

ClickHouse深度解析 一般有用 看1 速
一、什么是ClickHouse?
ClickHouse由俄罗斯第一大搜索引擎Yandex于2016年6月发布, 开发语言为C++,ClickHouse是一个面向联机分析处理(OLAP)的开源的面向列式存储的DBMS,简称CK, 与Hadoop、Spark这些巨无霸组件相比,ClickHouse很轻量级,查询性能非常好,使用之后会被它的性能折服,非常值得安利。
二、适用场景
-
志数据行为分析
-
标签画像的分析
-
数据集市分层
-
广告系统和实时竞价广告
-
电商和金融行业
-
实时监控和遥感测量
-
商业智能
-
在线游戏
-
信息安全
-
所有的互联网场景
三、特性
真正的面向列的DBMS(ClickHouse是一个DBMS,而不是一个单一的数据库。它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置和重新启动服务器)
数据压缩(一些面向列的DBMS(INFINIDB CE 和 MonetDB)不使用数据压缩。但是,数据压缩确实是提高了性能)
磁盘存储的数据(许多面向列的DBMS(SPA HANA和GooglePowerDrill))只能在内存中工作。但即使在数千台服务器上,内存也太小了。)
多核并行处理(多核多节点并行化大型查询)
在多个服务器上分布式处理(在clickhouse中,数据可以驻留在不同的分片上。每个分片都可以用于容错的一组副本,查询会在所有分片上并行处理)
SQL支持(ClickHouse sql 跟真正的sql有不一样的函数名称。不过语法基本跟SQL语法兼容,支持JOIN/FROM/IN 和JOIN子句及标量子查询支持子查询)
-
真正的列式数据库
-
数据压缩
-
数据的磁盘存储
-
多核并行处理
-
多服务器分布式处理(数据保存在不同的shard上,每一个shard都由一组用于容错的副本组成,可并行查询所有shard)
-
向量引擎(按列的一部分进行处理,高效实用CPU)
-
实时的数据更新(支持在表中定义主键,数据增量有序存储在mergeTree中)
-
索引(按照主键对数据进行排序,毫秒内完成对数据的查找)
-
适合在线查询
-
支持近似计算(允许牺牲精度的情况下低延迟查询)
-
支持数据复制和数据完整性(异步多主复制技术)
四、 缺陷
-
没有完整的事务支持
-
缺少高频率低延迟的修改或删除数据的能力
-
不适合通过其检索单行的点查询
-
联机事物处理
-
二进制数据或文件存储
-
键值对数据高效率访问请求
五、核心概念
5.1.表引擎(Engine)
表引擎决定了数据在文件系统中的存储方式,常用的也是官方推荐的存储引擎是MergeTree系列,如果需要数据副本的话可以使用ReplicatedMergeTree系列,相当于MergeTree的副本版本。读取集群数据需要使用分布式表引擎Distribute。
5.2.表分区(Partition)
表中的数据可以按照指定的字段分区存储,每个分区在文件系统中都是都以目录的形式存在。常用时间字段作为分区字段,数据量大的表可以按照小时分区,数据量小的表可以在按照天分区或者月分区,查询时,使用分区字段作为Where条件,可以有效的过滤掉大量非结果集数据。
5.3.分片(Shard)
一个分片本身就是ClickHouse一个实例节点,分片的本质就是为了提高查询效率,将一份全量的数据分成多份(片),从而降低单节点的数据扫描数量,提高查询性能。
