Hadoop安装最后一步~Hadoop伪分布式配置
Hadoop安装最后一步~Hadoop伪分布式配置
□ Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时读取的是 HDFS 中的文件。 □ Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。
一、Hadoop伪分布式配置
1,通过gedit 编译器修改配置文件 core-site.xml 和 hdfs-site.xml(选择gedit 编译器是因为操作更加方便)
gedit 编译器修改配置文件后,点击菜单栏的保存,退出请按ctr+q
① 修改 core-site.xml命令:
gedit ./etc/hadoop/core-site.xml
■ 修改为下面配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
② 修改 hdfs-site.xml命令:
gedit ./etc/hadoop/hdfs-site.xml
■ 修改为下面配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
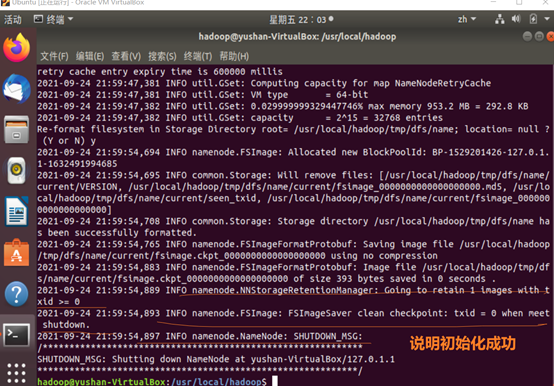
2, 配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop ./bin/hdfs namenode -format
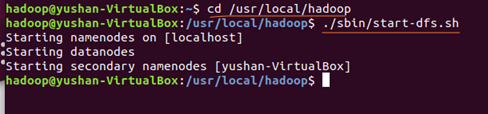
3,开启 NameNode 和 DataNode 守护进程:
cd /usr/local/hadoop ./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
成功启动后,可以访问 Web 界面: (注意是在Ubuntu的浏览器进行输入地址哈,不是主机)
http://localhost:9870 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
bug:namenode启动成功,但是不能通过web访问? 在启动服务之前需要查看防火墙的状态(以下的命令是ubuntu的)
systemctl status firewalld.service #~ 提示:Unit firewalld.service could not be found?------说明应该不是防火墙拦截吧~ systemctl stop firewalld.service # 关闭防火墙 systemctl disable firewalld.service # 禁止firewall开机启动
二、运行Hadoop伪分布式实例:
单机模式,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录:
① 在 HDFS 中创建用户目录:
./bin/hdfs dfs -mkdir -p /user/hadoop
② 接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,
即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input中:
./bin/hdfs dfs -mkdir input ./bin/hdfs dfs -put ./etc/hadoop/*.xml input
③ 复制完成后,可以通过如下命令查看文件列表:
./bin/hdfs dfs -ls input
④ 伪分布式运行 MapReduce(方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件):
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
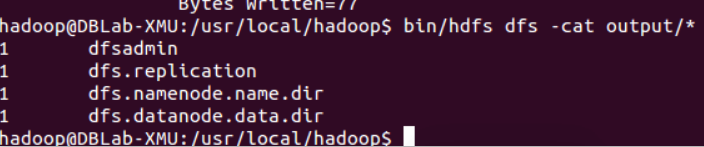
⑤ 查看运行结果的命令(查看的是位于 HDFS 中的输出结果):
./bin/hdfs dfs -cat output/*
结果如下:
⑥ 我们也可以将运行结果取回到本地:
rm -r ./output # 先删除本地的 output 文件夹(如果存在) ./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机 cat ./output/*
⑦ 删除 output 文件夹(若要再次执行Hadoop伪分布式的例子,输出目录不能存在,否则会提示错误):
./bin/hdfs dfs -rm -r output # 删除 output 文件夹
⑧ 关闭 Hadoop:
./sbin/stop-dfs.sh
参考文章:《Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0(2.7.1)/Ubuntu14.04(16.04)》http://dblab.xmu.edu.cn/blog/install-hadoop/
作者:给力星
大佬的文章还有其他bug的解决或者其他细节,有遇到问题的小伙伴,可以翻一翻
本文来自博客园,作者:一乐乐,转载请注明原文链接:https://www.cnblogs.com/shan333/p/15333455.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号