
客快物流大数据项目(八十二):Kudu的读写原理 一般有用 看1
Kudu的读写原理
一、工作模式
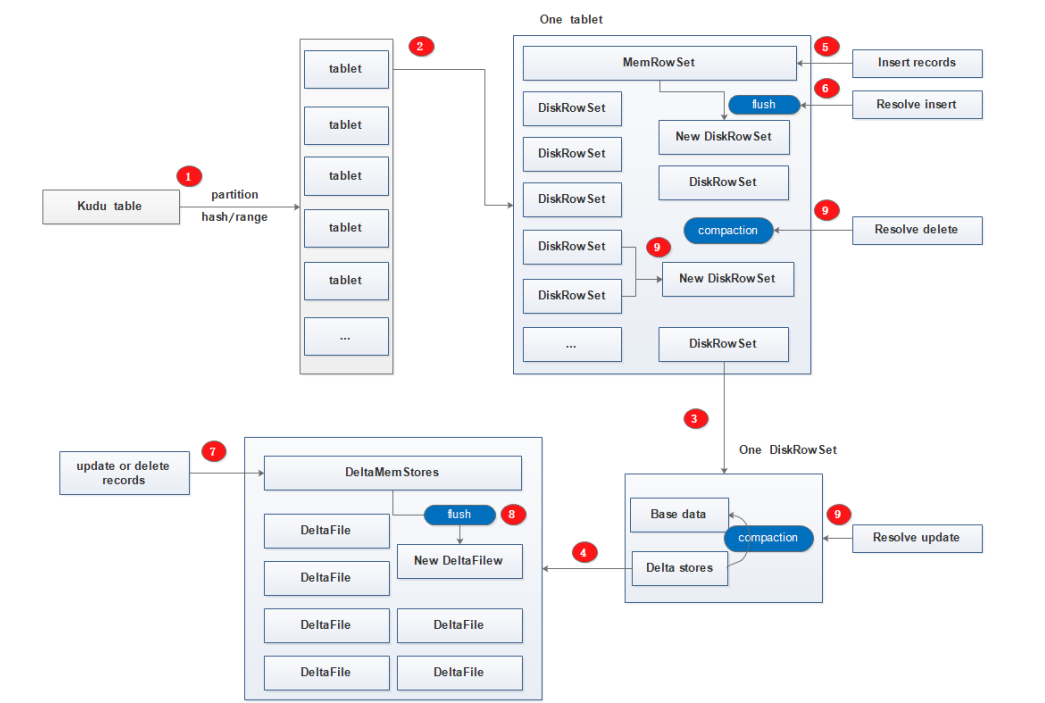
Kudu的工作模式如下图,有些在上面的内容中已经介绍了,这里简单标注一下:
-
每个kudu table按照hash或range分区为多个tablet;
-
每个tablet中包含一个MemRowSet以及多个DiskRowSet;
-
每个DiskRowSet包含BaseData以及DeltaStores;
-
DeltaStores由多个DeltaFile和一个DeltaMemStore组成;
-
insert请求的新增数据以及对MemRowSet中数据的update操作(新增的数据还没有来得及触发compaction操作再次进行更新操作的新数据) 会先进入到MemRowSet;
-
当触发flush条件时将新增数据真正的持久化到磁盘的DiskRowSet内;
