
面试题:已看1
面试总结——Java高级工程师(三)
面试前面也总结了一和二, 这第三篇可能更偏向于是内心的独白篇和面试技巧总结吧.....
一
三、面试题基础总结
1、 JVM结构原理、GC工作机制详解
答:具体参照:JVM结构、GC工作机制详解 ,说到GC,记住两点:1、GC是负责回收所有无任何引用对象的内存空间。 注意:垃圾回收回收的是无任何引用的对象占据的内存空间而不是对象本身,2、GC回收机制的两种算法,a、引用计数法 b、可达性分析算法( 这里的可达性,大家可以看基础2 Java对象的什么周期),至于更详细的GC算法介绍,大家可以参考:Java GC机制算法
从左图可知,JVM主要包括四个部分:
1.类加载器(ClassLoader):在JVM启动时或者在类运行时将需要的class加载到JVM中。(右图表示了从java源文件到JVM的整个过程,可配合理解。 关于类的加载机制,可以参考http://blog.csdn.net/tonytfjing/article/details/47212291)
2.执行引擎:负责执行class文件中包含的字节码指令(执行引擎的工作机制,这里也不细说了,这里主要介绍JVM结构);
3.内存区(也叫运行时数据区):是在JVM运行的时候操作所分配的内存区。运行时内存区主要可以划分为5个区域,如图:

- 方法区(Method Area):用于存储类结构信息的地方,包括常量池、静态变量、构造函数等。虽然JVM规范把方法区描述为堆的一个逻辑部分, 但它却有个别名non-heap(非堆),所以大家不要搞混淆了。方法区还包含一个运行时常量池。
- java堆(Heap):存储java实例或者对象的地方。这块是GC的主要区域(后面解释)。从存储的内容我们可以很容易知道,方法区和堆是被所有java线程共享的。
- java栈(Stack):java栈总是和线程关联在一起,每当创建一个线程时,JVM就会为这个线程创建一个对应的java栈。在这个java栈中又会包含多个栈帧,每运行一个方法就创建一个栈帧,用于存储局部变量表、操作栈、方法返回值等。每一个方法从调用直至执行完成的过程,就对应一个栈帧在java栈中入栈到出栈的过程。所以java栈是线程私有的。
- 程序计数器(PC Register):用于保存当前线程执行的内存地址。由于JVM程序是多线程执行的(线程轮流切换),所以为了保证线程切换回来后,还能恢复到原先状态,就需要一个独立的计数器,记录之前中断的地方,可见程序计数器也是线程私有的。
- 本地方法栈(Native Method Stack):和java栈的作用差不多,只不过是为JVM使用到的native方法服务的。
垃圾收集器一般必须完成两件事:检测出垃圾;回收垃圾。怎么检测出垃圾?一般有以下几种方法:
引用计数法:给一个对象添加引用计数器,每当有个地方引用它,计数器就加1;引用失效就减1。
好了,问题来了,如果我有两个对象A和B,互相引用,除此之外,没有其他任何对象引用它们,实际上这两个对象已经无法访问,即是我们说的垃圾对象。但是互相引用,计数不为0,导致无法回收,所以还有另一种方法:
可达性分析算法:以根集对象为起始点进行搜索,如果有对象不可达的话,即是垃圾对象。这里的根集一般包括java栈中引用的对象、方法区常良池中引用的对象
1.标记-清除(Mark-sweep)
算法和名字一样,分为两个阶段:标记和清除。标记所有需要回收的对象,然后统一回收。这是最基础的算法,后续的收集算法都是基于这个算法扩展的。
不足:效率低;标记清除之后会产生大量碎片。效果图如下:
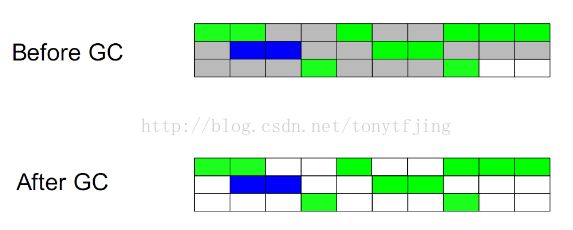
2.复制(Copying)
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。此算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。效果图如下:
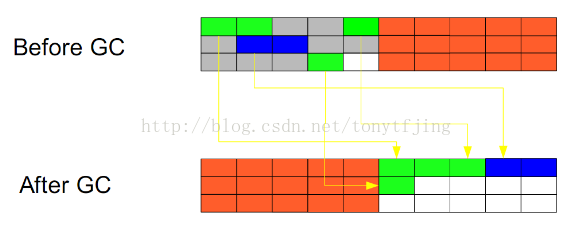
3.标记-整理(Mark-Compact)
此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,把清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。效果图如下:
2、Java对象的生命周期
答:创建阶段 、 应用阶段 、不可见阶段 、不可达阶段 、收集阶段 、终结阶段、 对象空间重新分配阶段等等,具体参照:Java 对象的生命周期
3、Map或者HashMap的存储原理
答:HashMap是由数组+链表的一个结构组成,具体参照:HashMap的实现原理
4、当数据表中A、B字段做了组合索引,那么单独使用A或单独使用B会有索引效果吗?(使用like查询如何有索引效果)
答:看A、B两字段做组合索引的时候,谁在前面,谁在后面,如果A在前,那么单独使用A会有索引效果,单独使用B则没有,反之亦然。同理,使用like模糊查询时,如果只是使用前面%,那么有索引效果,如果使用双%号匹配,那么则无索引效果
5、数据库存储日期格式时,如何考虑时区转换问题?
