
WM_技术中台下终搜的技术解决方案-stage1 mysql->logstash->es 数据采集并处理 暂时没用
1 技术中台与终搜介绍
1.1 技术中台与终搜介绍
中台产生的背景
中台(技术、
业务、数据)最早是阿里巴巴提出来的。
2015年阿里
进行过一次架构调整,将搜索事业部、共享业务平台、数据技术及产品部组成了中台事业
群。
并喊出“小前台,大中台”的管理模式。
什么是中台
中台是介于前台和后台中间的平台(基础中间件),有点像编程时的适配层,起到承上启下的作用。当组
织架构太深了,前台后台隔得太远,沟通成本太高时,通过中台可以一定程度上来解决这个问题。
为什么使用中台
中台强调资源整合、能力沉淀,把一些公共、底层的算法和能力抽象出来,形成各种平台,供其他各个前
台进行调用,
什么是终搜
终搜平台是技术中台的一种体现;比如统一OSS,自动化配置、统一监控、统一登录平台、CICD&一站式
终搜平台都是技术中台的实现。
1.2 技术架构介绍
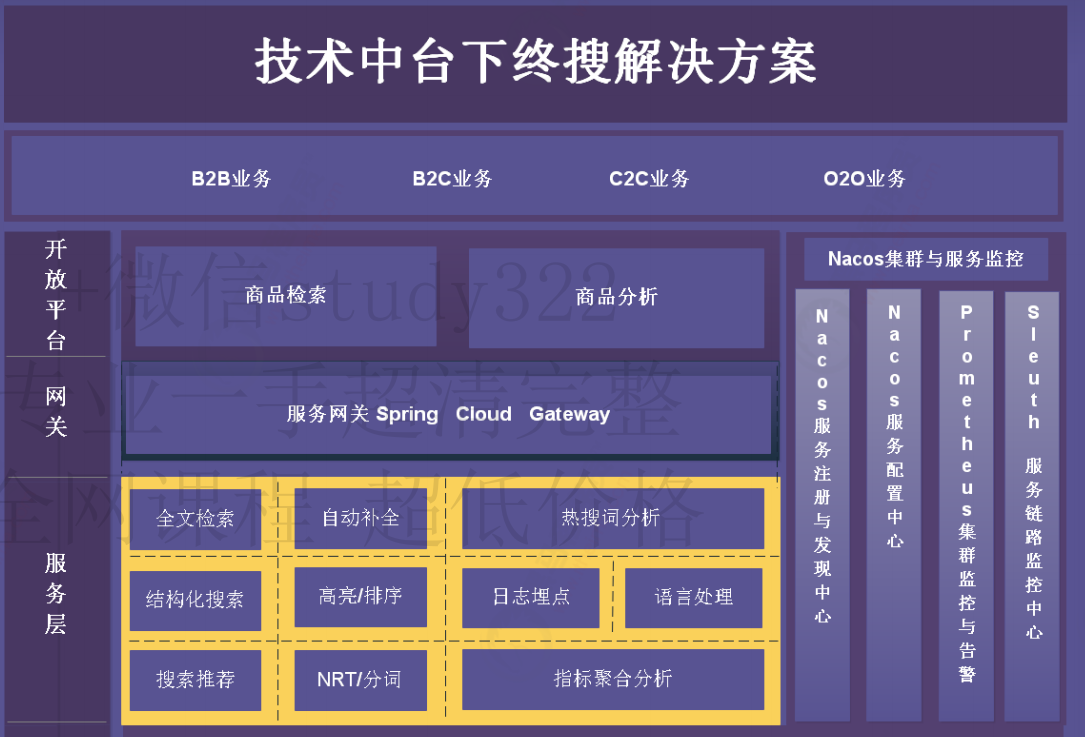
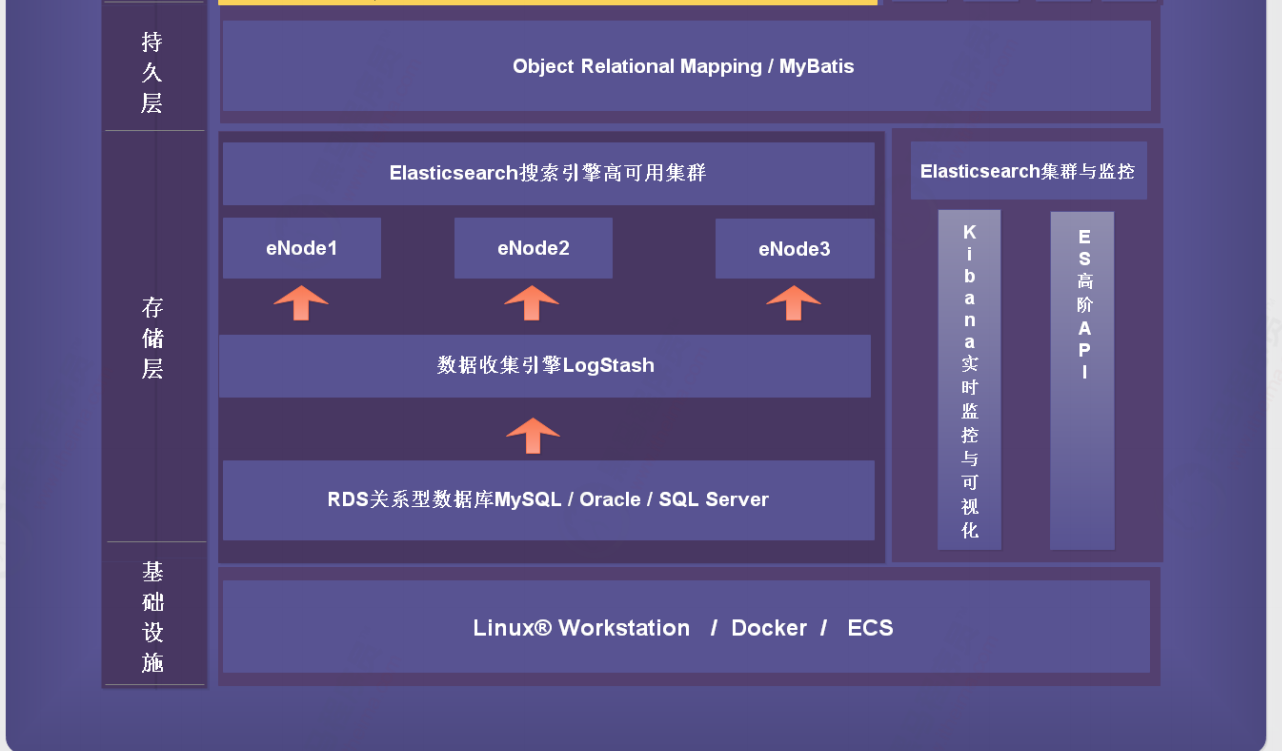
1.3 技术栈介绍
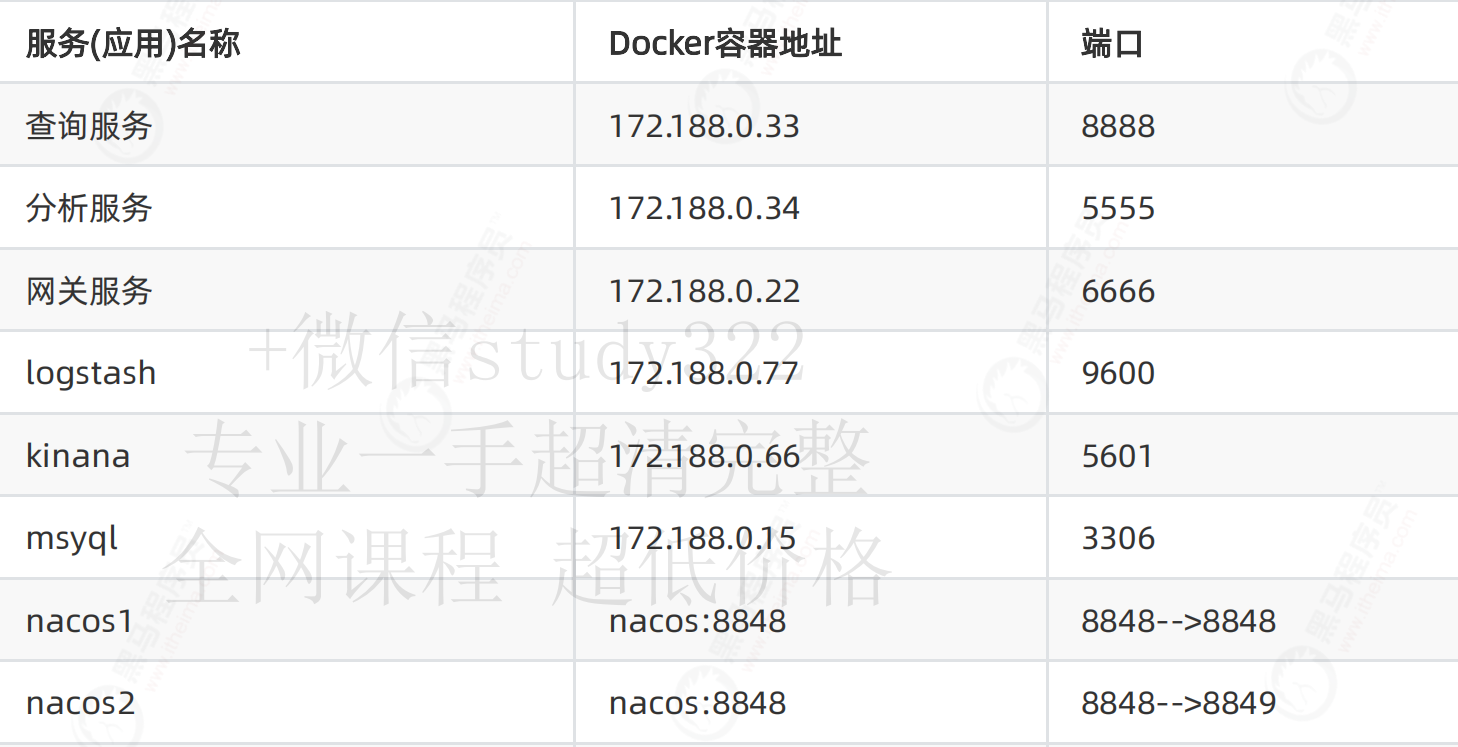
服务(应用)名称
Docker容器地址
端口
查询服务
172.188.0.33
8888
分析服务
172.188.0.34
5555
网关服务
172.188.0.22
6666
logstash
172.188.0.77
9600
kinana
172.188.0.66
5601
msyql
172.188.0.15
3306
nacos1
nacos:8848
8848-->8848
nacos2
nacos:8848
8848-->8849
nacos3
nacos:8848
8848-->8850
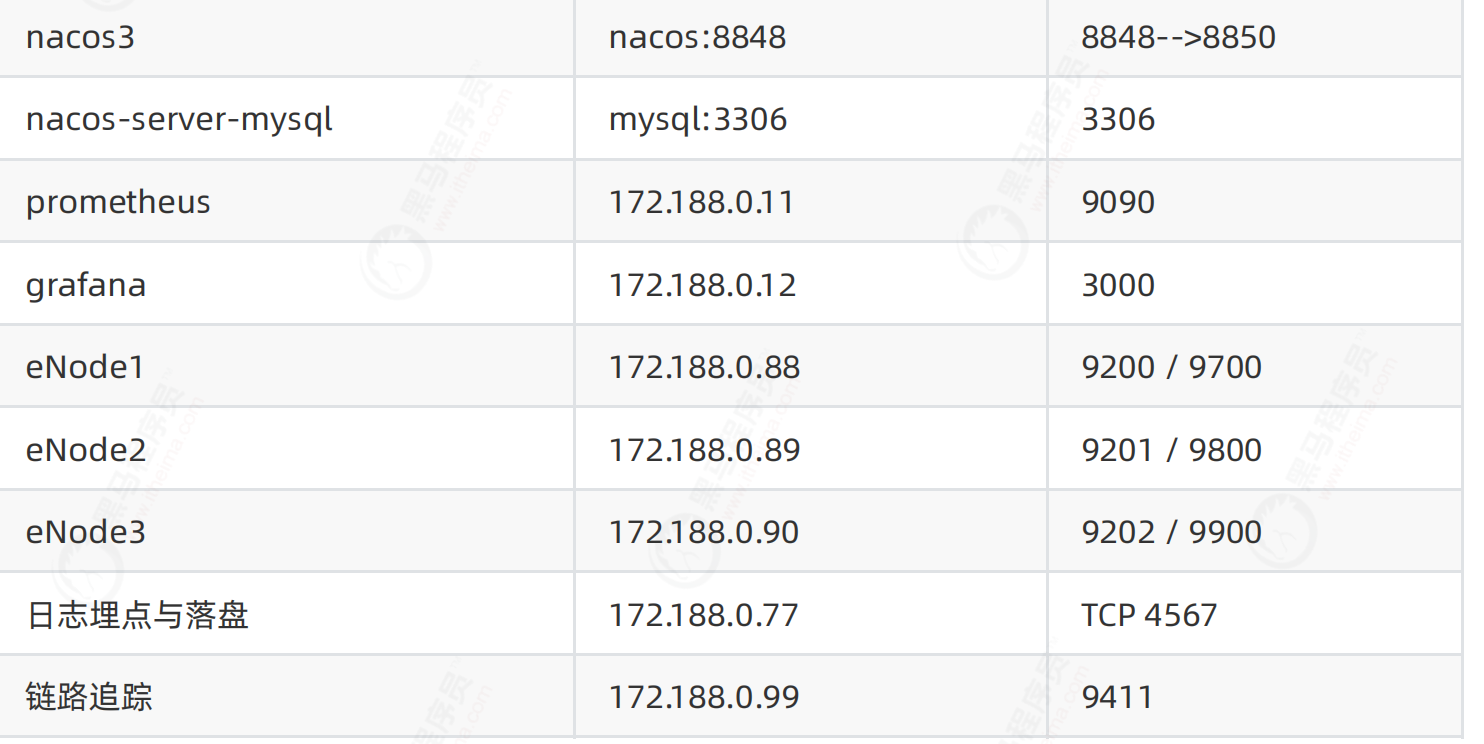
nacos-server-mysql
mysql:3306
3306
prometheus
172.188.0.11
9090
grafana
172.188.0.12
3000
eNode1
172.188.0.88
9200 / 9700
eNode2
172.188.0.89
9201 / 9800
eNode3
172.188.0.90
9202 / 9900
日志埋点与落盘
172.188.0.77
TCP 4567
链路追踪
172.188.0.99
9411
2 数据收集引擎之Logstash数据同步
2.1 数据收集引擎概述
logstash-input-jdbc
logstash官方插件 logstash-input-jdbc集成在logstash(5.X之后)中,通过配置文件实现mysql与
elasticsearch数据同步
能实现mysql数据全量和增量的数据同步,且能实现定时同步.
2.2 Logstash数据同步与转换
2.2.1 全量同步
全量同步是指全部将数据同步到es,通常是刚建立es,第一次同步时使用。
tips
上传mysql-connector-java-5.1.48.jar
1、修改logstash.conf文件