-
对老数据的update和delete操作是提交到内存中的DeltaMemStore;
-
当触发flush条件时会将更新和删除操作持久化到磁盘DIskRowSet中的DeltaFile内,此时老数据还在BaseData内(逻辑删除),新数据已在DeltaFile内;
-
当触发compaction条件时,将DeltaFile和BaseData进行合并,DiskRowSet进行合并,此时老数据才真正的从磁盘内消失掉(物理删除),只留下更新后的数据记录;
二、kudu的读流程
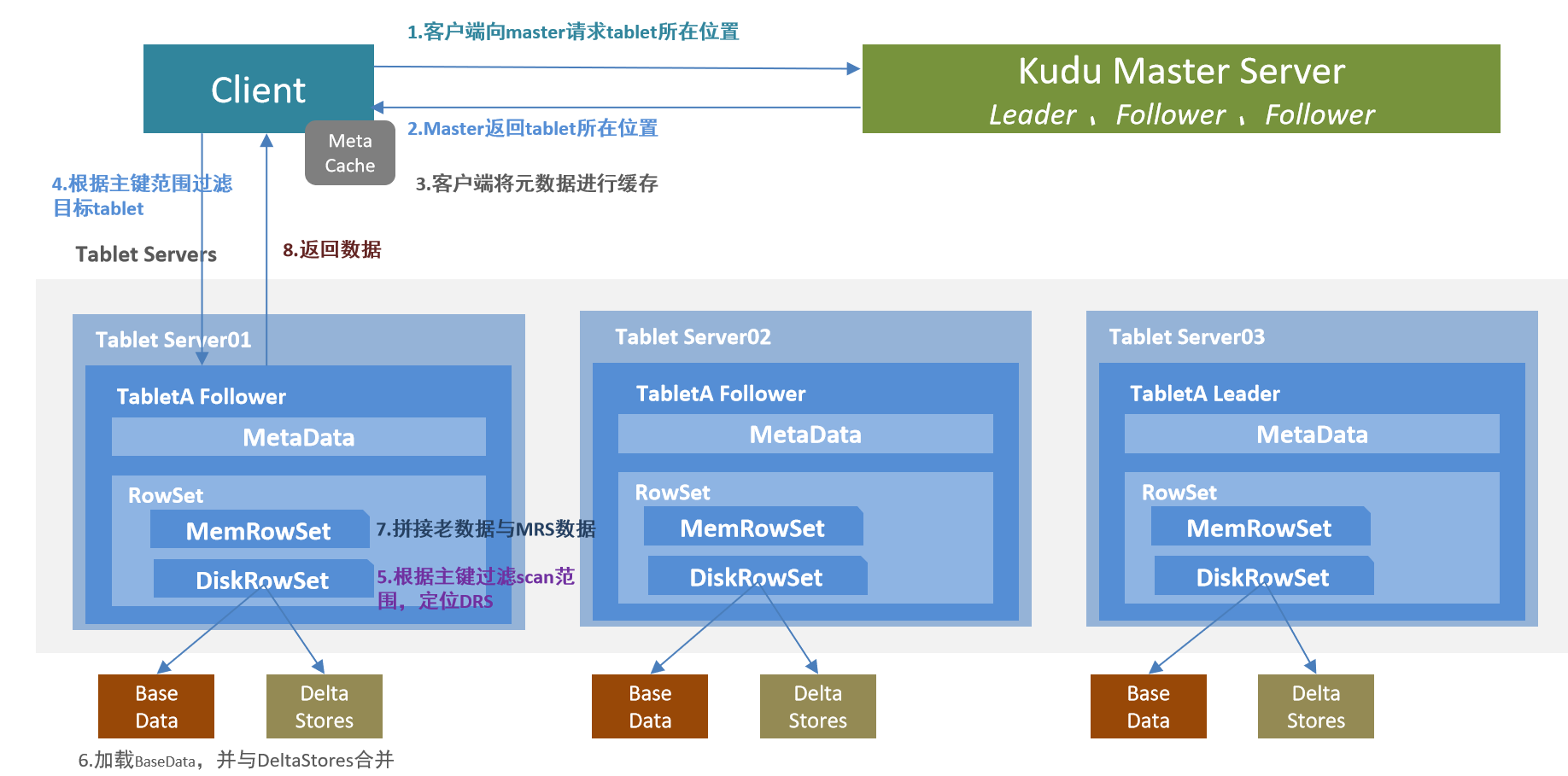
-
客户端向Kudu Master请求tablet所在位置
-
Kudu Master返回tablet所在位置
-
为了优化读取和写入,客户端将元数据进行缓存
-
根据主键范围过滤目标tablet,请求Tablet Follower
