python 执行 正则表达式中的分组
示例 1
import re
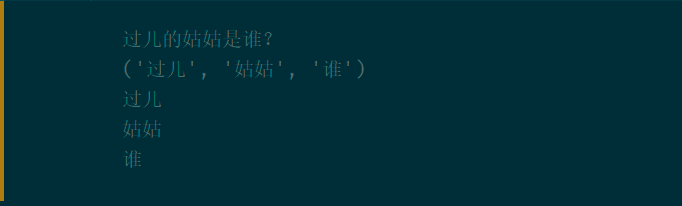
s = "过儿的姑姑是谁?"
regex = re.compile(r'''
(\S[^的]*)的 # 任意(包含 0)个不包含 ‘的’ 字的非空白字符,group1 + ‘的’。
(\S[^是]*)是 # 任意(包含 0)个不包含 ‘是’ 字的非空白字符,group2 + ‘是’
(\S[^?]*)? # 任意(包含 0)个不包含 ‘?’ 字的非空白字符,group3 + ‘?’
''', flags=re.X) # re.X 等效于 re.VERBOSE, 允许正则表达式中编写注释
matches = re.search(regex, s)
if matches:
print(matches.group(0)) # full match
print(matches.groups()) # all groups of regex
print(matches.group(1)) # match group1
print(matches.group(2)) # match group2
print(matches.group(3)) # match group3
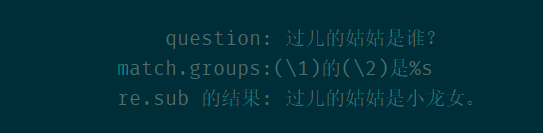
answer = '小龙女'
re.sub(regex, r'\1的\2是%s' %(answer), question)

解释:
示例 2
dstr = '2018-06-07' # data string
re.sub('(\d{4})-(\d{2})-(\d{2})', r'\2-\3-\1', dstr )
# 匹配模式中可写为“组1-组2-组3”, 其中,组1 包含 4 位数字,组2 和组3 各包含 2 位数字。sub() 指定组的顺序。

等效代码为:
re.sub('(\d{4})-(\d{2})-(\d{2})', r'\g<2>-\g<3>-\g<1>', dstr)
非学无以广才,非志无以成学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号