目录切换
stdin从标准输入读取事件。
默认情况下,每一行读取为一个事件
什么是logstash
简单来说logstash就是一个具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输
出端;与此同时这根管道还可以根据自己的需求在inuput --out中间加上滤网,Logstash内置了几十种插
件,可以满足你的各种应用场景。
cd /usr/local/logstash/config/conf.d
input {
stdin {}
#使用jdbc插件
jdbc {
# mysql数据库驱动
#jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql
connector-java-5.1.48.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
# mysql数据库链接,数据库名
jdbc_connection_string => "jdbc:mysql://172.188.0.15:3306/product?
characterEncoding=UTF-8&useSSL=false"
# mysql数据库用户名,密码
jdbc_user => "root"
jdbc_password => "root"
2、/usr/local/logstash/confifig/conf.d/sql目录修改full_jdbc.sql文件
full_jdbc内容如下
3、打开Kibana创建索引和映射
坑
mysql---logstash---es
如果创建的映射是有大写的时候,es会自动转成小写
而且查看映射数据结构的时候会出现两个相同的字段(productname和productName)
# 分页
jdbc_paging_enabled => "true"
# 分页大小
jdbc_page_size => "50000"
# sql语句执行文件,也可直接使用 statement => 'select * from t'
statement_filepath => "/usr/share/logstash/pipeline/sql/full_jdbc.sql"
#statement => " select * from product where id <=100 "
}
}
# 过滤部分(
不是必须项)
filter {
json
{
so
urce => "message"
remove_field => ["message"]
}
}
# 输出部分
output {
elasticsearch {
# elasticsearch索引名
index => "product"
# elasticsearch的ip和端口号
hosts => ["172.188.0.88:9200","172.188.0.89:9201","172.188.0.90:9202"]
# 同步mysql中数据id作为elasticsearch中文档id
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
cd /usr/local/logstash/config/conf.d/sql