5.4. 复制集(Replication)
简单理解就是相同的数据备份,在CK中通过复制集,我们实现保障了数据可靠性外,也通过多副本的方式,增加了CK查询的并发能力。这里一般有2种方式: (1)基于ZooKeeper的表复制方式; (2)基于Cluster的复制方式。由于我们推荐的数据写入方式本地表写入,禁止分布式表写入,所以我们的复制表只考虑ZooKeeper的表复制方案。
5.5.集群(Cluster)
可以使用多个ClickHouse实例组成一个集群,并统一对外提供服务。
六、主要表引擎深入解析
6.1.TinyLog
最简单的表引擎,用于将数据存储在磁盘上,每列都存储在单独的压缩文件中,写入时,数据附加到文件末尾. 缺点:(1)没有并发控制(没有做优化,同时写会数据会损坏,报错) (2)不支持索引 (3)数据存储在磁盘上 优点:(1)小表节省空间 (2)数据写入,只查询,不做增删改操作 创建表:
create table stu1(id Int8, name String)ENGINE=TinyLog
6.2. Memory
内存引擎,数据以未压缩的原始形式直接保存在内存中,服务器重启,数据会消失,读写操作不会相互阻塞,不支持索引。 建议上限1亿行的场景。 优点:简单查询下有非常高的性能表现(超过10G/s) 创建表:
create table stu1(id Int8, name String)ENGINE=Merge(db_name, 'regex_tablename')
6.3.Merge
本身不存储数据,但可用于同时从任意多个其他的表中读取数据,读是自动并行的,不支持写入,读取时,那些真正被读取到数据的表的索引(如果有的话)会被占用,默认是本地表,不能跨机器。 参数:一个数据库名和一个用于匹配表名的正则表达式 创建表:
create table t1(id Int8, name String)ENGINE=TinyLog
create table t2(id Int8, name String)ENGINE=TinyLog
create table t3(id Int8, name String)ENGINE=TinyLog
create table t (id UInt16, name String)ENGINE=Merge(currentDatabase(), ‘^t’)
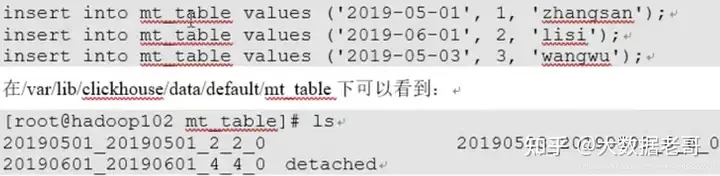
6.4.MergeTree
ck中最强大的表引擎MergeTree(合并树)和该系列(*MergeTree)中的其他引擎。 使用场景:有巨量数据要插入到表中,高效一批批写入数据片段,并希望这些数据片段在后台按照一定规则合并。相比在插入时不断修改(重写)数据进行存储,会高效很多。 优点:(1)数据按主键排序 (2)可以使用分区(如果指定了主键)(3)支持数据副本 (4)支持数据采样 创建表:
ENGINE MergeTree() PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate, intHash32(UserID)) SAMPLE BY intHash32(UserID) SETTINGS index_granularity=8192

插入数据:
6.5.ReplacingMergeTree
