


训练自己的yolo detect模型
yolo 官方地址
前提条件,我们已经安装好了,pytorch环境。yolo的官方并不是以yolo去命名的,官方是ultralytics,旨在做该领域的合集,yolo只是其中之一。
这里是用的macos m1 架构。
安装
这里采用的是pip安装,官方还有很多其他方式。
- 安装PyTorch环境
选择好自己的需求,会生成命令,执行就可以了

# 底部的命令,终端执行即可 pip3 install torch torchvision torchaudio
- 安装 ultralytics 包
# Install the ultralytics package from PyPI pip install ultralytics
使用
使用的2种方式 python & CLI, python 核心方法列举
我们可以用CLI( command line interface)或者是使用Python,这里主要讲使用python,更多请参考官方文档。
from ultralytics import YOLO # Create a new YOLO model from scratch model = YOLO('yolov8n.yaml') # Load a pretrained YOLO model (recommended for training) model = YOLO('yolov8n.pt') # Train the model using the 'coco128.yaml' dataset for 3 epochs results = model.train(data='coco128.yaml', epochs=3) # Evaluate the model's performance on the validation set results = model.val() # Perform object detection on an image using the model results = model('https://ultralytics.com/images/bus.jpg') # Export the model to ONNX format success = model.export(format='onnx')
以上是官方列举的几个核心接口、
这里主要讲如何训练我们自己的模型、
上一篇文章我们介绍了如何创建自己的yolo训练集,这里就需要用到了
首次创建训练任务
from ultralytics import YOLO # Load a model model = YOLO('yolov8n.yaml') # build a new model from YAML model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training) # model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights 这句跟上面2句功能一样 # Train the model,这里可以更换自己的训练集 results = model.train(data='coco128.yaml', epochs=100, imgsz=640) # data=这里是自己的训练集的路径 # results = model.train(data='Base-3C-Circle-Mark/Base-3C-Circle-Mark.yaml', epochs=1000, device='mps', imgsz=960)
基于已有的训练模型训练
# 可以直接这样创建模型,注意这样的话 circle_pre.pt是在项目根目录的 model = YOLO('circle_pre.pt') # device='mps' 利用macOS 特有的GPU 加速 results = model.train(data='Base-3C-Circle-Mark/Base-3C-Circle-Mark.yaml', epochs=1000, device='mps', imgsz=960)
MPS
