


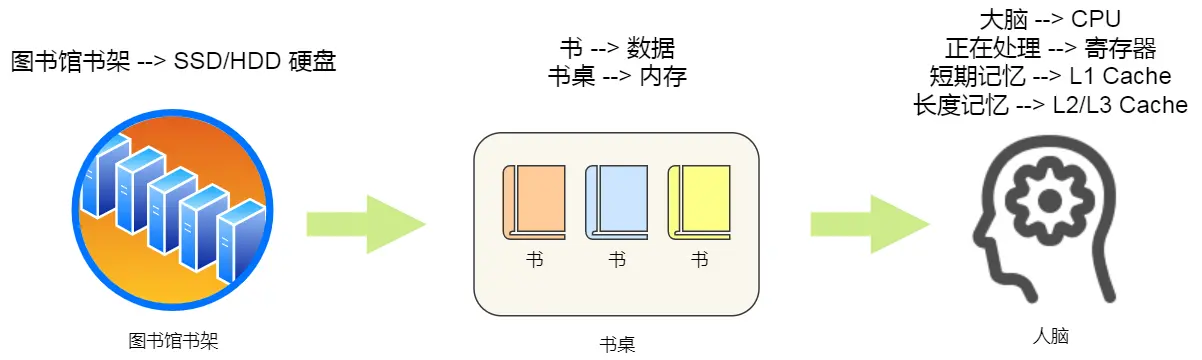
图解系统
目录
回顾
-
CPU 是如何执行程序的?
-
图灵机:定义了可计算模型
-
遵循了图灵机的设计的冯诺依曼模型
-
最重要的是定义计算机基本结构为 5 个部分,分别是运算器、控制器、存储器、输入设备、输出设备,这 5 个部分也被称为冯诺依曼模型。
-
a = 1 + 1执行过程
-
-
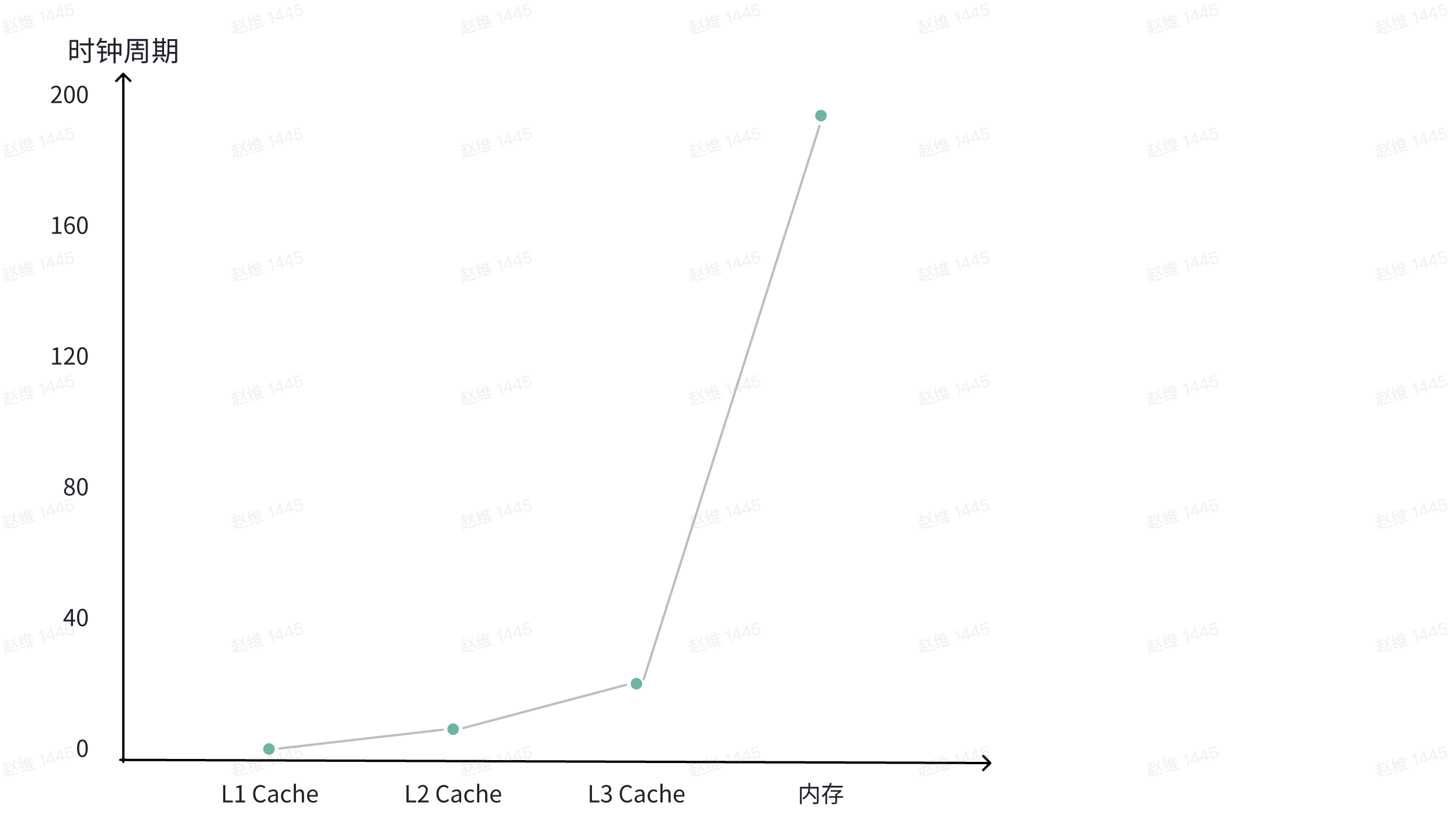
磁盘比内存慢几万倍?
