分布式锁的实现方式介绍和代码示例
分布式锁的实现方式介绍
分布式锁的基本原理是通过在分布式环境下协调各个节点之间的操作,确保同一时间只有一个节点可以获取到锁,从而实现对共享资源的独占访问。常见的实现方式有以下几种:
-
基于数据库:可以使用数据库的事务和唯一性约束来实现分布式锁。比如,在数据库中创建一个表,利用唯一性约束(如主键或唯一索引)来保证同一时间只有一个进程可以插入指定的记录,其他进程会因唯一性冲突而无法插入,从而实现锁的效果。
-
基于缓存:可以使用分布式缓存系统(如Redis)的原子操作来实现分布式锁。通过在缓存中设置一个特定的键值对,利用缓存的原子性操作来实现锁的获取和释放。获取锁时尝试设置某个键的值为固定值,如果设置成功则表示获取到锁,设置失败则表示锁已经被其他节点获取。释放锁时删除该键即可。
-
基于ZooKeeper:ZooKeeper是一个分布式协调服务,可以使用它来实现分布式锁。通过在ZooKeeper中创建临时顺序节点,并利用节点的顺序特性来进行竞争。每个节点尝试创建自己的临时顺序节点,创建成功的节点视为获取到锁,创建失败的节点则监听前一个节点的删除事件,当前一个节点删除后,再次尝试创建节点,直至成功。
使用分布式锁可以避免多个进程或线程同时访问共享资源而引起的数据不一致问题,保证系统的正确性。然而,在使用分布式锁时需要注意以下几点:
-
正确处理锁的获取和释放:获取锁时需要确保同一时间只有一个进程可以成功获取到锁,否则可能会导致资源竞争和数据不一致。释放锁时要确保只有持有锁的进程才能释放该锁,否则可能会导致其他进程错误地释放锁。
-
防止死锁:在设计分布式锁时要考虑避免死锁的问题,比如设置合理的超时时间,避免因为某个进程异常退出而导致其他进程一直等待。
-
锁的性能和可用性:分布式锁的实现需要考虑性能和可用性,避免因为锁本身的开销导致系统性能下降或不可用。
总结来说,分布式锁是一种用于分布式系统中实现资源互斥访问的机制,可以通过数据库、缓存或分布式协调服务等方式进行实现。合理地使用分布式锁能够确保系统的正确性和一致性。
基于数据库实现的分布式锁有什么必要前提条件和缺点?
-
数据库支持事务:分布式锁的实现通常要求使用数据库的事务机制来保证操作的原子性和一致性。因此,数据库必须支持事务,并且具备 ACID 特性(原子性、一致性、隔离性、持久性)。
-
数据库具备唯一性约束:为了实现互斥访问,需要在数据库中创建一个表或者利用已有表,并为其设置唯一性约束(例如主键或唯一索引)。这样可以确保同一时间只有一个进程能够插入该表中的记录,从而实现锁的效果。
-
共享数据库连接或共享数据库:多个进程或线程需要共享同一个数据库连接或使用同一个数据库实例来实现分布式锁。这样才能够保证各个进程对数据库中的数据进行操作时能够相互感知到。
基于数据库实现的分布式锁存在一些缺点:
-
性能压力:数据库是一个独立的服务器,使用数据库作为锁的存储介质会带来额外的网络开销和数据库负载。每次获取和释放锁都需要进行数据库的读写操作,对数据库性能产生一定影响。
-
单点故障:数据库通常是一个单点的中心化服务,如果数据库出现故障或性能瓶颈,会影响整个分布式锁的可用性和性能。
-
锁粒度问题:数据库作为一个全局的共享资源,如果锁定的粒度过大,可能导致并发性能下降。而如果锁定的粒度过小,可能会增加数据库操作的复杂度和开销。
-
依赖于数据库的一致性保证:数据库的事务机制和唯一性约束是实现分布式锁的关键,但也意味着分布式锁的正确性和一致性依赖于数据库的正确配置和运行。如果数据库配置不当或出现问题,可能会导致分布式锁的行为不可预期。
综上所述,尽管基于数据库实现的分布式锁可以满足资源互斥访问的需求,但也存在一些必要前提条件和缺点。在使用基于数据库的分布式锁时,需要注意数据库性能、可用性以及锁粒度的问题,并确保数据库的正确配置和运行以保证分布式锁的正确性和一致性。
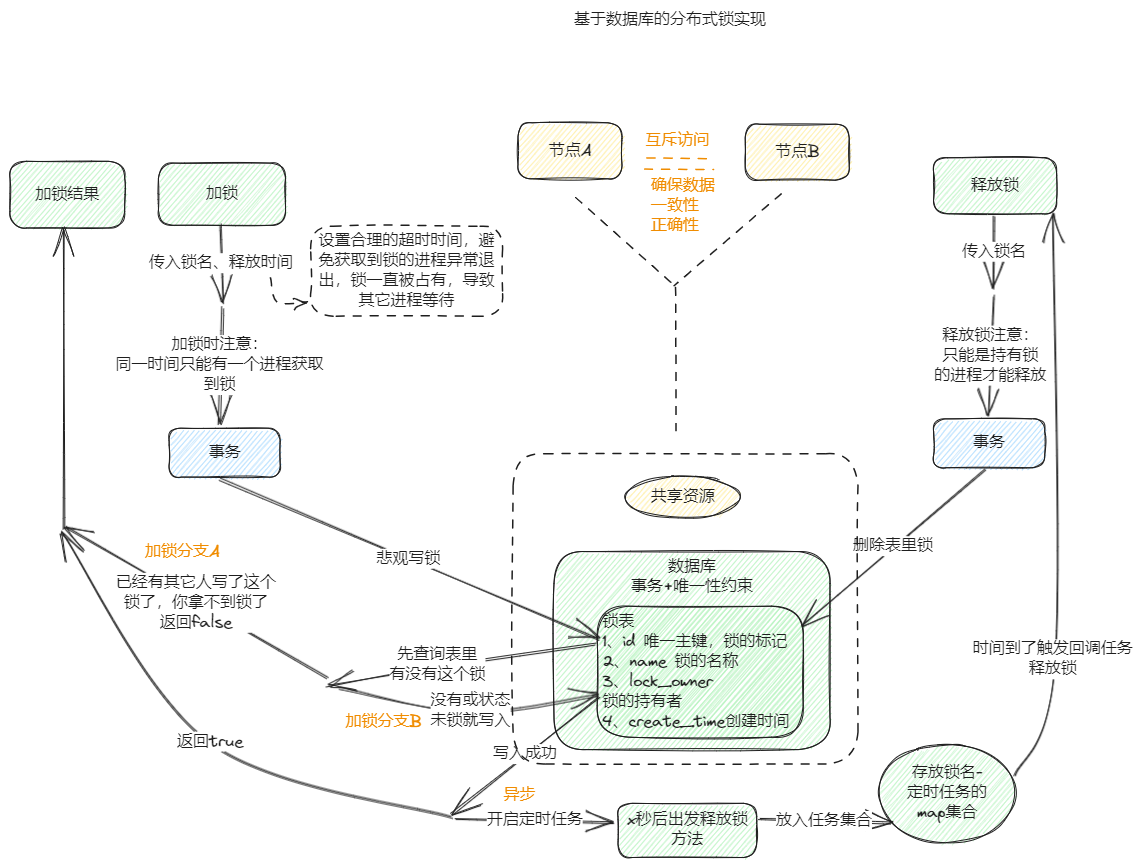
基于mysql数据库的分布式锁实现示例
在Spring Boot中,可以基于MySQL数据库实现分布式锁。以下是一个简单的实现步骤和示例代码:
步骤:
-
创建一个MySQL数据库表,用于存储分布式锁信息。表结构可以包括以下字段:
id: 主键,唯一标识每个锁。name: 锁的名称,用于标识不同的锁。locke_owner: 锁的持有者字段用于存储当前持有该锁的事务、线程或用户标识。created_time: 创建时间,用于记录锁的创建时间。
-
在Spring Boot项目中,创建一个与数据库表对应的实体类(例如
LockEntity),并使用JPA进行持久化操作。 -
创建一个分布式锁工具类(例如
DistributedLockUtil),该工具类封装了获取锁和释放锁的逻辑。 -
在需要加锁的方法中,使用分布式锁工具类获取锁,并执行业务逻辑。如果无法获得锁,则等待或执行相应的处理逻辑。
-
使用完锁后,调用分布式锁工具类释放锁。
下面是一个示例代码:
LockEntity.java:
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class LockEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String lockOwner;