vi full_jdbc.sql
SELECT
id,
TRIM( REPLACE ( product_name, ' ', '' ) ) AS productname,
price
FROM product
这样就导致我们自己定义的映射无法使用,而有数据的是es自动生成的那个小写
4、查询索引以及数据
如果对映射没有硬性要求,可以忽略当前步骤,会自动创建索引
上图显示无数据;"value" : 0表示命中0条
5、重启logstash进行全量同步
报错信息
原因为:在启动fifirewalld之后,iptables被激活,
此时没有docker chain,重启docker后被加入到iptable里面
PUT product
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings":
{
"properti
es
": {
"productname": {
"t
ype": "text"
},
"p
rice": {
"type": "double"
}
}
}
}
GET product/_search
docker restart 82b89c39282a
解决方案
查看日志
6、再次查看索引以及数据
Error response from daemon: Cannot restart container 3849f947e115: driver failed
programming external connectivity on endpoint logstash
(60f5d9678218dc8d19bc8858fb1a195f4ebee294cff23d499a28612019a0ff78): (iptables
failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 4567 -j DNAT --
to-destination 172.188.0.77:4567 ! -i br-413b460a0fc8: iptables: No
chain/target/match by that name.
systemctl
restart docker
docker logs -f --tail=200 82b89c39282a
http://172.17.0.225:9200/_cat/count/product?v
7、遇到的问题
查看空间大小
解决方案一:
解决方案二
找cf94b7124ef90b9ea6a2a9c48494bd307661829daa245320a408fc392370fb14-json.log
路径是
/var/lib/docker/containers/cf94b7124ef90b9ea6a2a9c48494bd307661829daa245320a408fc39
2370fb14
es集群数据量增速过快,如果磁盘空间过小;会导致个别es node节点磁盘使用率在%90以上 ,由于ES新节
点的数据目录data存储空间不足,导致从master主节点接收同步数据的时候失败,此时ES集群为了保护数
据,会自动把索引分片index置为只读read-only.
