Java并发编程(四):线程安全性
一、定义
当多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些进程将如何交替执行,并且在主调代码中不需要额外的同步或协同,这个类都能表现出正确的行为,那么就称这个类是线程安全的。
二、线程安全性
1)线程安全性的三个方面
- 原子性:提供了互斥访问,同一时刻只能有一个线程来对它进行操作。
- 可见性:一个线程对主内存的修改可以及时的被其它线程观察到。
- 有序性:一个线程观察其它线程中的指令执行顺序,由于指令重排序的存在,该观察结果一般杂乱无序。
2)原子性-Atomic包

Java并发编程之CAS
1.AtomicXXX:CAS 、Unsafe.compareAndSwapInt
代码演示
import lombok.extern.slf4j.Slf4j; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Semaphore; import java.util.concurrent.atomic.AtomicInteger; /** * 计数到 5000 , 代码运行结果 为 5000 */ @Slf4j public class CountExample2 { // 请求总数 public static int clientTotal = 5000; // 同时并发执行的线程数 public static int threadTotal = 200; public static AtomicInteger count = new AtomicInteger(0); public static void main(String[] args) throws InterruptedException { ExecutorService executorService = Executors.newCachedThreadPool(); // 线程池 final Semaphore semaphore = new Semaphore(threadTotal); //信号量 final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); // 计数器闭锁 for (int i = 0;i<clientTotal;i++) { executorService.execute(() ->{ try { semaphore.acquire(); add(); semaphore.release(); } catch (Exception e) { log.error("exception ", e); } countDownLatch.countDown(); }); } countDownLatch.await(); executorService.shutdown(); log.info("count:{}", count.get()); } private static void add(){ // 先做增加操作, 再获取当前的值 count.incrementAndGet(); // 先获取当前的值, 在做增加操作 // count.getAndIncrement(); } }
来看一下它的实现源码 , Atomic 在实现的时候, 使用了一个 unsafe 的类, unsafe 提供了一个 getAddAddInt的方法 , 来看一下 这个方法的实现
incrementAndGet 方法实现
/** * Atomically increments by one the current value. * * @return the updated value */ public final int incrementAndGet() { return unsafe.getAndAddInt(this, valueOffset, 1) + 1; }
getAndAddInt 方法实现
public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; }
源码说明, 在这个源码实现里 , 用`do while 作为主体实现的 , 在 while 条件里 , 调用了一个核心的方法 compareAndSwapInt
在这个 getAndAddInt 方法里 , 传来的第一个参数是 请求的对象 , 就是上面示例代码里的 count ,第二个值是当前的值 ,比如当前执行的是 2 +1 这个操作, var2 就是 2 ,第三个参数 var4 的值是 1 , 而 var5 是底层当前的值. 如果没有其他线程对对象 count 进行操作, 其返回的底层的值应该是 2 , 此时, 当前值 2 和底层获取到的值 2 是相等的, compareAndSwapInt判断当前参数 var2 和底层var5的值相等, 则执行相加操作 将 底层获取的值 var5 加上 被加数var4 ,这个方法的最终目的就是, 对于这个传过来的 对象 count 如果底层的值和当前的值时相等的, 就将其更新为目标值 .
上面的代码的增加操作中, 在进行 2 + 1 操作的是时候, 对象 count 可能被其他线程更新, 当前值var2 就和 var5 不相等了, 所有就不能更新目标值 ,那么再次取出 底层的值 var5 , var2这个值再重新从当前对象 count 取一次, 再次判断是否符合更新要求 . 就是通过这样不停的循环, 当 var2 与 var5 完全相同的时候, 才进行更新值 . 这个 compareAndSwapInt 的核心 就是所谓的 CAS 的核心.
2.AtomicLong、LongAdder
Atomic 还有提供了 一个 类 AtomicLong , 其实现和 AtomicInteger 一样.