答:使用TimeStamp , 原因参照:Java编程中遇到的时区转换问题
6、Java Object类中有哪些方法?
7、HTTP协议,GET和POST 的区别
四、线程、设计模式、缓存方面
1、SimpleDataFormat是非线程安全的,如何更好的使用而避免风险呢
答:关于SimpleDateFormat安全的时间格式化线程安全问题
2、如何看待设计模式,并简单说说你对观察者模式的理解
3、集群环境中,session如何实现共享
答:1、Java集群之session共享 2、session多服务器共享方案,还有一种方案就是使用一个固定的服务器专门保持session,其他服务器共享
4、分布式、集群环境中,缓存如何刷新,如何保持同步?
答:A、缓存如何刷新? 1、定时刷新 2、主动刷新覆盖 ,每个缓存框架都有自带的刷新机制,或者说缓存失效机制,就拿Redis和 Ehcache举例, 他们都有自带的过期机制,另外主动刷新覆盖时,只需获取对应的key进行数据的覆盖即可
B、缓存如何保持同步? 这个redis有自带的集群同步机制,即复制功能,具体参考:基于Redis分布式缓存实现 ,Ehcache也有分布式缓存同步的配置,只需要配置不同服务器地址即可,参照:Ehcache分布式缓存同步
5、一条sql执行过长的时间,你如何优化,从哪些方面?
答:1、查看sql是否涉及多表的联表或者子查询,如果有,看是否能进行业务拆分,相关字段冗余或者合并成临时表(业务和算法的优化)
2、涉及链表的查询,是否能进行分表查询,单表查询之后的结果进行字段整合
3、如果以上两种都不能操作,非要链表查询,那么考虑对相对应的查询条件做索引。加快查询速度
4、针对数量大的表进行历史表分离(如交易流水表)
5、数据库主从分离,读写分离,降低读写针对同一表同时的压力,至于主从同步,mysql有自带的binlog实现 主从同步
6、explain分析sql语句,查看执行计划,分析索引是否用上,分析扫描行数等等
7、查看mysql执行日志,看看是否有其他方面的问题
个人理解:从根本上来说,查询慢是占用mysql内存比较多,那么可以从这方面去酌手考虑
五、设计方案相关
面试还会问到一些关于设计方案相关的问题,比如
1、你的接口服务数据被人截包了,你如何防止数据恶意提交?
答:我们可以在接口传输参数里面设置一个业务编号,这个编号用来区分是否重复提交。这样即使数据被抓包了,对方也无法区分每个字段你的含义,这时,这个业务编号的作用就来了
2、假设服务器经常宕机,你从哪些方面去排查问题?
答:这个就留个各位看官补充了,可评论回复
面试技巧就补充这些,后面如果记得什么在补充,如果有其他小伙伴有其他建议,也可以在评论回复,其他面试问题还包括算法、数据结构、http协议等等,这些等待大家自己去补充学习了,Spring的原理,Spring mvc的原理问的也挺多的,大家有时间可以看看之前的面试总结——高级JAVA工程(一)和面试总结——高级JAVA工程师(二) 。
总而言之该看的还是得看,还学的还是得学。再次强调,基础很重要!面试技巧同样很重要,还是那句话:祝愿各位看官都能找到心仪的工作吧~~
另外,奉劝大家不要频繁跳槽,这些知识点能提升固然好,不要盲目跳槽,找工作很累的,而且没有哪家公司喜欢频繁跳槽的员工

 浙公网安备 33010602011771号
浙公网安备 33010602011771号