


Redis(十九):Redis压力测试工具benchmark
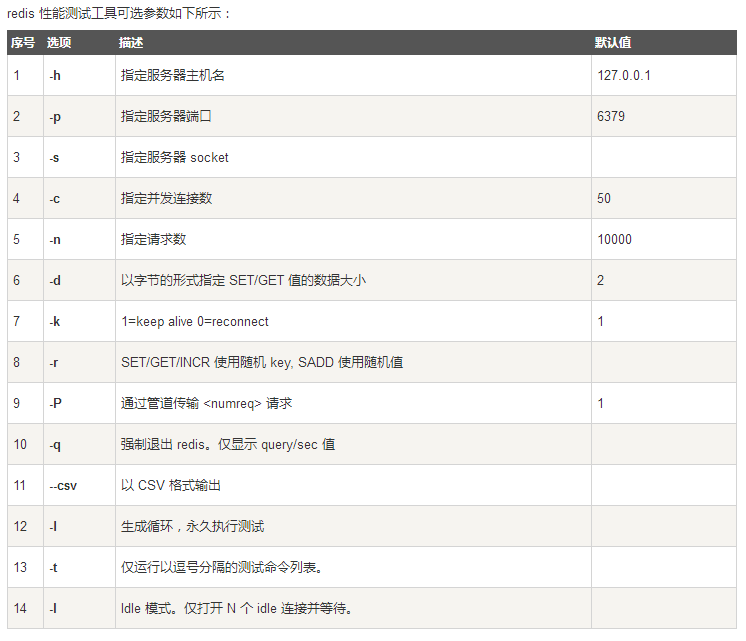
redis-benchmark使用参数介绍
Redis 自带了一个叫 redis-benchmark 的工具来模拟 N 个客户端同时发出 M 个请求。 (类似于 Apache ab 程序)。你可以使用 redis-benchmark -h 来查看基准参数。
以下参数被支持: Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests]> [-k <boolean>] -h <hostname> Server hostname (default 127.0.0.1) -p <port> Server port (default 6379) -s <socket> Server socket (overrides host and port) -a <password> Password for Redis Auth -c <clients> Number of parallel connections (default 50) -n <requests> Total number of requests (default 100000) -d <size> Data size of SET/GET value in bytes (default 2) -dbnum <db> SELECT the specified db number (default 0) -k <boolean> 1=keep alive 0=reconnect (default 1) -r <keyspacelen> Use random keys for SET/GET/INCR, random values for SADD Using this option the benchmark will expand the string __rand_int__ inside an argument with a 12 digits number in the specified range from 0 to keyspacelen-1. The substitution changes every time a command is executed. Default tests use this to hit random keys in the specified range. -P <numreq> Pipeline <numreq> requests. Default 1 (no pipeline). -q Quiet. Just show query/sec values --csv Output in CSV format -l Loop. Run the tests forever -t <tests> Only run the comma separated list of tests. The test names are the same as the ones produced as output. -I Idle mode. Just open N idle connections and wait.
压测命令:redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000
压测示例
压测需要一段时间,因为它需要依次压测多个命令的结果,如:get、set、incr、lpush等等,所以我们需要耐心等待,如果只需要压测某个命令,如:get,那么可以在以上的命令后加一个参数-t(红色部分):
1、redis-benchmark -h 127.0.0.1 -p 6086 -c 50 -n 10000 -t get
C:\Program Files\Redis>redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -t get ====== GET ====== 10000 requests completed in 0.16 seconds 50 parallel clients 3 bytes payload keep alive: 1 99.53% <= 1 milliseconds 100.00% <= 1 milliseconds 62893.08 requests per second
2、redis-benchmark -h 127.0.0.1 -p 6086 -c 50 -n 10000 -t set
C:\Program Files\Redis>redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -t set ====== SET ====== 10000 requests completed in 0.18 seconds 50 parallel clients 3 bytes payload keep alive: 1 87.76% <= 1 milliseconds 99.47% <= 2 milliseconds 99.51% <= 7 milliseconds 99.74% <= 8 milliseconds 100.00% <= 8 milliseconds 56179.77 requests per second
这样看起来数据很多,如果我们只想看最终的结果,可以带上参数-q,完整的命令如下:
3、redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -q
C:\Program Files\Redis>redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -q PING_INLINE: 63291.14 requests per second PING_BULK: 62500.00 requests per second SET: 49261.09 requests per second GET: 47619.05 requests per second INCR: 42194.09 requests per second LPUSH: 61349.69 requests per second RPUSH: 56818.18 requests per second LPOP: 47619.05 requests per second RPOP: 45045.04 requests per second SADD: 46296.30 requests per second SPOP: 59523.81 requests per second LPUSH (needed to benchmark LRANGE): 56818.18 requests per second LRANGE_100 (first 100 elements): 32362.46 requests per second LRANGE_300 (first 300 elements): 13315.58 requests per second LRANGE_500 (first 450 elements): 10438.41 requests per second LRANGE_600 (first 600 elements): 8591.07 requests per second MSET (10 keys): 55248.62 requests per second
4、使用 pipelining
默认情况下,每个客户端都是在一个请求完成之后才发送下一个请求 (benchmark 会模拟 50 个客户端除非使用 -c 指定特别的数量), 这意味着服务器几乎是按顺序读取每个客户端的命令。Also RTT is payed as well.