MPS 是 Metal Performance Shaders(Metal 性能着色器)的缩写,是苹果公司提供的用于高性能图形和计算的框架。MPS 可以在 iOS 和 macOS 平台上利用 GPU 进行并行计算,加速图像处理、机器学习等任务。MPS 提供了一系列的预定义的图像处理和计算操作,包括卷积、池化、矩阵乘法等,这些操作都是在 GPU 上进行加速的,能够有效地利用硬件资源提高计算性能。
使用 MPS,开发者可以通过简单的接口调用,利用 GPU 的并行计算能力来加速应用程序中的各种图像处理和计算任务,从而提高应用程序的性能和响应速度。MPS 还能够与 Core ML 框架结合使用,为机器学习模型的推理提供加速支持。
恢复训练
model = YOLO('runs/detect/train4/weights/best.pt') results = model.train(resume=True)
验证
model = YOLO('runs/detect/train4/weights/best.pt') model.val()
预测(测试)
这里仅仅需要给到图片即可,不需要给标签,yolo可以将预测结果渲染并输出
from ultralytics import YOLO model = YOLO('runs/detect/train14/weights/best.pt') # ../datasets/Base-3C-Circle-Mark/images 这里是需要验证的图片的目录 model.predict('../datasets/Base-3C-Circle-Mark/images', save=True, line_width=1)
导出模型
这里主要介绍一下导出coreml,可直接用于ios端的,导出的模型是以 .mlpackage 后缀结尾的(yolov8n.mlpackage)
在ios中,xcode在使用 yolov8n.mlpackage模型的时候,xcode会自己生成模型对应的类,并且模型中是包含我们需要的所有信息的,如label, box、只是这个属于需要我们做逻辑展示、可以参考官方的demo
# 导出模型 model = YOLO('runs/detect/train/weights/last.pt') # nms default:False When exporting to CoreML, adds a Non-Maximum Suppression (NMS) layer to the model, useful for filtering overlapping detections. # int8 False Activates INT8 quantization, further reducing model size and increasing inference speed at the cost of precision. Useful for edge devices. success = model.export(format="coreml", int8=True, nms=True, imgsz=[640, 384])
TensorBoard
如何启动TensorBoard
前提需要我们安装了TensorBoard工具,好消息是 我们在安装 ultralytics 包(pip install ultralytics)的时候里面已经帮我们预安装了,当然你也可以参考pytorch官方去安装
当你在执行你的yolo训练的时候,通常控制台你是可以看到这样的提示:
TensorBoard: Start with 'tensorboard --logdir path_to_your_tensorboard_logs', view at http://localhost:6006/
按照提示启动 TensorBoard: tensorboard --logdir runs/detect/train
然后在 http://localhost:6006/ 查看即可、
如何解读
查看lr
学习率,这里是设置的默认优化器,训练时候的学习率曲线

查看metrics

metrics/mAP50(B)
"metrics/mAP50(B)" 通常是指在目标检测任务中使用的指标之一,它代表平均精度(mAP)在 IoU(Intersection over Union)阈值为 0.5 时的值。下面是对这个图表的解释:
-
mAP50(B) 的含义:
- mAP50(B) 表示在目标检测任务中,对于所有类别的平均精度(mAP),当 IoU 阈值设定为 0.5 时的值。