private LocalDateTime createdTime;
// 省略getter和setter方法
}
DistributedLockUtil.java:
关于定时任务部分,使用Spring的taskScheduler调度器来创建一个定时任务,并返回一个ScheduledFuture对象。
taskScheduler.schedule方法接受两个参数:要执行的任务(unlockTask)和任务的触发时间(() -> LocalDateTime.now().plusSeconds(timeoutSeconds))。这里使用了一个lambda表达式来表示触发时间,它会先获取当前时间,然后调用plusSeconds方法添加指定的超时时间(timeoutSeconds),从而计算出任务的触发时间。
然后,调用taskScheduler.schedule方法会将任务添加到任务调度器中,并返回一个ScheduledFuture对象。ScheduledFuture接口是一个可以用来控制和监视定时任务执行的对象,可以用来查看任务是否完成、取消任务执行等。
在示例中,将返回的ScheduledFuture对象存储在future变量中,在需要的时候可以使用它来取消定时任务的执行。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;
import org.springframework.stereotype.Component;
import javax.persistence.EntityManager;
import javax.persistence.LockModeType;
import javax.persistence.Query;
import javax.transaction.Transactional;
import java.time.LocalDateTime;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ScheduledFuture;
@Component
public class DistributedLockUtil {
private final EntityManager entityManager;
private final ThreadPoolTaskScheduler taskScheduler;
private final Map<String, ScheduledFuture<?>> timeoutTasks = new HashMap<>();
@Autowired
public DistributedLockUtil(EntityManager entityManager, ThreadPoolTaskScheduler taskScheduler) {
this.entityManager = entityManager;
this.taskScheduler = taskScheduler;
}
@Transactional
public boolean tryLock(String lockName, long timeoutSeconds) {
LockEntity lockEntity = entityManager.find(LockEntity.class, lockName, LockModeType.PESSIMISTIC_WRITE);
if (lockEntity == null || lockEntity.getLocked() == 0) {
LockEntity newLockEntity = new LockEntity();
newLockEntity.setName(lockName);
newLockEntity.setLocked(1);
newLockEntity.setLockOwner(xxxxx)
newLockEntity.setCreatedTime(LocalDateTime.now());
entityManager.persist(newLockEntity);
scheduleUnlockTask(lockName, timeoutSeconds);
return true;
}
return false;
}
@Transactional
public void releaseLock(String lockName) {
if(判断是不是锁的持有者)
cancelUnlockTask(lockName);
Query query = entityManager.createQuery("DELETE FROM LockEntity WHERE name = :lockName");
query.setParameter("lockName", lockName);
query.executeUpdate();
}
private void scheduleUnlockTask(String lockName, long timeoutSeconds) {
Runnable unlockTask = () -> {
LockEntity lockEntity = entityManager.find(LockEntity.class, lockName, LockModeType.PESSIMISTIC_WRITE);
