None, # 行名称
aggfunc=None, # 聚合函数
margins=False, # 总计行/列
dropna=True, # 是否删除缺失值
normalize=False #
)
1 crosstab() 实例1
1.1 读取数据
import os
import numpy as np
import pandas as pd
file_name = os.path.join(path, 'Excel_test.xls')
df = pd.read_excel(io=file_name, # 工作簿路径
sheetname='透视表', # 工作表名称
skiprows=1, # 要忽略的行数
parse_cols='A:D' # 读入的列
)
df
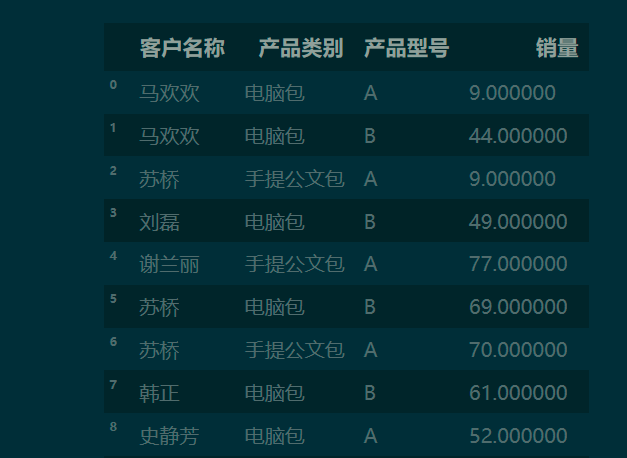
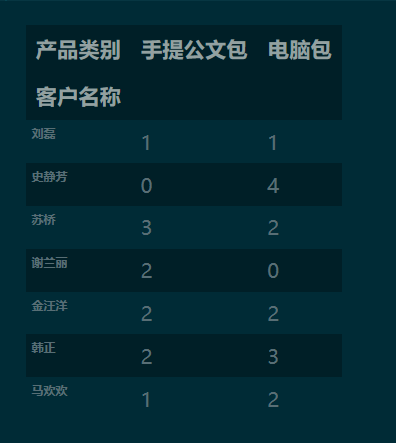
1.2 pd.crosstab() 默认生成以行和列分类的频数表
pd.crosstab(df['客户名称'], df['产品类别'])
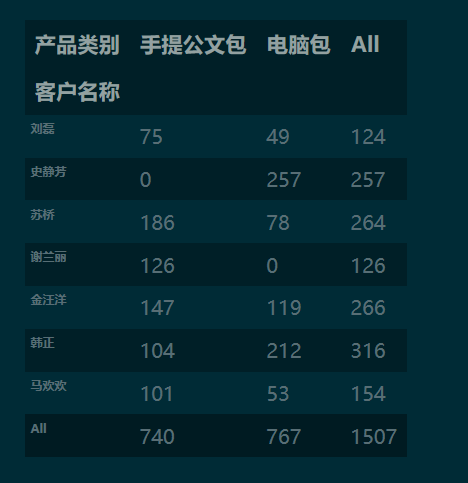
1.3 设置跟多参数实现分类汇总
pd.crosstab(index=df['客户名称'],
columns=df['产品类别'],
values=df['销量'],
aggfunc='sum',
margins=True
).round(0).fillna(0).astype('int')
注:因为交叉表示透视表的特例,所以交叉表可以用透视表的函数实现。又因为透视表可以用更 python 的方式 groupby-apply 实现,所以,交叉表完全可以用 groupby-apply 的方式实现。
2 用分类汇总的方法实现 交叉表
df.groupby(['客户名称', '产品类别']).apply(sum)

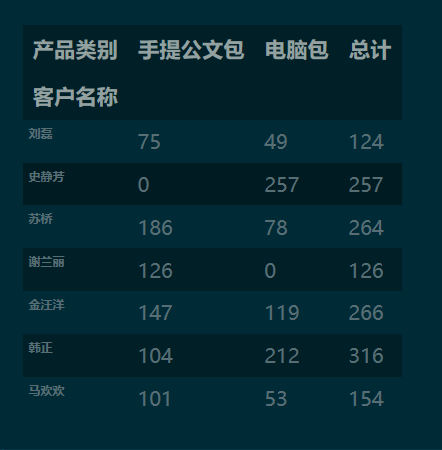
2.1 分类汇总、重新索引、设置数值格式综合应用
c_tbl = df.groupby(['客户名称', '产品类别']).apply(sum)['销量'].unstack()
c_tbl['总计'] = c_tbl.sum(axis=1) # 添加总计列
c_tbl.fillna(0).round(0).astype('int')
软件信息:

非学无以广才,非志无以成学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号