-
根据主键过滤scan范围,定位DataRowSets
-
加载BaseData,并与DeltaStores合并,得到老数据的最新结果
-
拼接第6步骤得到的老数据与MemRowSet数据 得到所需数据
-
将数据返回给客户端
三、kudu的写流程
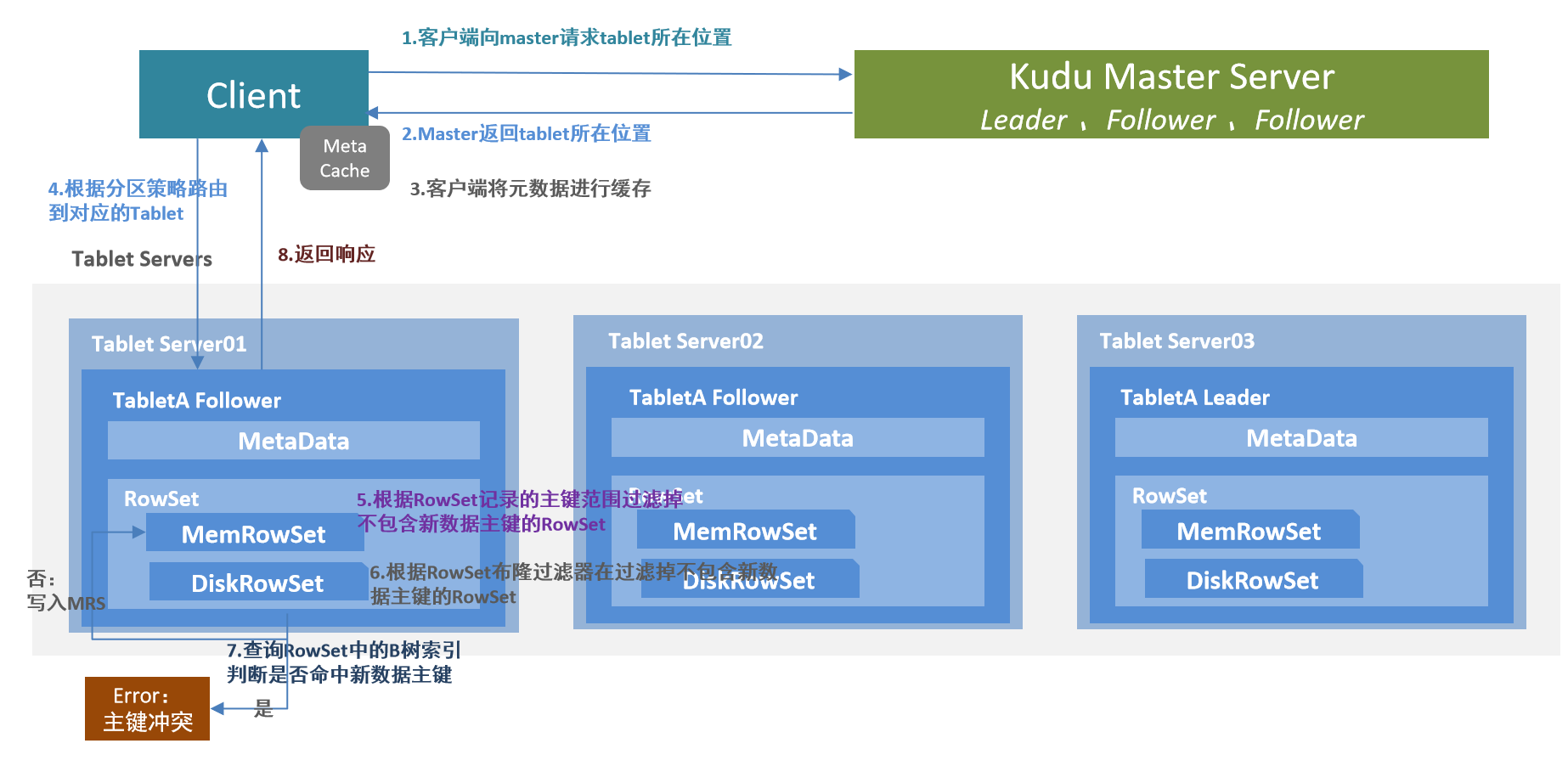
-
客户端向Kudu Master请求tablet所在位置;
-
Kudu Master返回tablet所在位置;
-
为了优化读取和写入,客户端将元数据进行缓存;
-
根据分区策略,路由到对应Tablet,请求Tablet Leader;
-
根据RowSet记录的主键范围过滤掉不包含新增数据主键的RowSet;
-
根据RowSet 布隆过滤器再进行一次过滤,过滤掉不包含新数据主键的RowSet;
-
查询RowSet中的B树索引判断是否命中新数据主键,若命中则报错主键冲突,否则新数据写入MemRowSet;