到达85的时候
;就停止导入,不停重试.....
df -h
PUT _settings
{
"index": {
"blocks": {
"read_only_allow_delete": "false"
}
}
}
find / -type f -size +2000M
使用黑洞设置为空
2.2.2 增量同步
增量同步是指将后续的更新、插入记录同步到es。
1、修改增量配置
修改上面的logstash.conf文件
cat /dev/null
>
cf94b7124ef90
b
9
ea6a2a9c48494bd307661829daa245320a408fc392370fb14-json.log
input {
stdin {}
#使用jdbc插件
jdbc {
# mysql数据库驱动
#jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql
connector-java-5.1.48.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
# mysql数据库链接,数据库名
jdbc_connection_string => "jdbc:mysql://172.188.0.15:3306/product?
characterEncoding=UTF-8&useSSL=false"
# mysql数据库用户名,密码
jdbc_user => "root"
jdbc_password => "root"
# 设置监听间隔 各字段含义(分、时、天、月、年),全部为*默认含义为每分钟更新一次
# /2* * * *表示每隔2分钟执行一次,依次类推
schedule => "* * * * *"
# 分页
jdbc_paging_enabled => "true"
# 分页大小
jdbc_page_size => "50000"
# sql语句执行文件,也可直接使用 statement => 'select * from t'
statement_filepath => "/usr/share/logstash/pipeline/sql/increment_jdbc.sql"
#上一个sql_last_value值的存放文件路径, 必须要在文件中指定字段的初始值
#last_run_metadata_path => "./config/station_parameter.txt"
#设置时区,此处更新sql_last_value查询的时区,sql_last_value还是默认UTC
jdbc_default_timezone => "Asia/Shanghai"
#使用其它字段追踪,而不是用时间
#use_column_value => true
#追踪的字段
#tracking_column => id
tracking_column_type => "timestamp"
}
2、/usr/local/logstash/confifig/conf.d/sql目录下新建increment_jdbc.sql文件
increment_jdbc.sql内容如下
此处sql尽量保持与全量一致Select后的
4、重启容器
上述步骤完成后重启容器
5、查看之前的数据
}
# 过滤部分(不是必须项)
filter {
json {
source => "message"
remove_field => ["message"]
}
}
# 输出部分
output {
elas
t
i
c
s
ea
rc
h
{
#
e
l
a
st
ic
se
arch索引名
index => "product"
# elasticsearch的ip和端口号
hosts => ["172.188.0.88:9200","172.188.0.89:9201","172.188.0.90:9202"]
# 同步mysql中数据id作为elasticsearch中文档id
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
cd /usr/local/logstash/config/conf.d/sql
vi increment_jdbc.sql
SELECT
id,
TRIM( REPLACE ( product_name, ' ', '' ) ) AS productname,
price
FROM product where update_time > :sql_last_value
# 启动
docker restart 容器id
6、在数据库中插入数据
7、查看logstash运行日志
稍等片刻
8、查看es数据
9、同步原理
last_run_metadata_path=>"/usr/share/logstash/.logstash_jdbc_last_run"
在容器里面的/usr/share/logstash/路径下的隐藏文件.logstash_jdbc_last_run中记录了全量同步的
UTC时间
坑:
如果你的数据库使用了mycat分库分表,当前的方案是有问题的,可以使用其他方案代替
因为:Logstah通过你设置的分页执行业务sql,在业务sql中,logstash对sql语句进行了包装
(为了分页;套了一层);count前面加了反斜杠,在mysql中是不识别的
替代方案,可以使用自动追踪(不走分页):
use_column_value => true
追踪的字段
tracking_column => updatetime
追踪的类型
http://172.17.0.225:9200/_cat/count/product?v
INSERT INTO `
p
ro
du
c
t
`
(
`
i
d
`
,
`
p
ro
d
uct_name`, `price`)
VALUES('12196
0
0
00
'
,
't
es
t
0
0
1
'
,1
0
0
)
;
INSERT INT
O `product` (`id`, `product_name`, `price`)
VALUES('121260001','test002',300);
docker logs -f --tail=100 容器id
http://172.17.0.225:9200/_cat/count/product_list_info?v
#进入容器
docker exec -it 4f95a47f12de /bin/bash
#查看记录点
cat /usr/share/logstash/.logstash_jdbc_last_run
tracking_column_type => "timestamp"
第一次在logstash_jdbc_last_run维护下时间
Logstash每次通过updatetime作为查询条件查询,然后将最大的日期写入到
logstash_jdbc_last_run
这里的日期和上面不一样,上面分页的日期是调度开始的时间,这里的时间是业务数据库的时间
每次同步完成记录该时间(重要)
注意
logstash_jdbc_last_run默认是没有的,执行增量后创建
文件也是可以删除的
容器重启会自动创建
3 电商平台全文检索与分词技术
3.1 电商平台全文检索
需求
京东搜索【华为全面屏】,搜索结果包含了华为各个产品线的数据【手机】【全面屏手机】【手机贴膜】
【华为笔记本】【华为电视】等等...