- IoU 是指预测的边界框(bounding box)与实际边界框之间的交集比上它们的并集,用于衡量预测框与真实框的重叠程度。
-
如何解读图表:
- 在 mAP50(B) 图表中,通常会显示不同类别的 mAP50(B) 值,以及整体的平均值。
- 每个类别的 mAP50(B) 值表示在预测中,模型在该类别上的检测精度。该值越高,表示模型对该类别的检测效果越好。
- 整体的平均值是所有类别 mAP50(B) 值的平均值,用于评估模型在整个数据集上的综合性能。
-
评估模型性能:
- mAP50(B) 是评估目标检测模型性能的重要指标之一,尤其是对于需要考虑检测框与真实框之间轻微重叠的任务。
- 通常情况下,希望 mAP50(B) 值越高越好,因为这表示模型对目标检测任务的准确性越高。
metrics/mAP50-95(B)
"metrics/mAP50-95(B)" 是目标检测任务中使用的另一个重要指标,代表在 IoU(Intersection over Union)阈值从 0.5 到 0.95 的范围内计算的平均精度(mAP)。以下是对这个图表的解释:
-
mAP50-95(B) 的含义:
- mAP50-95(B) 表示在目标检测任务中,对于所有类别的平均精度(mAP),当 IoU 阈值从 0.5 到 0.95 的范围内计算的值。
- IoU 是指预测的边界框(bounding box)与实际边界框之间的交集比上它们的并集,用于衡量预测框与真实框的重叠程度。
-
如何解读图表:
- 在 mAP50-95(B) 图表中,通常会显示不同类别的 mAP50-95(B) 值,以及整体的平均值。
- 每个类别的 mAP50-95(B) 值表示在预测中,模型在该类别上的检测精度,考虑了不同 IoU 阈值的情况。该值越高,表示模型对该类别的检测效果越好。
- 整体的平均值是所有类别 mAP50-95(B) 值的平均值,用于评估模型在整个数据集上的综合性能。
-
评估模型性能:
- mAP50-95(B) 是评估目标检测模型性能的重要指标之一,通过考虑多个 IoU 阈值,可以更全面地评估模型在不同检测精度要求下的表现。
- 与 mAP50(B) 相比,mAP50-95(B) 考虑了更广泛的 IoU 范围,更能反映模型在不同检测精度要求下的表现。
- metrics/precision(B)
"metrics/precision(B)" 表示在目标检测任务中使用的精度(precision)指标,其中的 "(B)" 可能表示在多个 IoU(Intersection over Union)阈值下计算的精度。以下是对这个图表的解释:
metrics/recall(B)
"metrics/recall(B)" 表示在目标检测任务中使用的召回率(recall)指标,以下是对这个图表的解释:
-
Recall(B) 的含义:
- Recall(B) 表示在目标检测任务中,对于所有类别的平均召回率(recall),可能在多个 IoU 阈值下计算的值。
-
如何解读图表:
- 在 Recall(B) 图表中,通常会显示不同类别的 recall(B) 值,以及整体的平均值。
- 每个类别的 recall(B) 值表示在真实类别中,模型成功检测到的比例。该值越高,表示模型对该类别的检测效果越好。
- 整体的平均值是所有类别 recall(B) 值的平均值,用于评估模型在整个数据集上的召回率表现。
-
评估模型性能:
- Recall(B) 是评估目标检测模型性能的重要指标之一,用于衡量模型在检测任务中的召回率。
- 通过观察和分析 Recall(B) 图表,可以评估模型在不同 IoU 阈值下的检测召回率,以及不同类别的表现情况。
召回率(Recall)是评估分类或检测模型在识别某一类别时的性能指标之一,它衡量的是模型在所有真实正例中成功识别出的比例。召回率的计算公式如下:
Recall= TP/(TP+FN)
其中:
- TP(True Positives)是指模型成功检测到的真实正例数量。
- FN(False Negatives)是指模型未能检测到的真实正例数量。
召回率的值范围在 0 到 1 之间,越接近 1 表示模型对该类别的检测效果越好,因为它意味着模型成功找到了更多真实正例,未漏掉太多真实目标。
换句话说,召回率高表示模型在检测目标时更为全面,尽可能地捕获了大部分真实目标,这是目标检测任务中的一个重要指标。然而,高召回率可能伴随着低精度,即模型可能会将一些负样本误判为正样本,这就需要在召回率和精确率之间进行权衡。