-
返回响应给客户端;
四、kudu的更新流程
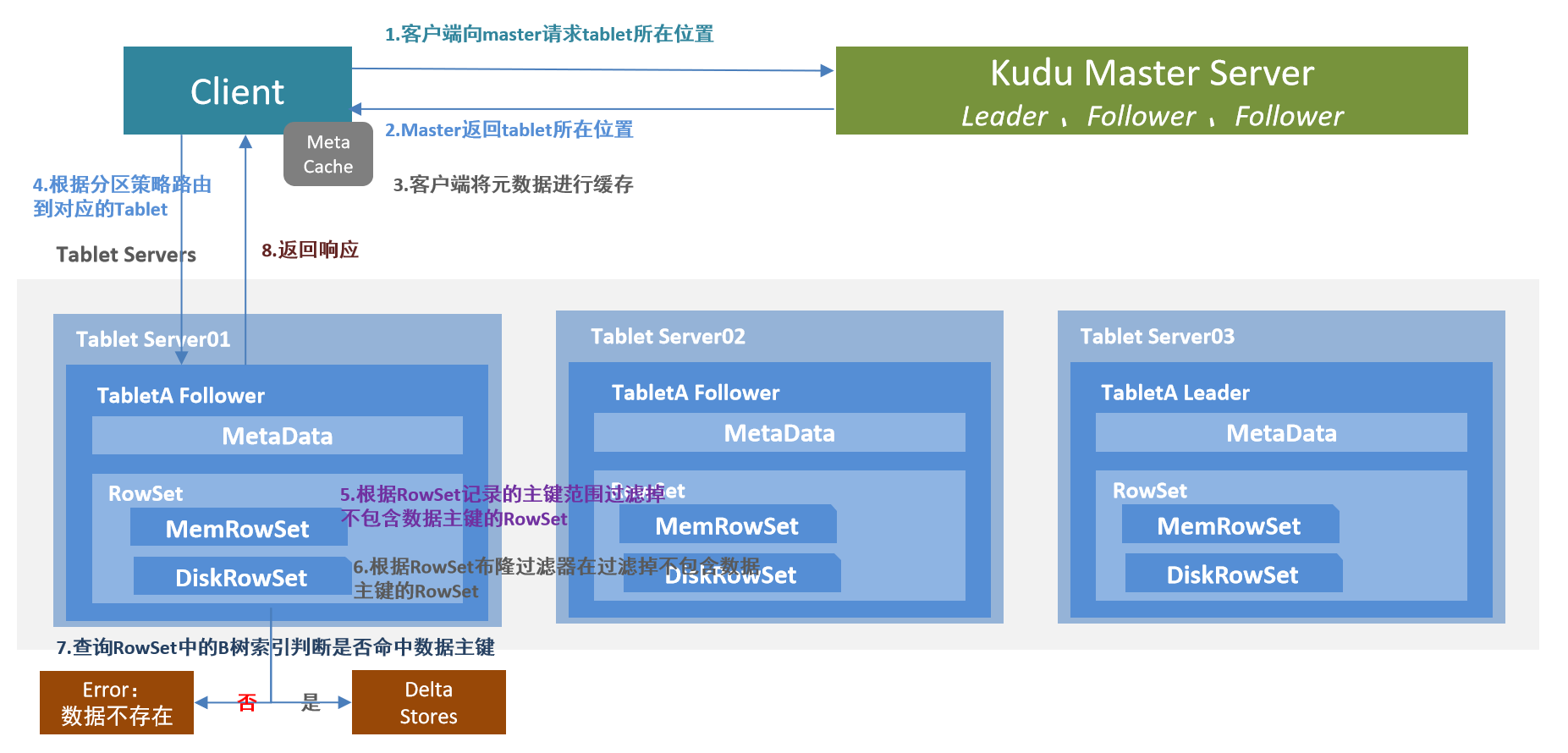
更新删除流程与写入流程类似,区别就是最后判断是否存在主键时候的操作,若存在才能更新,不存在才能插入新数据。
-
客户端向Kudu Master请求tablet所在位置
-
Kudu Master返回tablet所在位置
-
为了优化读取和写入,客户端将元数据进行缓存
-
根据分区策略,路由到对应Tablet,请求Tablet Leader
-
根据RowSet记录的主键范围过滤掉不包含修改的数据主键的RowSet
-
根据RowSet 布隆过滤器再进行一次过滤,过滤掉不包含修改的数据主键的RowSet
-
查询RowSet中的B树索引判断是否命中修改的数据主键,若命中则修改至DeltaStores,否则报错数据不存在
-
返回响应给客户端