真实世界会更复杂,Redis 支持 /topics/pipelining,使得可以一次性执行多条命令成为可能。 Redis pipelining 可以提高服务器的 TPS。 下面这个案例是在 Macbook air 11” 上使用 pipelining 组织 16 条命令的测试范例:
$ redis-benchmark -n 1000000 -t set,get -P 16 -q SET: 403063.28 requests per second GET: 508388.41 requests per second
记得在多条命令需要处理时候使用 pipelining。
陷阱和错误的认识
第一点是显而易见的:基准测试的黄金准则是使用相同的标准。 用相同的任务量测试不同版本的 Redis,或者用相同的参数测试测试不同版本 Redis。 如果把 Redis 和其他工具测试,那就需要小心功能细节差异。
- Redis 是一个服务器:所有的命令都包含网络或 IPC 消耗。这意味着和它和 SQLite, Berkeley DB, Tokyo/Kyoto Cabinet 等比较起来无意义, 因为大部分的消耗都在网络协议上面。
- Redis 的大部分常用命令都有确认返回。有些数据存储系统则没有(比如 MongoDB 的写操作没有返回确认)。把 Redis 和其他单向调用命令存储系统比较意义不大。
- 简单的循环操作 Redis 其实不是对 Redis 进行基准测试,而是测试你的网络(或者 IPC)延迟。想要真正测试 Redis,需要使用多个连接(比如 redis-benchmark), 或者使用 pipelining 来聚合多个命令,另外还可以采用多线程或多进程。
- Redis 是一个内存数据库,同时提供一些可选的持久化功能。 如果你想和一个持久化服务器(MySQL, PostgreSQL 等等) 对比的话, 那你需要考虑启用 AOF 和适当的 fsync 策略。
- Redis 是单线程服务。它并没有设计为多 CPU 进行优化。如果想要从多核获取好处, 那就考虑启用多个实例吧。将单实例 Redis 和多线程数据库对比是不公平的。
影响 Redis 性能的因素
有几个因素直接决定 Redis 的性能。它们能够改变基准测试的结果, 所以我们必须注意到它们。一般情况下,Redis 默认参数已经可以提供足够的性能, 不需要调优。
- 网络带宽和延迟通常是最大短板。建议在基准测试之前使用 ping 来检查服务端到客户端的延迟。根据带宽,可以计算出最大吞吐量。 比如将 4 KB 的字符串塞入 Redis,吞吐量是 100000 q/s,那么实际需要 3.2 Gbits/s 的带宽,所以需要 10 GBits/s 网络连接, 1 Gbits/s 是不够的。 在很多线上服务中,Redis 吞吐会先被网络带宽限制住,而不是 CPU。 为了达到高吞吐量突破 TCP/IP 限制,最后采用 10 Gbits/s 的网卡, 或者多个 1 Gbits/s 网卡。
- CPU 是另外一个重要的影响因素,由于是单线程模型,Redis 更喜欢大缓存快速 CPU, 而不是多核。这种场景下面,比较推荐 Intel CPU。AMD CPU 可能只有 Intel CPU 的一半性能(通过对 Nehalem EP/Westmere EP/Sandy 平台的对比)。 当其他条件相当时候,CPU 就成了 redis-benchmark 的限制因素。
- 在小对象存取时候,内存速度和带宽看上去不是很重要,但是对大对象(> 10 KB), 它就变得重要起来。不过通常情况下面,倒不至于为了优化 Redis 而购买更高性能的内存模块。
- Redis 在 VM 上会变慢。虚拟化对普通操作会有额外的消耗,Redis 对系统调用和网络终端不会有太多的 overhead。建议把 Redis 运行在物理机器上, 特别是当你很在意延迟时候。在最先进的虚拟化设备(VMWare)上面,redis-benchmark 的测试结果比物理机器上慢了一倍,很多 CPU 时间被消费在系统调用和中断上面。