if (lockEntity != null && lockEntity.getLocked() == 1) {
releaseLock(lockName);
}
};
ScheduledFuture<?> future = taskScheduler.schedule(unlockTask, () -> LocalDateTime.now().plusSeconds(timeoutSeconds));
timeoutTasks.put(lockName, future);
}
private void cancelUnlockTask(String lockName) {
ScheduledFuture<?> future = timeoutTasks.remove(lockName);
if (future != null) {
future.cancel(false);
}
}
}
使用分布式锁的示例:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class MyController {
private final DistributedLockUtil distributedLockUtil;
@Autowired
public MyController(DistributedLockUtil distributedLockUtil) {
this.distributedLockUtil = distributedLockUtil;
}
@RequestMapping("/myEndpoint")
public String myEndpoint() {
boolean isLocked = distributedLockUtil.tryLock("myLock");
if (isLocked) {
try {
// 执行业务逻辑
return "Success";
} finally {
distributedLockUtil.releaseLock("myLock");
}
} else {
// 处理锁被占用的情况
return "Lock Occupied";
}
}
}
以上代码示例演示了如何基于MySQL数据库实现简单的分布式锁。在DistributedLockUtil类中,通过使用EntityManager和JPA提供的悲观写锁(LockModeType.PESSIMISTIC_WRITE)来获取锁。如果锁不存在或者未被锁定,则创建一个新的锁对象并将其写入数据库。tryLock方法返回一个布尔值,指示是否成功获取到锁。在执行完业务逻辑后,通过调用releaseLock方法释放锁。
同时,该示例还引入了ThreadPoolTaskScheduler来创建一个线程池定时任务调度器。timeoutTasks用于保存每个锁的超时任务。
在tryLock方法中,当成功获取到锁时,我们会调用scheduleUnlockTask方法来创建一个定时任务,在指定的超时时间后自动释放锁。该定时任务会执行一个unlockTask,该任务会检查并释放指定的锁。
在releaseLock方法中,我们取消该锁的超时任务。如果存在锁超时并执行了释放操作,那么在tryLock方法中会重新创建新的锁对象和超时任务。
需要注意的是,为了使用ThreadPoolTaskScheduler,您需要在Spring Boot配置文件中添加以下配置:
spring:
task:
scheduling:
pool:
size: 5
上述示例代码中的定时任务调度器默认使用了一个线程池,该线程池可以根据实际需求进行调整。
在使用锁超时机制时,建议根据具体需求和业务场景设置合适的超时时间,以避免长时间的锁占用。
基于redis的分布式锁实现
锁的工具类
import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.core.script.DefaultRedisScript; import org.springframework.stereotype.Component; import java.time.Duration; import java.util.Collections; @Component @Slf4j public class DistributedLockUtil { private static final String LOCK_PREFIX = "DISTRIBUTED_LOCK:"; private static final long LOCK_EXPIRE = 30000L; // 锁的过期时间,单位毫秒 private static final long SLEEP_INTERVAL = 100L; // 获取锁失败后休眠的时间间隔,单位毫秒 @Autowired private RedisTemplate<String, String> redisTemplate; /** * 尝试获取分布式锁 * @param lockKey 锁的key * @param requestId 请求标识,用于释放锁时的校验 * @return 是否成功获取锁 */ public boolean tryLock(String lockKey, String requestId) { String