在Java 8 里 , Atomic 提供了 一个 LongAdder 类 , 上面通过看 CAS 底层实现的时候知道了, 它是通过一个死循环,不断的长沙市修改目标值 , 直到修改成功 , 如果并发不是很好的情况下, 修改成功的几率很高 , 如果大量修改失败, 这些原子操作就会进行多次的循环尝试, 因此性能会受到一定的影响. 这里有一个额外的知识点, 对于 long double 类型的变量, jvm 允许将 64 位的读操作者 或者写操作 拆分成两个 32 位的操作 。
LongAdder 这个类的设计 , 其核心是将热点数据分离, 比如它将 AtomicLong 内部的核心数据 value ,分离成一个数组 , 每个线程访问时候, 通过hash 等算法 ,将其映射到其中一个数字进行计数, 而最终的结果呢, 是这个数组的求和累加 . 热点数据value会被分离成多个的cell ,每个cell 独自维护内部的值, 当前对象的值由所有的cell 累计合成. 这样热点数据就进行了有效的分离 , 并提高了并行度 . 这样LongAdder 就相当于在 AtomicLong 基础上, 把单点的更新压力, 分散到各个节点上 。
LongAdder 在低并发的时候通过直接操作base,可以很好的保证和Atomic的性能基本一致,在高并发的场景,通过热点分区来提高并行度。
缺点:在统计的时候如果有并发更新,可能会导致结果有些误差
实际运用中:优先使用LongAdder ,在线程竞争很低的情况下使用AtomicLong效率更高
全局序列号使用AtomicLong。
3.AtomicReference、AtomicReferenceFieldUpdater
AtomicReference: 用法同AtomicInteger一样,但是可以放各种对象
@Slf4j@ThreadSafepublicclassAtomicExample4{publicstaticAtomicReference count =newAtomicReference<>(0);publicstaticvoidmain(String[] args)throwsInterruptedException{// 2count.compareAndSet(0,2);// nocount.compareAndSet(0,1);// nocount.compareAndSet(1,3);// 4count.compareAndSet(2,4);// nocount.compareAndSet(3,5); log.info("count:{}",count.get()); }}
AtomicReferenceFieldUpdater
@Slf4j@ThreadSafepublicclassAtomicExample5{@Getterprivatevolatileintcount =100;/**
* AtomicIntegerFieldUpdater 核心是原子性的去更新某一个类的实例的指定的某一个字段
* 构造函数第一个参数为类定义,第二个参数为指定字段的属性名,必须是volatile修饰并且非static的字段
*/privatestaticAtomicIntegerFieldUpdater updater = AtomicIntegerFieldUpdater.newUpdater(AtomicExample5.class,"count");publicstaticvoidmain(String[] args)throws InterruptedException{ AtomicExample5 example5 =newAtomicExample5();// 第一次 count=100 -> count->120 返回Trueif(updater.compareAndSet(example5,100,120)){log.info("update success 1:{}",example5.getCount()); }// count=120 -> 返回Falseif(updater.compareAndSet(example5,100,120)){log.info("update success 2:{}",example5.getCount()); }else{log.info("update field:{}",example5.getCount()); } }}
