Python 实现基于信息熵的 ID3 算法决策树模型
版本说明
Python version: 3.6.6 |Anaconda, Inc.| (default, Jun 28 2018, 11:21:07) [MSC v.1900 32 bit (Intel)] NumPy version:1.17.4 pandas version:0.25.3 scikit-learn version:0.19.0 graphviz version:0.13.2 scipy version:1.3.3 matplotlib version:3.1.2 IPython version:7.10.1
1、读取数据
datafile = r"...\sales_data.xls" data = pd.read_excel(datafile, header=0, index_col=0) data.head(10)
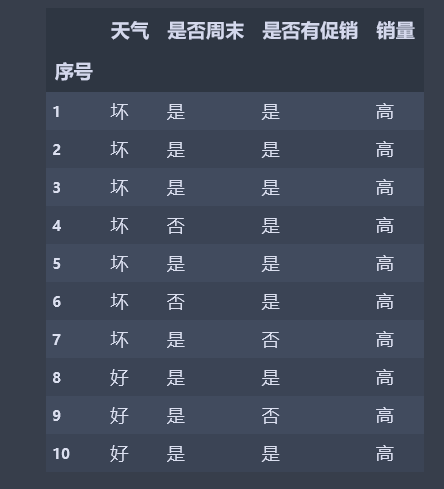
2、对特征值进行数字编码,提取特征值和类标号
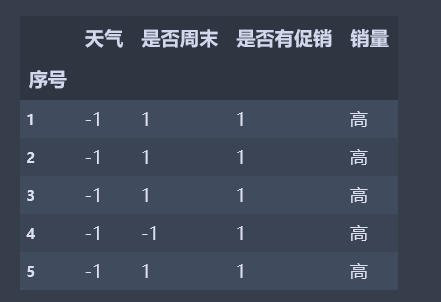
dt = data.copy() dt[(dt == '好') | (dt == '是')] = 1 dt[(dt == '坏') | (dt == '否')] = -1 X = dt.iloc[:, :-1].values.astype(int) y = dt.iloc[:, -1].values
dt.heaad() # 查看编码效果
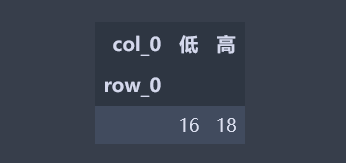
pd.crosstab('', y) # 查看类比统计
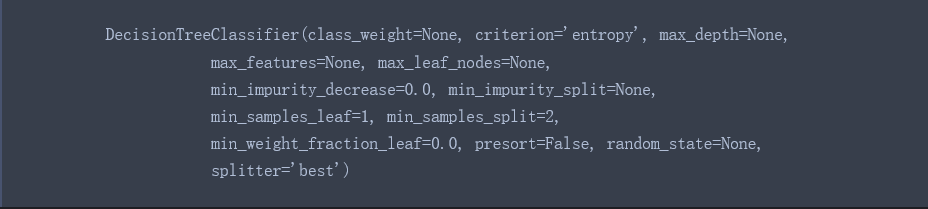
3、训练模型
from sklearn.tree import DecisionTreeClassifier as DTC dtc = DTC(criterion='entropy') # 基于信息熵,建立决策树模型 dtc.fit(X, y)
4、输出决策树图
from sklearn.tree import export_graphviz import graphviz
dot_data = export_graphviz(dtc, feature_names=dt.columns[:-1], class_names=['低','高'],
filled=True, rounded=True, out_file=f)
graph = graphviz.Source(dot_data)
graph
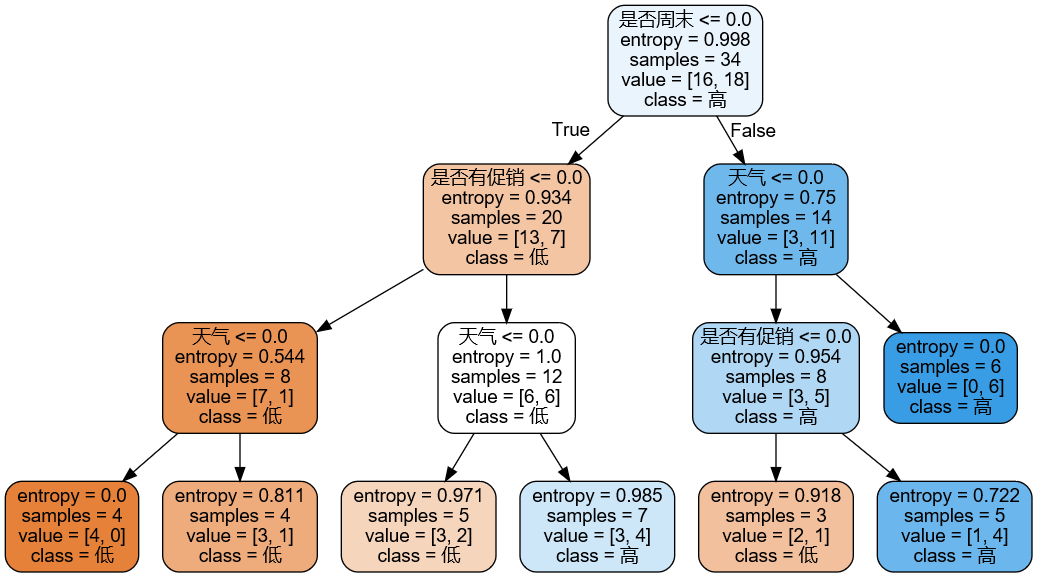
。。。
非学无以广才,非志无以成学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号