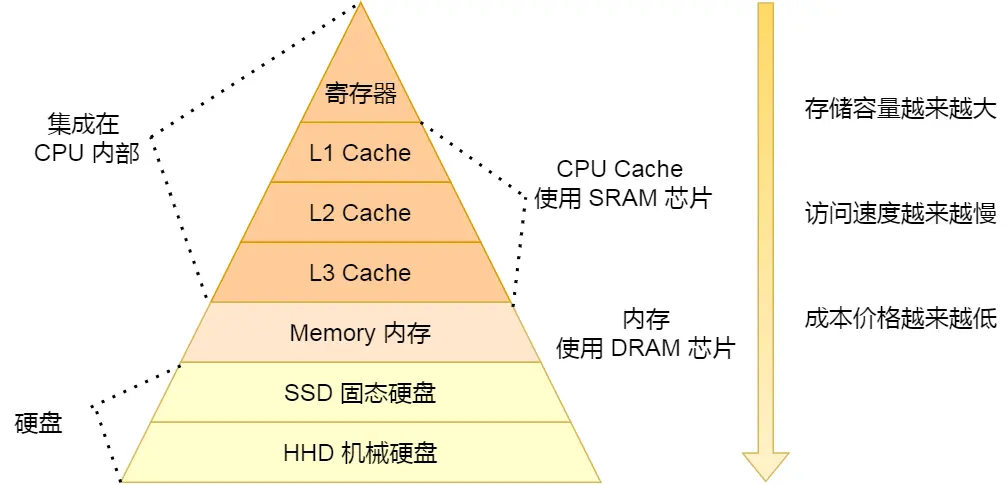
如何写出让CPU 跑得更快的代码?

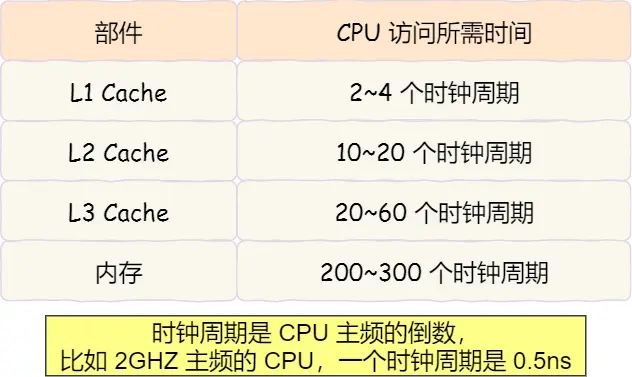
CPU Cache有多快
- 查看MAC CPU Cache
// L1 数据缓存 64kb hw.l1dcachesize: 65536 // L1 指令缓存 128kb hw.l1icachesize: 