搜索结果(手机)
搜索结果(钢化膜)
搜索结果(笔记本、电视)
全面屏实现目标
模拟京东的全文检索
,
实
现
以
下
几
个
维度
1、通过关键字进行
全
文
匹
配
产
品
搜
索
2、从海量数据
中索取数据做到近实时
3、获取全部
产品实现分页逻辑
4、检索后的产品进行关键字高亮显示
5、高度具象,抽取出开放API
3.2 传统实现方式
1、MySql的实现方式
查询包含【华为全面屏】的所有数据
不考虑多个like语句进行union操作
效率太低无法使用
查询结果
GET /_analyze
{
"analyzer": "ik_smart",
"text": "网红蓝瘦香菇喊麦全面屏"
}
SELECT
id,
trim( REPLACE ( product_name, ' ', '' ) ) AS productname,
price,
trim( REPLACE ( store_name, ' ', '' ) ) AS storename,
eval_count AS evalcount,
purchase_index AS purchaseindex,
trim( REPLACE ( store_type, ' ', '' ) ) AS storetype,
trim( REPLACE ( sku, ' ', '' ) ) AS sku,
trim( REPLACE ( one_level_category, ' ', '' ) ) AS onelevel,
trim( REPLACE ( two_level_category, ' ', '' ) ) AS twolevel,
trim( REPLACE ( three_level_category, ' ', '' ) ) AS threelevel,
trim( REPLACE ( four_level_category, ' ', '' ) ) AS fourlevel,
update_time AS updatetime
FROM
product_list
WHERE
product_name LIKE '%华为全面屏%' LIMIT 0,10000
3.3 分布式框架集成
版本说明:
Spring Cloud 集成Spring Cloud aɹ ibaba
https://github.com/alibaba/spring-cloud
alibaba/wiki/%E7%89%88%E6%9C%AC%E8%AF%B4%E6%98%8E
3.4 终搜平台实现方式
1)配置编写与全文检索编写
1、Es高阶客户端连接Elasticsearch:
package com.itheima.config;
import org.apache.http.HttpHost;
import org.apache.http.client.config.RequestConfig;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Class: ElasticsearchConfig
* @Package com.itheima.config
* @Description: 配置类:构建Elasticsearch客户端连接配置
* @Company: http://www.itheima.com/
*/
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticsearchConfig {
//es集群ip
private String cluster_host;
//es集群节点一端口
private Integer eNode1_port;
//es集群节点二端口
private Integer eNode2_port;
//es集群节点三端口
private Integer eNode3_port;
/**
* 超时时间设为5分钟
*/
private static final int TIME_OUT = 5 * 60 * 1000;
/*
* @Descr
iption:
* @Me
t
h
od
: Es高阶客户端构建器
* @Pa
ra
m
:
* @
U
pd
a
t
e
:
* @
si
n
c
e
:
1.0.0
* @Return:
*
*/
@Bean
public RestClientBuilder restClientBuilder() {
return RestClient.builder(
new HttpHost(cluster_host, eNode1_port, "http"),
new HttpHost(cluster_host, eNode2_port, "http"),
new HttpHost(cluster_host, eNode3_port, "http"));
}
/*
* @Description: 构建Es高阶客户端
* @Method: highLevelClient
* @Param: [restClientBuilder]
* @Update:
* @since: 1.0.0
* @Return: org.elasticsearch.client.RestHighLevelClient
*
*/
@Bean(destroyMethod = "close")
public RestHighLevelClient highLevelClient(@Autowired RestClientBuilder
restClientBuilder) {
restClientBuilder.setRequestConfigCallback(
new RestClientBuilder.RequestConfigCallback() {
@Override
public RequestConfig.Builder customizeRequestConfig(
RequestConfig.Builder requestConfigBuilder) {
return requestConfigBuilder.setSocketTimeout(TIME_OUT);
}
});
return new RestHighLevelClient(restClientBuilder);
}
public String getCluster_host() {
return cluster_host;
}
public void setCluster_host(String cluster_host) {
this.cluster_host = cluster_host;
全文检索代码编写:
1、编写全文检索接口
}
public Integer geteNode1_port() {
return eNode1_port;
}
public void seteNode1_port(Integer eNode1_port) {
this.eNode1_port = eNode1_port;
}
public In
teger geteNode2_port() {
re
turn eNode2_port;
}
publ
ic void seteNode2_port(Integer eNode2_port) {
this.eNode2_port = eNode2_port;
}
public Integer geteNode3_port() {
return eNode3_port;
}
public void seteNode3_port(Integer eNode3_port) {
this.eNode3_port = eNode3_port;
}
}
package com.itheima.service;
import com.itheima.commons.pojo.CommonEntity;
import org.elasticsearch.action.DocWriteResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import java.util.List;
import java.util.Map;
/**
* @Class: ElasticsearchDocumentService
* @Package com.itheima.service
* @Description: 文档操作接口
* @Company: http://www.itheima.com/
*/
public interface ElasticsearchDocumentService {
//全文检索
public SearchResponse matchQuery(CommonEntity commonEntity) throws
Exception;
}
2、编写全文检索实现
/*
* @Descr
i
p
t
i
o
n
:
全
文
检
索
* 使用mat
c
h
Q
u
e
r
y
在
执
行
查
询时,搜索的词会被分词器分词
* @Method: searchMatch
* @Pa
ra
m
:
[indexName, key, value]
* @U
pd
a
te
:
* @
s
i
nc
e
:
1
.0
.0
* @
R
e
t
u
rn
:
o
rg
.elasticsearch.search.SearchHit[]
*
*/
public SearchResponse matchQuery(CommonEntity commonEntity) throws Exception
{
//构建查询响应
SearchResponse response = null;
//构建查询请求用来完成和搜索文档,聚合,建议等相关的任何操作同时也提供了各种方式来完成
对查询结果的高亮操作。
SearchRequest searchRequest = new
SearchRequest(commonEntity.getIndexName());
//构建DSL请求体;trackTotalHits如果不设置true,查询数据最大值还是10000
SearchSourceBuilder searchSourceBuilder = new
SearchSourceBuilder().trackTotalHits(true);
//获取前端的查询条件(Map查询条件)
getClientConditions(commonEntity, searchSourceBuilder);
//高亮设置
searchSourceBuilder.highlighter(SearchTools.getHighlightBuilder(commonEntity.ge
tHighlight()));
//前端页码
int pageNumber = commonEntity.getPageNumber();
//前端每页数量
int pageSize = commonEntity.getPageSize();
//计算查询的下标