5.AtomicStampReference:CAS的ABA问题
ABA问题:在CAS操作的时候,其他线程将变量的值A改成了B由改成了A,本线程使用期望值A与当前变量进行比较的时候,发现A变量没有变,于是CAS就将A值进行了交换操作,这个时候实际上A值已经被其他线程改变过,这与设计思想是不符合的
解决思路:每次变量更新的时候,把变量的版本号加一,这样只要变量被某一个线程修改过,该变量版本号就会发生递增操作,从而解决了ABA变化
/** * Atomically sets the value of both the reference and stamp * to the given update values if the * current reference is {@code==} to the expected reference * and the current stamp is equal to the expected stamp. * *@paramexpectedReference the expected value of the reference *@paramnewReference the new value for the reference *@paramexpectedStamp the expected value of the stamp(上面提到的版本号) *@paramnewStamp the new value for the stamp *@return{@codetrue} if successful */publicbooleancompareAndSet(V expectedReference, V newReference,intexpectedStamp,intnewStamp){ Pair current = pair;returnexpectedReference == current.reference && expectedStamp == current.stamp && ((newReference == current.reference && newStamp == current.stamp) || casPair(current, Pair.of(newReference, newStamp))); }
6.AtomicLongArray
可以指定更新一个数组指定索引位置的值
/** * Atomically sets the element at position {@codei} to the given value * and returns the old value. * *@parami the index *@paramnewValue the new value *@returnthe previous value */publicfinallonggetAndSet(inti,longnewValue){returnunsafe.getAndSetLong(array, checkedByteOffset(i), newValue); }....../** * Atomically sets the element at position {@codei} to the given * updated value if the current value {@code==} the expected value. * *@parami the index *@paramexpect the expected value *@paramupdate the new value *@return{@codetrue} if successful. False return indicates that * the actual value was not equal to the expected value. */publicfinalbooleancompareAndSet(inti,longexpect,longupdate){returncompareAndSetRaw(checkedByteOffset(i), expect, update); }
7.AtomicBoolean(平时用的比较多)
compareAndSet方法也值得注意,可以达到同一时间只有一个线程执行这段代码