在MergeTree的基础上,增加了“处理重复数据”的功能,和MergeTree的不同之处在于他会删除具有相同主键的重复项,数据的去重只会在合并的过程中出现,合并会在未知的时间在后台进行,所以你无法预先做出计划,有一些数据可能仍未被处理,适用于在后台清除重复的数据以节省空间,但是不保证没有重复的数据出现。 创建表:

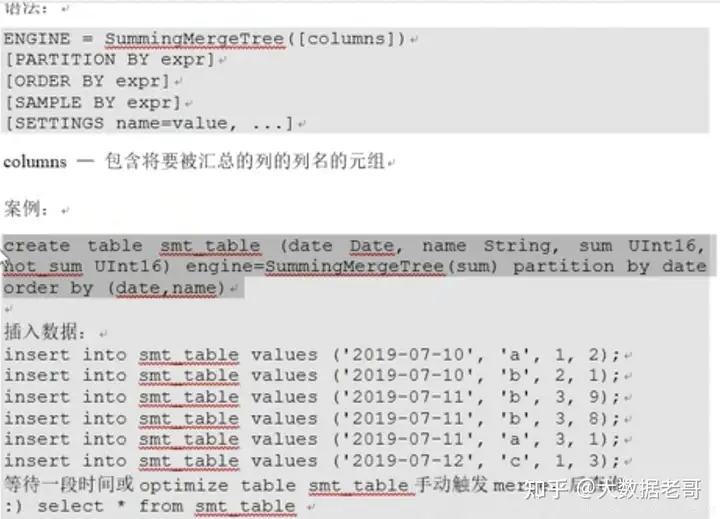
6.6.SummingMergeTree
继承自MergeTree,区别在于,当合并SummingMergeTree表的数据片段时,ck会把具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值,如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度,对于不可加的列,会取一个最先出现的值。
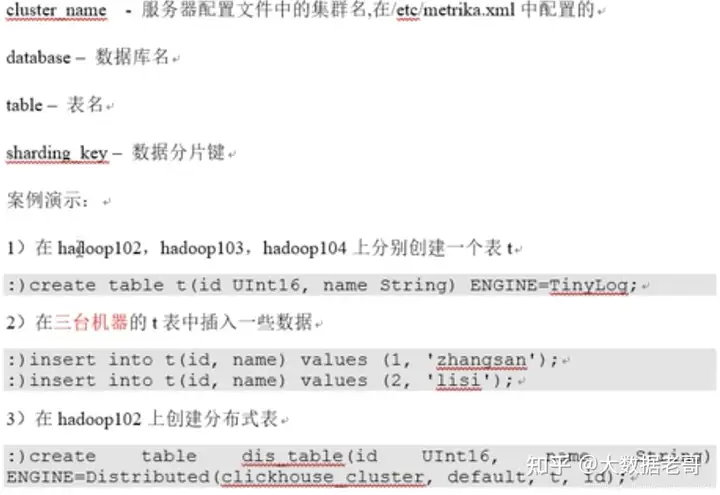
6.7.Distributed(重点)
分布式引擎,本身不存储数据,但可以在多个服务器上进行分布式查询,读是自动并行的,读取时,远程服务器的索引(如果有的话)会被使用。
七、最佳实践
7.1.HDFS数据导入Clickhouse
创建hdfs_engine
CREATE TABLE hdfs_engine_table (name String, value UInt32) ENGINE=HDFS('hdfs://hdfs1:9000/other_storage', 'TSV')
File file
INSERT INTO hdfs_engine_table VALUES ('one', 1), ('two', 2), ('three', 3)
数据查询
SELECT * FROM hdfs_engine_table LIMIT 2
┌─name─┬─value─┐
│ one │ 1 │
│ two │ 2 │
└──────┴───────┘
7.2.每分钟亿级别海量用户行为日志实时自助查询
数据链路
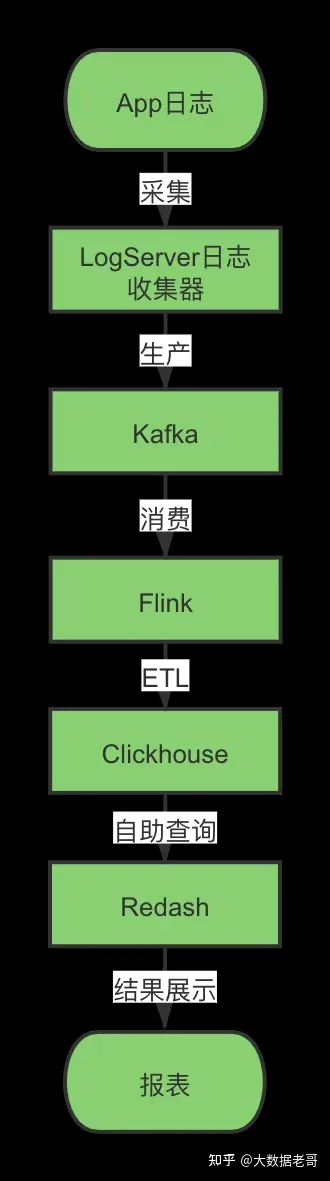
系统实现 在flink端动态设置schema信息,ETL处理数据,动态生成宽表,数据存入Clickhouse,按天分区,Clickhouse使用Distributed表引擎,数据保留7天,避免数据过度膨胀,导致查询性能降低,使用Redash报表工具,分析人员可以写SQL自助查询,结果自定义图表展示。
系统成果 每分钟乙级的数据量,整个数据链路数据延迟在毫秒,数据查询响应在秒级别,动态设置schema生成宽表,做到整个系统的复用性,避免重复开发,查询性能比Hive快几百倍,满足了实时性的要求。
八、大厂使用场景
1. 头条:用户行为分析系统,上报日志 大宽表,减少join,增加map数据类型,展平模型,支持动态scheam
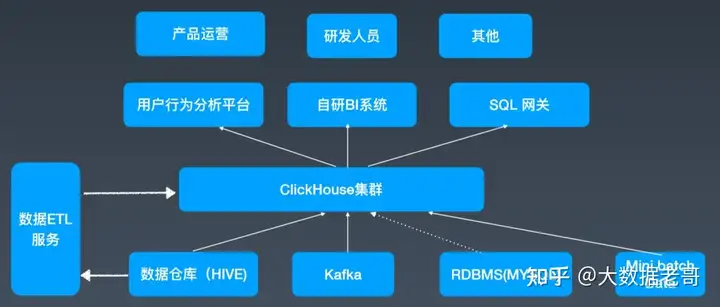
2. 腾讯:游戏数据分析
3. 携程:内部从18年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求 4.快手:内部也在使用ClickHouse,存储总量大约10PB, 每天新增200TB, 90%查询小于3S 5.国外:Yandex内部有数百节点用于做用户点击行为分析,CloudFlare、Spotify等头部公司也在使用