int dest = (pageNumber - 1) * pageSize;
searchSourceBuilder.from(dest);
//每页数量
searchSourceBuilder.size(pageSize);
//查询条件对象放入请求对象中
searchRequest.source(searchSourceBuilder);
//方法执行开始时间
long startTime = System.currentTimeMillis();
System.out.println("开始Elasticsearch查询...");
//执行远程查询
response = client.search(searchRequest, RequestOptions.DEFAULT);
//计算远程查询耗时
System.out.println("结束Elasticsearch查询总耗时:" +
(System.currentTimeMillis() - startTime) + "毫秒");
//处理高亮
SearchTools.setHighResultForCleintUI(response,
commonEntity.getHighlight());
return response;
3、编写控制器
}
@RestController
@RequestMappi
n
g
(
"v
1/
d
o
cs
")
public class
E
la
s
ti
c
s
ea
rc
hDocController {
private static final Logger logger = LoggerFactory
.g
e
tLogger(ElasticsearchDocController.class);
@Aut
o
wi
r
ed
Elas
t
i
c
searchDocumentService elasticsearchDocumentService;
/*
* @Description: 全文检索
* @Method: matchQuery
* @Param: [commonEntity]
* @Update:
* @since: 1.0.0
* @Return: com.itheima.commons.result.ResponseData
*
*/
@GetMapping(value = "/mquery")
public ResponseData matchQuery(@RequestBody CommonEntity commonEntity) {
// 构造返回数据
ResponseData rData = new ResponseData();
//批量查询返回结果
SearchResponse result = null;
try {
//通过高阶API调用批量新增操作方法
result = elasticsearchDocumentService.matchQuery(commonEntity);
//查询数量除以每页数量 等于合计分页数量
long aSize = result.getHits().getTotalHits().value;
logger.info("总数据量:" + aSize + "条");
int cSize = result.getHits().getHits().length;
logger.info("当前获取数据:" + cSize + "条");
//通过类型推断自动装箱(多个参数取交集)
rData.setResultEnum(result.getHits().getHits(), ResultEnum.success,
Integer.valueOf(String.valueOf(aSize)));
//日志记录
logger.info(TipsEnum.batch_get_doc_success.getMessage());
} catch (Exception e) {
//打印到控制台
e.printStackTrace();
//日志记录
logger.error(TipsEnum.batch_get_doc_fail.getMessage());
//构建错误返回信息
rData.setResultEnum(ResultEnum.error);
}
return rData;
}
}
4、配置文件编写
service-elasticsearch-dev.yml
bootstrap.yml
server-addr:
C:\Users\My\nacos\confifig
2) 服务网关路由全局配置
http://172.17.0.225:8848/nacos/
server:
port: 8888
spring:
sleuth:
sampler:
pr
o
bability: 1.0 # 将采样比例设置为 1.0,也就是全部都需要。默认是 0.1
zipkin
:
base-url: http://172.17.0.225:9411/ # 指定了 Zipkin 服务器的地址
cloud:
nacos:
discovery:
server-addr: 172.17.0.225:8848,172.17.0.225:8849,172.17.0.225:8850
elasticsearch:
cluster_host: 172.17.0.225
eNode1_port: 9200
eNode2_port: 9201
eNode3_port: 9202
spring:
application:
name: service-elasticsearch #微服务名称,对应dataId
profiles:
active: dev
cloud:
nacos:
config:
#配置中心服务地址
server-addr: 172.17.0.225:8848,172.17.0.225:8849,172.17.0.225:8850
#配置中心文件类型
file-extension: yml
#配置中心编码
encode: utf-8
management:
endpoints:
web:
exposure:
include: '*'
bootstrap.yml
service-gateway-dev.yml
spring:
application:
name: service-gateway
profiles:
active: dev
cloud:
nacos:
config:
#配置中心文件类型
f
i
l
e-
ex
t
en
sion: yml
#配置
中
心
服
务
地
址
se
rv
e
r-
addr: 172.17.0.225:8848,172.17.0.225:8849,172.17.0.225:8850
#配置
中
心
编
码
encode: utf-8
server:
port: 6666
spring:
sleuth:
sampler:
probability: 1.0 # 将采样比例设置为 1.0,也就是全部都需要。默认是 0.1
zipkin:
base-url: http://172.17.0.225:9411/ # 指定了 Zipkin 服务器的地址
application:
name: service-gateway
cloud:
nacos:
discovery:
server-addr: 172.17.0.225:8848,172.17.0.225:8849,172.17.0.225:8850
gateway:
discovery:
#为true表明Gateway开启服务注册和发现的功能
locator:
#是否与服务发现组件进行结合,通过 serviceId 转发到具体的服务实例。默认为false,设为true便开
启通过服务中心的自动根据 serviceId 创建路由的功能。
#路由访问方式:http://Gateway_HOST:Gateway_PORT/serviceId/**,其中微服务应用名默认大写
访问。
enabled: false
#默认false;serviceId为大写
lowerCaseServiceId: false
routes: #配置路由
- id: service-elasticsearch
uri: lb://service-elasticsearch
predicates:
# 匹配路径转发
- Path=/v1/docs/**,/v1/indices/**
- id: service-analysis
uri: lb://service-analysis
predicates:
# 匹配路径转发
- Path=/v1/analysis/**
4、Postman访问
参数
返回
http://172.17.0.225:6666/v1/docs/mquery
或者
http://127.0.
0.1:8888/v1/docs/mquery
{
"pag
eNumber": 1,
"pageSize": 10,
"indexName": "product_list_info",
"highlight": "productname",
"map": {
"productname": "华为全面屏"
}
}
{
"code": "200",
"desc": "操作成功!",
"data": [
{
"score": 8.343819,
"id": "5818822",
"type": "_doc",
"nestedIdentity": null,
"version": -1,
"seqNo": -2,
"primaryTerm": 0,
"fields": {},
"highlightFields": {
"productname": {
"name": "productname",
"fragments": [
{
"fragment": true
}
],
"fragment": true
}
},
"sortValues": [],
"matchedQueries": [],
"explanation": null,
"shard": null,
"index": "product_list_info",
"clusterAlias": null,
"sourceAsMap": {
"twolevel": "功能箱包",
【笔记本 】
[全面屏手机]
"storename": "鹏若拼购店",
"evalcount": 415097,
"threelevel": "旅行配件",
"storetype": "店铺发货",
"@timestamp": "2020-03-21T19:49:03.148Z",
"purchaseindex": "0",
"onelevel": "箱包皮具",
"price": 40.6,
"fourlevel": null,
"
@
v
e
r
s
io
n
"
:
"
1
"
,
"
p
ro
d
u
c
t
na
m
e
"
:
"
<span style= color:red;font-weight:bold;font