- 如果服务器和客户端都运行在同一个机器上面,那么 TCP/IP loopback 和 unix domain sockets 都可以使用。对 Linux 来说,使用 unix socket 可以比 TCP/IP loopback 快 50%。 默认 redis-benchmark 是使用 TCP/IP loopback。 当大量使用 pipelining 时候,unix domain sockets 的优势就不那么明显了。
- 当大量使用 pipelining 时候,unix domain sockets 的优势就不那么明显了。
- 当使用网络连接时,并且以太网网数据包在 1500 bytes 以下时, 将多条命令包装成 pipelining 可以大大提高效率。事实上,处理 10 bytes,100 bytes, 1000 bytes 的请求时候,吞吐量是差不多的,详细可以见下图。

- 在多核 CPU 服务器上面,Redis 的性能还依赖 NUMA 配置和 处理器绑定位置。 最明显的影响是 redis-benchmark 会随机使用 CPU 内核。为了获得精准的结果, 需要使用固定处理器工具(在 Linux 上可以使用 taskset 或 numactl)。 最有效的办法是将客户端和服务端分离到两个不同的 CPU 来高校使用三级缓存。 这里有一些使用 4 KB 数据 SET 的基准测试,针对三种 CPU(AMD Istanbul, Intel Nehalem EX, 和 Intel Westmere)使用不同的配置。请注意, 这不是针对 CPU 的测试。

- 在高配置下面,客户端的连接数也是一个重要的因素。得益于 epoll/kqueue, Redis 的事件循环具有相当可扩展性。Redis 已经在超过 60000 连接下面基准测试过, 仍然可以维持 50000 q/s。一条经验法则是,30000 的连接数只有 100 连接的一半吞吐量。 下面有一个关于连接数和吞吐量的测试。

-
在高配置下面,可以通过调优 NIC 来获得更高性能。最高性能在绑定 Rx/Tx 队列和 CPU 内核下面才能达到,还需要开启 RPS(网卡中断负载均衡)。更多信息可以在thread 。Jumbo frames 还可以在大对象使用时候获得更高性能。
-
在不同平台下面,Redis 可以被编译成不同的内存分配方式(libc malloc, jemalloc, tcmalloc),他们在不同速度、连续和非连续片段下会有不一样的表现。 如果你不是自己编译的 Redis,可以使用 INFO 命令来检查内存分配方式。 请注意,大部分基准测试不会长时间运行来感知不同分配模式下面的差异, 只能通过生产环境下面的 Redis 实例来查看。
其他需要注意的点
任何基准测试的一个重要目标是获得可重现的结果,这样才能将此和其他测试进行对比。
- 一个好的实践是尽可能在隔离的硬件上面测试。如果没法实现,那就需要检测 benchmark 没有受其他服务器活动影响。
- 有些配置(桌面环境和笔记本,有些服务器也会)会使用可变的 CPU 分配策略。 这种策略可以在 OS 层面配置。有些 CPU 型号相对其他能更好的调整 CPU 负载。 为了达到可重现的测试结果,最好在做基准测试时候设定 CPU 到最高使用限制。
- 一个重要因素是配置尽可能大内存,千万不要使用 SWAP。注意 32 位和 64 位 Redis 有不同的内存限制。
- 如果你计划在基准测试时候使用 RDB 或 AOF,请注意不要让系统同时有其他 I/O 操作。 避免将 RDB 或 AOF 文件放到 NAS 或 NFS 共享或其他依赖网络的存储设备上面(比如 Amazon EC2 上 的 EBS)。
- 将 Redis 日志级别设置到 warning 或者 notice。避免将日志放到远程文件系统。
- 避免使用检测工具,它们会影响基准测试结果。使用 INFO 来查看服务器状态没问题, 但是使用 MONITOR 将大大影响测试准确度。

