
Python 实现感知机算法,用 iriis 数据子集训练一个感知器模型
感知机算法,代码如下:


import numpy as np class Perceptron(): """感知机分类器 参数 ========== eta: 学习速率,区间 [0.0, 1.0] 上的浮点数 n_iter: 迭代次数 属性 ========== w_: 权重,1维数组 errors_: 以列表形式存储每一次迭代过程中分类错误的样本数 """ def __init__(self, eta=0.01, n_iter=10): # 设置默认参数 self.eta= eta self.n_iter = n_iter def fit(self, X, y): """学习训练数据 参数 ========== X:训练集的特征数据 y: 训练集的类标号数据 """ self.w_ = np.zeros(1 + X.shape[1]) # 初始化权重 self.errors_ = [] for _ in range(self.n_iter): errors = 0 for xi, yi in zip(X, y): delta = self.eta * (yi - self.predict(xi)) self.w_[0] += delta self.w_[1:] += delta * xi errors += int(delta != 0.0) self.errors_.append(errors) return self def net_input(self, X): """计算净输入""" z = np.dot(X, self.w_[1:]) + self.w_[0] return z def predict(self, X): """用 sign 函数预测类标号""" yHat = np.where(self.net_input(X) > 0.0, 1, -1) return yHat
利用 iries 的前 100 个样本的的 第 2 特征,第4 特征和类标号, 训练一个感知机分类器:
1、数据准备与可视化,代码如下:
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline plt.rcParams['font.sans-serif'] = 'SimHei' plt.rcParams['axes.unicode_minus'] = False df = pd.read_csv('D:\\pySpace\\iris.data', header=None) y = df.iloc[:100, 4].values y = np.where( y == 'Iris-setosa', -1, 1) # 用 if(con, T_v, F_v)的思想编码 X = df.iloc[:100, [1, 3]].values plt.figure(figsize=(9,7)) # 调整图片大小 plt.scatter(X[:50, 0], X[:50, 1], c='r', marker='o', label='山鸢尾') plt.scatter(X[50:, 0], X[50:, 1], c='b', marker='x', label='变色鸢尾') plt.xlabel('花瓣长度(cm)', fontsize=17) plt.ylabel('萼片长度(cm)', fontsize=17) plt.yticks(fontproperties='Times New Roman', size=13, alpha=0.6) plt.xticks(fontproperties='Times New Roman', size=13, alpha=0.6) plt.legend(loc=1)
图形如下:
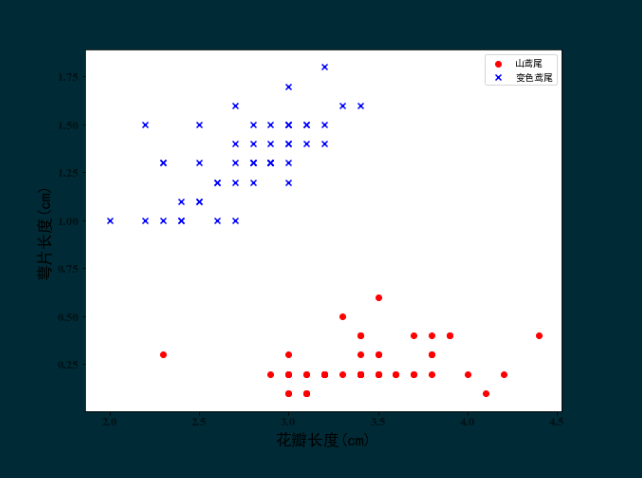
2、训练模型,绘制每次迭代的错误分类数量的折线图,代码如下:
ppn = Perceptron(eta=0.1, n_iter=10) ppn.fit(X, y) # 训练模型 plt.figure(figsize=(8, 6)) plt.plot(range(1, len(ppn.errors_) +1), ppn.errors_, marker='o') plt.xlabel('迭代次数', fontsize=17) plt.ylabel('错误分类的样本数量', fontsize=17) plt.yticks(fontproperties='Times New Roman', size=13, alpha=0.6) plt.xticks(fontproperties='Times New Roman', size=13, alpha=0.6)
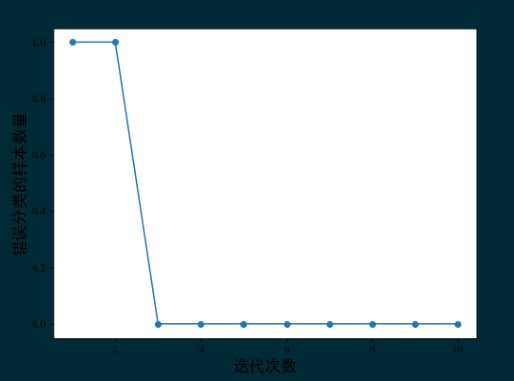
由图可知,分类器在在第3次迭代后就已经收敛,而且具备对训练样本正确分类的能力。
非学无以广才,非志无以成学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号