size:15px
;
>
华
为
<
/
s
p
a
n
>
w
a
t
c
h
2
保
护
壳
<
sp
an
s
t
y
l
e
=
c
o
l
o
r
:
r
e
d
;
f
o
n
t
-
w
e
i
g
ht:bold;font
size:15px
;
>
华
为
<
/
s
p
a
n
>
W
a
t
c
hG
T
手
表
保
护
壳
<
s
p
a
n
s
t
y
l
e
=
c
o
l
o
r
:
r
e
d
;
f
o
n
t
weight:b
o
l
d
;f
o
n
t
-
s
iz
e:
1
5
px
;
>
华
为
<
/
s
p
a
n
>
w
a
t
c
h
2p
r
o
黑
色
适
用
:
<
s
p
a
n
s
ty
le=
color:re
d
;
fo
n
t
-w
e
i
g
ht
:b
o
l
d
;
f
on
t-
s
i
z
e
:
1
5
p
x
;
>
华
为
<
/
s
pa
n
>w
at
c
h
2
P
r
o
"
,
"id": 5818822,
"sku": "54011029913",
"updatetime": "2020-03-18T05:01:57.000Z"
},
"innerHits": null,
"sourceRef": {
"fragment": true
},
"sourceAsString": "{\"storetype\":\"店铺发货
\",\"@version\":\"1\",\"@timestamp\":\"2020-03-
21T19:49:03.148Z\",\"price\":40.6,\"sku\":\"54011029913\",\"onelevel\":\"箱包皮具
\",\"id\":5818822,\"evalcount\":415097,\"purchaseindex\":\"0\",\"updatetime\":\"
2020-03-18T05:01:57.000Z\",\"fourlevel\":null,\"twolevel\":\"功能箱包
\",\"threelevel\":\"旅行配件\",\"storename\":\"鹏若拼购店\",\"productname\":\"\\n华
为watch2保护壳华为WatchGT手表保护壳华为watch2pro黑色适用:华为watch2Pro\"}",
"rawSortValues": [],
"fragment": false
}
],
"count": 70854
}
高亮显示:在线html编辑器
HTML代码如下:
4 电商平台结构化搜索与排序
4.1 结构化搜索介绍
结构化搜索(
Structured search) 是指具有内在结构数据的过程。
4.2 电商下结构化搜索
https://c.runoob.com/front-end/61
<span style= color:red;font-weight:bold;font-size:15px;>华为</span>(HUAWEI)
<span style= color:red;font-weight:bold;font-size:15px;>华为</span>mate20pro手机
<span style= color:red;font-weight:bold;font-size:15px;>全面屏</span>亮黑色全网通
8GB+128GB
查询二级类目
价格在【
2000-3000】并且是【京东物流】并且评论数【从大到小进行排序】的商品
4.2.1 传统实现方式
实现查询手机的价格在【
2000-3000】并且是【京东物流】并且评论数【从大到小进行排序】的商品
4.2.2 终搜平台实现方式
1)DSL语法分析
DSL:
ES支持一种JSON格式的查询,叫做DSL,domain specifific language
结构化查询(Query DSL):
query的时候,会先比较查询条件,然后计算分值,最后返回文档结果
结构化过滤(
Filter DSL):
过滤器,对查询结果进行缓存,不会计算相关度,避免计算分值,执行速度非常快
1、结构化查询,需要传递 query 参数
比如match_all、match、fifilter、bool
SELECT
*
FROM
product_list
WHERE
price BETWEEN 2000
AND 3000
AND store_type = '自营'
AND two_l
evel_category = '手机'
ORDER BY
eval_count DESC
GET /_search
{
"query": 各种查询参数
}
2、结构化过滤(
Filter DSL)
term 过滤
term 主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本
数据类型),相当于sql age=26
terms 过滤
terms 允许指定多个
匹配条件。如果某个字段指定了多个值,那么文档需要一起去做匹配。
相当于sql: a
ge in
range 过滤
range 过滤允许我们按照指定范围查找一批数据:
相等于sql between
bool 过滤
用来合并多个过滤条件查询结果的布尔逻辑:
must:多个查询条件的完全匹配,相当于 and。
must_not: 多个查询条件的相反匹配,相当于 not;
should:至少有一个查询条件匹配,相当于 or;
相当于sql and 和or
不常用
exists 和 missing 过滤
用于查找文档是否包含指定字段或没有某个字段,类似于 SQL 语句中的 IS_NULL 条件
{"term": {"age": 26}}
{"terms"
: {"age": [26, 27, 28]}}
{
"range": {
"price": {
"gte": 2000,
"lte": 3000
}
}
}
gt : 大于
lt : 小于
gte : 大于等于
lte :小于等于
电商产品搜索DSL实现
注意:
被查询的字段类型是必须是keyword,这样字段在索引时不会进行分词。如果类型为text,字段值
在索引时会分词,这样反而查不到结果了。
如果映射不满足条件怎么办?
重建索引即可
实现查询价格在
【
2000-3000】并且是【京东物流】并且评论数【从大到小进行排序】的商品
fifilter也常和r
ange范围查询一起结合使用,range范围可供组合的选项
GET product_list_info/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"storetype": "自营"
}
},
{
"term": {
"twolevel": "手机"
}
}
],
"filter": {
"range": {
"price": {
"gte": 2000,
"lte": 3000
}
}
}
}
},
"sort": [
{
"evalcount": {
"order": "desc"
}
}
]
}
2)终搜OpenAPI
接口
控制器代码
package com.itheima.service;
import com.itheima.commons.pojo.CommonEntity;
import org.elasticsearch.action.DocWriteResponse;
import org.el
a
s
t
i
c
s
e
a
r
c
h
.
a
ct
io
n
.
s
ea
r
c
h
.S
e
archResponse;
import org.el
a
s
t
i
c
s
e
a
r
c
h
.
re
st
.R
e
s
t
St
a
t
u
s
;
import org.elasticsearch.search.SearchHit;
import jav
a.util.List;
import j
ava.util.Map;
/**
* @Class: ElasticsearchDocumentService
* @Package com.itheima.service
* @Description: 文档操作接口
* @Company: http://www.itheima.com/
*/
public interface ElasticsearchDocumentService {
//结构化查询
public SearchResponse termQuery(CommonEntity commonEntity) throws Exception;
}
/*
* @Description: 结构化搜索(查询手机在2000-3000元之间、京东物流发货,按照评价进行排
序)
* @Method: termquery
* @Param: [commonEntity]
* @Update:
* @since: 1.0.0
* @Return: com.itheima.commons.result.ResponseData
*
*/
@GetMapping(value = "/tquery")
public ResponseData termQuery(@RequestBody CommonEntity commonEntity) {
// 构造返回数据
ResponseData rData = new ResponseData();
//批量查询返回结果
SearchResponse result = null;
try {
//通过高阶API调用批量新增操作方法
result = elasticsearchDocumentService.termQuery(commonEntity);
//查询数量除以每页数量 等于合计分页数量
long aSize = result.getHits().getTotalHits().value;
logger.info("总数据量:" + aSize + "条");
int cSize = result.getHits().getHits().length;
logger.info("当前获取数据:" + cSize + "条");
//通过类型推断自动装箱(多个参数取交集)
实现类
rData.setResultEnum(result.getHits().getHits(), ResultEnum.success,
Integer.valueOf(String.valueOf(aSize)));
//日志记录
logger.info(TipsEnum.batch_get_doc_success.getMessage());
} catch (Exception e) {
//打印到控制台
e.printStackTrace();
//日志记录
logger.error(TipsEnum.batch_get_doc_fail.getMessage());
/
/
构
建
错
误
返
回
信
息
r
D
at
a.