lock = LOCK_PREFIX + lockKey; while (true) { // 尝试获取锁,设置过期时间 Boolean result = redisTemplate.opsForValue().setIfAbsent(lock, requestId, Duration.ofMillis(LOCK_EXPIRE)); if (result != null && result) { // 成功获取锁 log.info("拿到锁:{}", lock); return true; } // 获取锁失败,休眠一段时间后重试 try { Thread.sleep(SLEEP_INTERVAL); } catch (InterruptedException e) { Thread.currentThread().interrupt(); e.printStackTrace(); } } } /** * 释放分布式锁 * @param lockKey 锁的key * @param requestId 请求标识,用于校验释放锁的合法性 */ public void releaseLock(String lockKey, String requestId) { String lock = LOCK_PREFIX + lockKey; // 使用Lua脚本确保原子性操作 String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end"; DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>(script); redisScript.setResultType(Long.class); log.info("释放锁:{}", lock); redisTemplate.execute(redisScript, Collections.singletonList(lock), requestId); } }
Lua脚本的含义介绍
Lua脚本来实现分布式锁的原子释放操作。让我解释一下它的含义:
-
if redis.call('get', KEYS[1]) == ARGV[1]:这部分代码表示通过Redis的get命令获取锁的当前持有者,并将其与传入的ARGV[1](即请求标识)进行比较。 -
then return redis.call('del', KEYS[1]):如果锁的当前持有者与传入的请求标识匹配,这部分代码会执行Redis的del命令来删除该锁,即释放锁。 -
else return 0 end:如果锁的当前持有者与传入的请求标识不匹配,表示该请求不具备释放锁的权限,此时返回0。
通过使用Lua脚本,可以在保证原子性的前提下,检查当前锁的持有者是否与请求方一致,并在一致的情况下释放锁,从而避免因为多个线程同时释放锁而导致的问题。
测试类
@Autowired private DistributedLockUtil distributedLockUtil; private int a = 0; @GetMapping("/tt") @ApiOperation(value = "测试分布式锁") public void tt() { for (int n = 0; n < 4; n++) { new Thread(new Runnable() { @Override public void run() { String lockKey = "test-lock"; String reqId = UUID.randomUUID().toString(); for (int i = 0; i < 1000000; i++) { if(distributedLockUtil.tryLock(lockKey, reqId)){ try { a++; log.info("----------a++{}", a); } finally { distributedLockUtil.releaseLock(lockKey, reqId); } } } log.info("-----------ia:{}", a); } }).start(); } }
注意,为了保证安全和避免死锁,应始终在加锁的代码块结束后释放锁。
锁的释放时间选择
上面的代码中,因为锁的过期时间设置的为30000毫秒,如果持有锁的业务逻辑处理超过了锁的过期时间,就可能会出现问题。原因是:
在分布式锁的实现中,设置了一个过期时间来确保即使持有锁的线程发生故障或未能主动释放锁,锁也会在一定时间后自动释放。这样可以避免死锁的发生。
然而,如果持有锁的业务逻辑处理时间超过了锁的过期时间,那么在业务逻辑执行完之前,锁可能已经自动释放了。这将导致其他线程可能会在业务逻辑尚未完成时获取到该锁,进而引发并发问题或数据不一致的情况。
为了避免该问题,需要根据实际业务情况来合理设置锁的过期时间。确保业务逻辑处理所需时间小于锁的过期时间,以确保持有锁的线程能够顺利完成业务逻辑,并在适当的时候主动释放锁。
另外,还可以考虑在业务逻辑处理时间接近锁的过期时间时,通过续约机制延长锁的过期时间,确保持有锁的线程有足够的时间来完成业务操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号