/** * Atomically sets the value to the given updated value * if the current value {@code==} the expected value. * *@paramexpect the expected value *@paramupdate the new value *@return{@codetrue} if successful. False return indicates that * the actual value was not equal to the expected value. */publicfinalbooleancompareAndSet(booleanexpect,booleanupdate){inte = expect ?1:0;intu = update ?1:0;returnunsafe.compareAndSwapInt(this, valueOffset, e, u); }
8.原子性-锁
- synchronized:依赖JVM (主要依赖JVM实现锁,因此在这个关键字作用对象的作用范围内,都是同一时刻只能有一个线程进行操作的)
- Lock:依赖特殊的CPU指令,代码实现,ReentrantLock
修饰的内容分类
- 修饰代码块:大括号括起来的代码,作用于调用的对象
- 修饰方法:整个方法,作用于调用的对象
- 修饰静态方法:整个静态方法,作用于所有对象
- 修饰类:括号括起来的部分,作用于所有对象
3)可见性
导致共享变量在线程间不可见的原因
1、线程的交叉执行
2、重排序结合线程交叉执行
3、共享变量更新后的值没有在工作内存与主内存间及时更新
可见性-synchronized
JMM关于synchronized的两条规定:
1、线程解锁前,必须把共享变量的最新值刷新到主内存
2、线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从
主内存中重新读取最新的值(注意:加锁与解锁是同一把锁)
更多理解:关于java多线程中synchronized关键字的理解
可见性-volatile
通过加入内存屏障和禁止重排序优化来实现
1、对volatile变量写操作时,会在写操作后加入一条store屏障指令,将本地内存中的
共享变量值刷新到主内存
2、对volatile变量读操作时,会在读操作前加入一条load屏障指令,从主内存读取

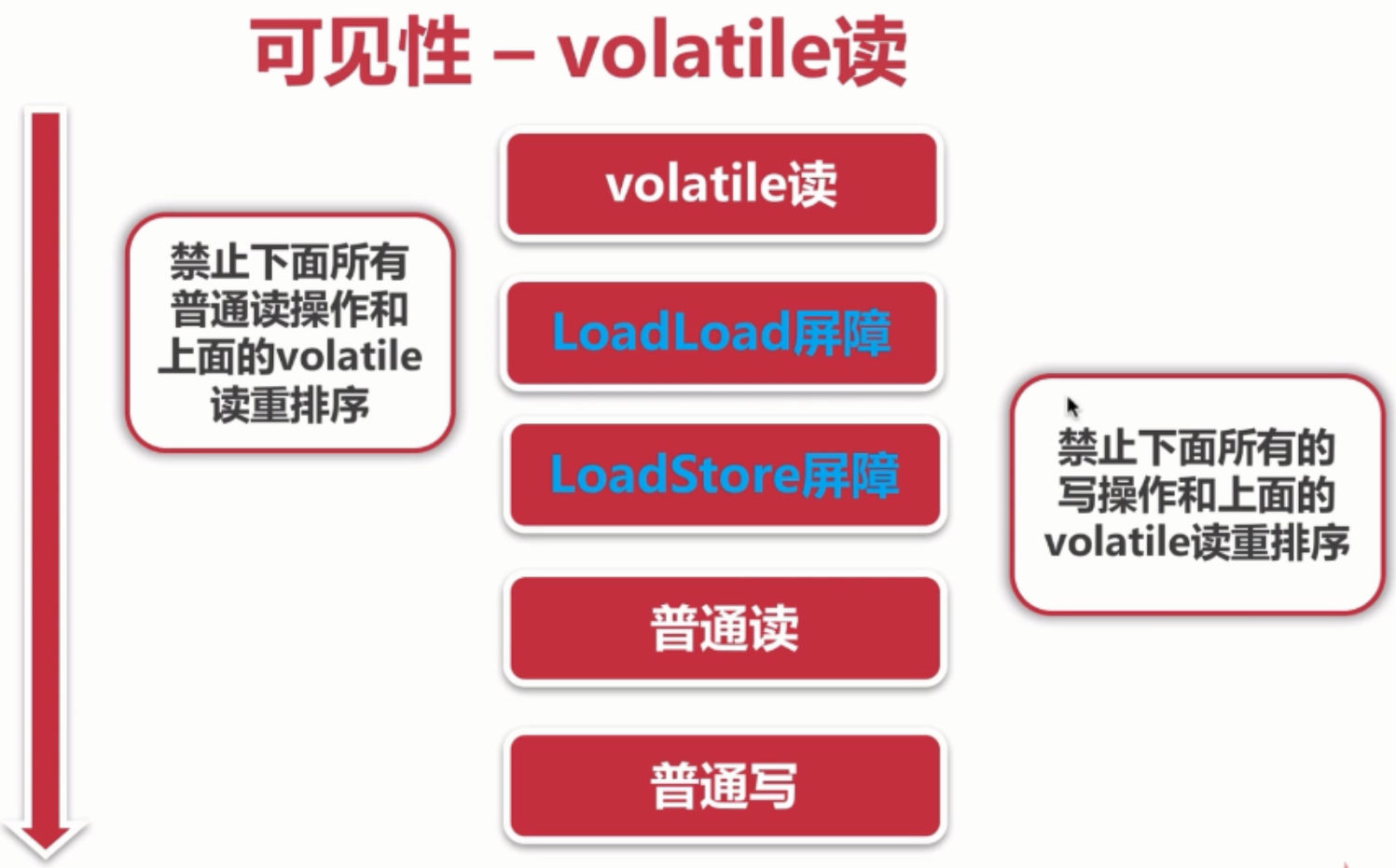

更多volatile知识:关于java多线程关键字volatile的理解
4)有序性
一个线程观察其他线程中的指令执行顺序,由于指令重排序的存在,该观察结果一般杂乱无序。
JMM允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
可以通过volatile、synchronized、lock保证有序性。
Happens-before原则
先天有序性,即不需要任何额外的代码控制即可保证有序性,java内存模型一个列出了八种Happens-before规则,如果两个操作的次序不能从这八种规则中推倒出来,则不能保证有序性。
程序次序规则:一个线程内,按照代码执行,书写在前面的操作先行发生于书写在后面的操作。
锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作
volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作
传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
线程启动原则:Thread对象的start()方法先行发生于此线程的每一个动作
线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()方法返回值手段检测到线程已经终止执行
对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
第一条规则要注意理解,这里只是程序的运行结果看起来像是顺序执行,虽然结果是一样的,jvm会对没有变量值依赖的操作进行重排序,这个规则只能保证单线程下执行的有序性,不能保证多线程下的有序性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号