s
et
Re
s
ul
tEnum(ResultEnum.error);
}
re
turn rData;
}
/*
* @Description:结构化搜索
* @Method: termQuery
* @Param: [commonEntity]
* @Update:
* @since: 1.0.0
* @Return: org.elasticsearch.action.search.SearchResponse
*
*/
public SearchResponse termQuery(CommonEntity commonEntity) throws Exception
{
//构建查询响应
SearchResponse response = null;
//构建查询请求用来完成和搜索文档,聚合,建议等相关的任何操作同时也提供了各种方式来完成
对查询结果的高亮操作。
SearchRequest searchRequest = new
SearchRequest(commonEntity.getIndexName());
//构建DSL请求体trackTotalHits如果不设置true,查询数据最大值还是10000
SearchSourceBuilder searchSourceBuilder = new
SearchSourceBuilder().trackTotalHits(true);
//将前端的dsl查询转化为XContentParser
XContentParser parser = SearchTools.getXContentParser(commonEntity);
//将parser解析成功查询API
searchSourceBuilder.parseXContent(parser);
//高亮设置
searchSourceBuilder.highlighter(SearchTools.getHighlightBuilder(commonEntity.get
Highlight()));
//前端页码
int pageNumber = commonEntity.getPageNumber();
//前端每页数量
int pageSize = commonEntity.getPageSize();
//计算查询的下标
int dest = (pageNumber - 1) * pageSize;
searchSourceBuilder.from(dest);
//每页数量
searchSourceBuilder.size(pageSize);
访问地址
1、公共参数抽取
pageNumber:表示前端页码
pageSize:表示每页显示大小
indexName:要查询的索引名称,不允许为空
sortField:排序的列,可以为空
sortOrder:取值范围ASC DESC ,不区分大小写,可以为空默认为DESC,
//排序
sort(commonEntity, searchSourceBuilder);
//查询条件对象放入请求对象中
searchRequest.source(searchSourceBuilder);
//方法执行开始时间
long startTime = System.currentTimeMillis();
System.out.println("开始Elasticsearch查询...");
//执行
远
程
查
询
respo
n
s
e
=
client.search(searchRequest, RequestOptions.DEFAULT);
//
计
算
远
程
查
询
耗
时
Sy
st
em
.
ou
t
.p
ri
ntln("结束Elasticsearch查询总耗时:" +
(System.
c
u
rr
en
tT
imeMillis() - startTime) + "毫秒");
/
/
处
理
高
亮
SearchTools.setHighResultForCleintUI(response,
commonEntity.getHighlight());
return response;
}
http://172.12.0.225:6666/v1/docs/tquery
或者
http://localhost:8888/v1/docs/tquery
highlight:高亮列,可以为空
2、动态参数解析
排序方式一
{
"pageNumber": 1,
"pageSize": 1,
"indexName": "product_list_info",
"sortField": "evalcount",
"sortOrder": "",
"highlight": "productname",
"map": {
"query": {
"bool": {pageNumber:页码
pageSize:每页显示条数
indexName:不可以为空,查询的索引名称
sortField:排序列,可以为空
sortOrder:可以为空,默认DESC,排序规则【DESC/ASC】
highlight:高亮字段(注意:平台只接受被查询的字段名称)
map:里面的参数为动态DSL参数;可以随意增加(需符合ES规范)系统可自动解析
排序方式二
"must": [
{
"term": {
"storetype": "自营"
}
},
{
"term": {
"twolevel": "手机"
}
}
]
,
"f
ilter": {
"
r
a
ng
e
"
:
{
"
p
ri
ce
": {
"gte": 2000,
"lte": 3000
}
}
}
}
}
}
}
{
"pageNumber": 1,
"pageSize": 1,
"indexName": "product_list_info",
"sortField": "",
"sortOrder": "",
"highlight": "productname",
"map": {
"query": {
"bool": {
"must": [
{
"term": {
"storetype": "自营"
}
返回
},
{
"term": {
"twolevel": "手机"
}
}
],
"filter": {
"range": {
"
p
r
ic
e
"
:
{
"g
t
e
"
: 2000,
"lte": 3000
}
}
}
}
},
"sort": [
{
"evalcount": {
"order": "desc"
}
}
]
}
}
{
"code": "200",
"desc": "操作成功!",
"data": [
{
"score": "NaN",
"id": "197028",
"type": "_doc",
"nestedIdentity": null,
"version": -1,
"seqNo": -2,
"primaryTerm": 0,
"fields": {},
"highlightFields": {
"productname": {
"name": "productname",
"fragments": [
{
"fragment": true
}
],
"fragment": true
}
},
"sortValues": [
1067122
],
"matchedQueries": [],
"explanation": null,
"shard": null,
"index": "product_list_info",
"clusterAlias": null,
"sourceAsMap": {
"twolevel": "手机",
"storename": "荣耀京东自营旗舰店",
"
ev
a
l
co
u
nt
"
:
10
67
12
2
,
"t
h
re
e
le
v
el
"
:
"手
机
"
,
"
st
o
re
t
y
p
e
"
:
"
自
营
"
,
"@
t
im
e
s
ta
m
p
"
:
"
2
02
0
-03-21T20:01:41.981Z",
"
pu
rc
h
a
se
i
n
de
x"
:
"
0"
,
"o
ne
le
v
e
l
"
:
"手
机
通
讯
"
,
"price": 2699.0,
"fourlevel": null,
"@version": "1",
"productname": "荣耀20李现同款4800万超广角AI四摄3200W美颜自拍麒麟
Kirin980全网通版8GB+256GB蓝水翡翠全面屏<span style= color:red;font-weight:bold;font
size:15px;>手机</span>",
"id": 197028,
"sku": "100006268939",
"updatetime": "2020-03-17T17:00:07.000Z"
},
"innerHits": null,
"sourceRef": {
"fragment": true
},
"sourceAsString": "{\"storetype\":\"自营
\",\"@version\":\"1\",\"@timestamp\":\"2020-03-
21T20:01:41.981Z\",\"price\":2699.0,\"sku\":\"100006268939\",\"onelevel\":\"手机
通讯
\",\"id\":197028,\"evalcount\":1067122,\"purchaseindex\":\"0\",\"updatetime\":\"
2020-03-17T17:00:07.000Z\",\"fourlevel\":null,\"twolevel\":\"手机
\",\"threelevel\":\"手机\",\"storename\":\"荣耀京东自营旗舰店
\",\"productname\":\"\\n荣耀20李现同款4800万超广角AI四摄3200W美颜自拍麒麟Kirin980全网通
版8GB+256GB蓝水翡翠全面屏手机\"}",
"rawSortValues": [],
"fragment": false
}
],
"count": 29
}