备注:以上均源自于chatgpt的回答,可以作为参考,对于“(B)”的解释酌情参考。
查看 train
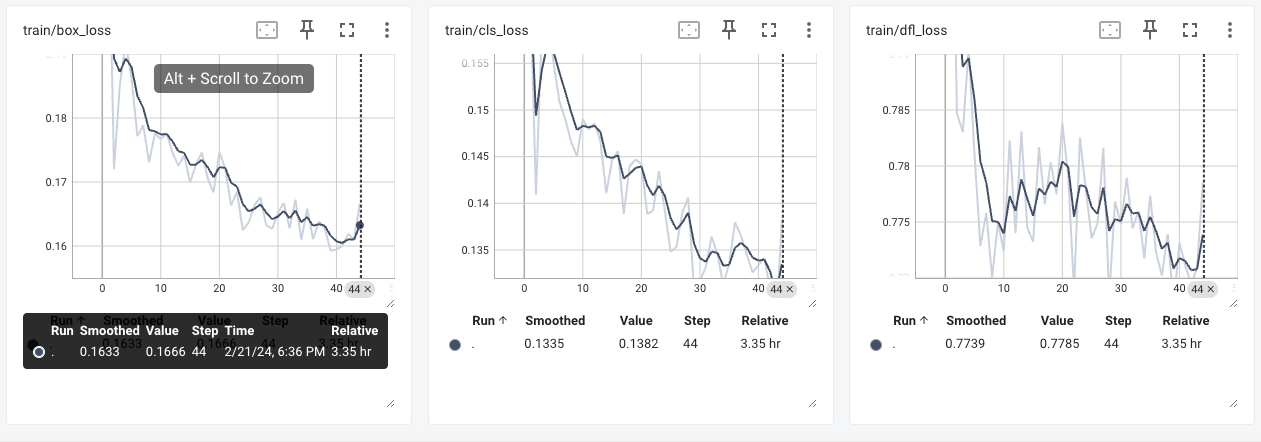
train/box_loss
"train/box_loss" 图表通常用于监视目标检测模型训练过程中的边界框损失(box loss)。以下是对这个图表的解释:
-
Box Loss 的含义:
- Box Loss 表示目标检测模型在训练过程中计算的边界框损失,它衡量了模型预测的边界框与真实边界框之间的差异程度。
- 边界框损失通常由模型的损失函数计算,用于优化模型的参数以使预测的边界框更加接近真实边界框。
-
如何解读图表:
- 在 "train/box_loss" 图表中,通常会显示随着训练迭代次数的增加,边界框损失的变化情况。
- 每个点或线代表一个训练批次或训练周期的边界框损失值。通过观察这些值的变化,可以了解模型在训练过程中边界框损失的趋势。
-
评估模型训练:
- 边界框损失是监视目标检测模型训练过程中的一个重要指标。通常情况下,希望边界框损失随着训练的进行逐渐减小,表示模型对边界框的预测越来越准确。
- 通过观察 "train/box_loss" 图表,可以评估模型在训练过程中边界框损失的变化情况,帮助调整模型的超参数或监测训练是否进行顺利。
train/cls_loss
"train/cls_loss" 图表通常用于监视目标检测模型训练过程中的分类损失(class loss)。以下是对这个图表的解释:
-
Cls Loss 的含义:
- Cls Loss 表示目标检测模型在训练过程中计算的分类损失,它衡量了模型预测的类别与真实类别之间的差异程度。
- 分类损失通常由模型的损失函数计算,用于优化模型的参数以使预测的类别更接近真实类别。
-
如何解读图表:
- 在 "train/cls_loss" 图表中,通常会显示随着训练迭代次数的增加,分类损失的变化情况。
- 每个点或线代表一个训练批次或训练周期的分类损失值。通过观察这些值的变化,可以了解模型在训练过程中分类损失的趋势。
-
评估模型训练:
- 分类损失是监视目标检测模型训练过程中的一个重要指标。通常情况下,希望分类损失随着训练的进行逐渐减小,表示模型对类别的预测越来越准确。
- 通过观察 "train/cls_loss" 图表,可以评估模型在训练过程中分类损失的变化情况,帮助调整模型的超参数或监测训练是否进行顺利。
train/dfl_loss
"train/dfl_loss" 图表通常用于监视目标检测模型训练过程中的关键点检测损失(keypoint detection loss)。以下是对这个图表的解释:
-
DFL Loss 的含义:
- DFL Loss 表示目标检测模型在训练过程中计算的关键点检测损失,它衡量了模型预测的关键点与真实关键点之间的差异程度。
- 关键点检测损失通常由模型的损失函数计算,用于优化模型的参数以使预测的关键点更接近真实关键点。
-
如何解读图表:
- 在 "train/dfl_loss" 图表中,通常会显示随着训练迭代次数的增加,关键点检测损失的变化情况。
- 每个点或线代表一个训练批次或训练周期的关键点检测损失值。通过观察这些值的变化,可以了解模型在训练过程中关键点检测损失的趋势。
-
评估模型训练:
- 关键点检测损失是监视目标检测模型训练过程中的一个重要指标。通常情况下,希望关键点检测损失随着训练的进行逐渐减小,表示模型对关键点的预测越来越准确。
- 通过观察 "train/dfl_loss" 图表,可以评估模型在训练过程中关键点检测损失的变化情况,帮助调整模型的超参数或监测训练是否进行顺利。
总的来说,"train/dfl_loss" 图表可以帮助您监视目标检测模型的训练过程中关键点检测损失的变化,以便评估模型的训练效果并做出必要的调整。
备注:以上均源自于chatgpt的回答,可以作为参考
注意事项
当我们训练出来一个效果还不错的模型的时候,可以进行当前节点的保存,避免后续因为意外导致模型被教育成了不好效果,方便追溯。
本文来自博客园,作者:shafujiu,转载请注明原文链接:https://www.cnblogs.com/shafujiu/p/18025452


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」