131072 // L2 缓存 4096kb = 4m hw.l2cachesize: 4194304 // Cache Line(缓存块)64字节 hw.cachelinesize: 64
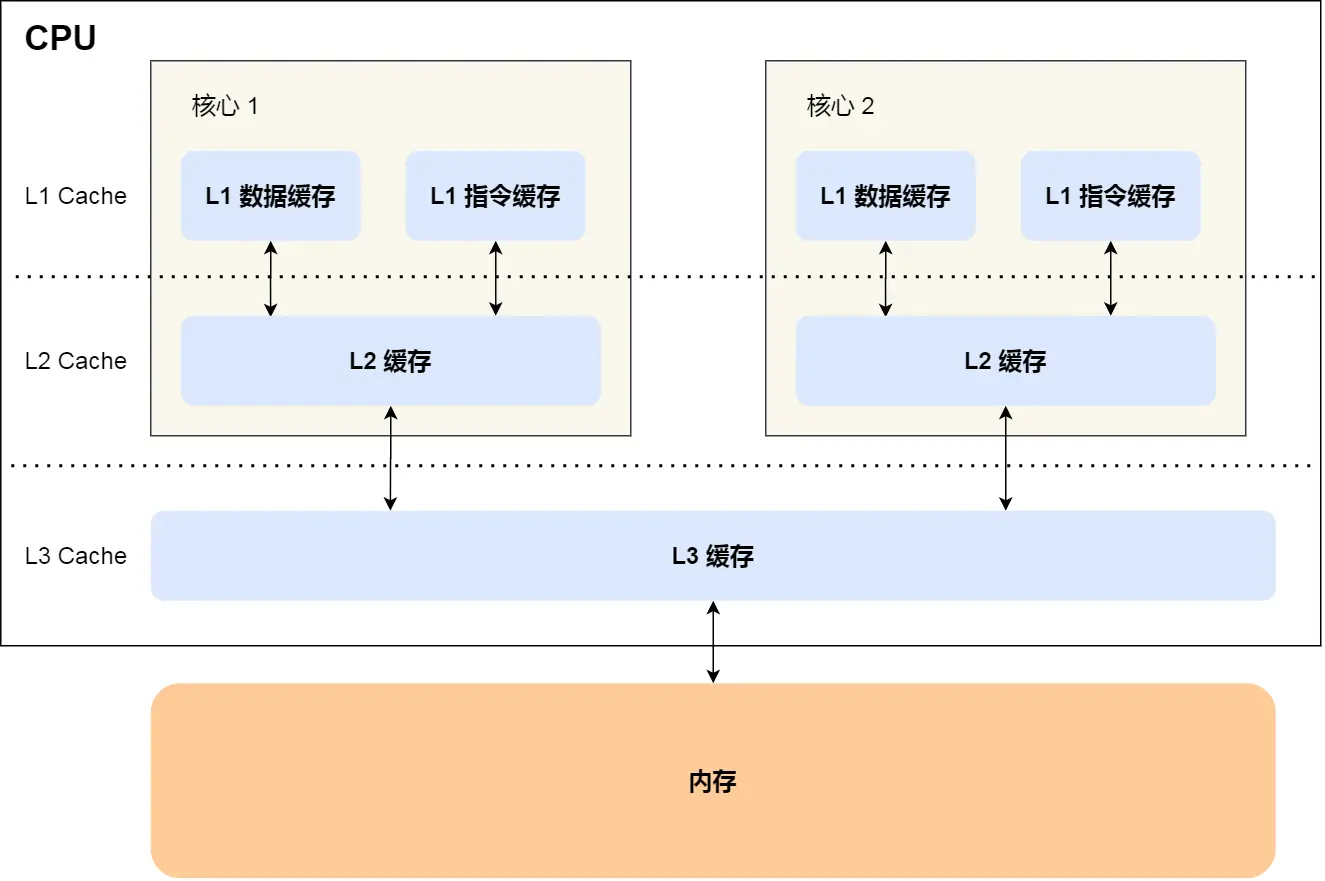
- CPU Cache 结构(Linux)
- 访问速度
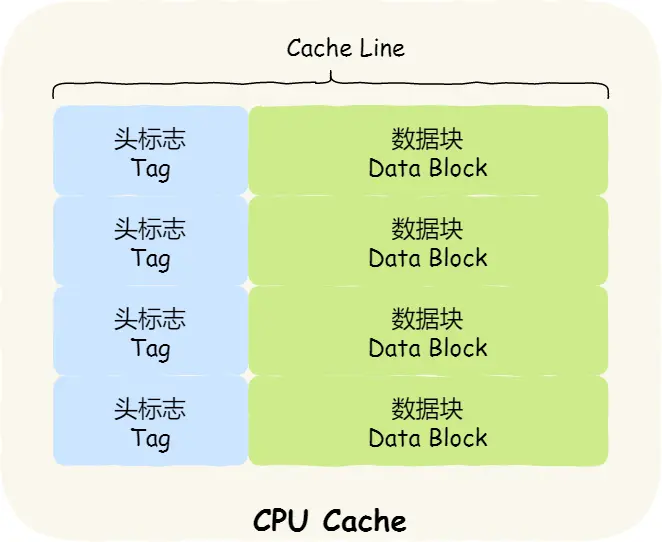
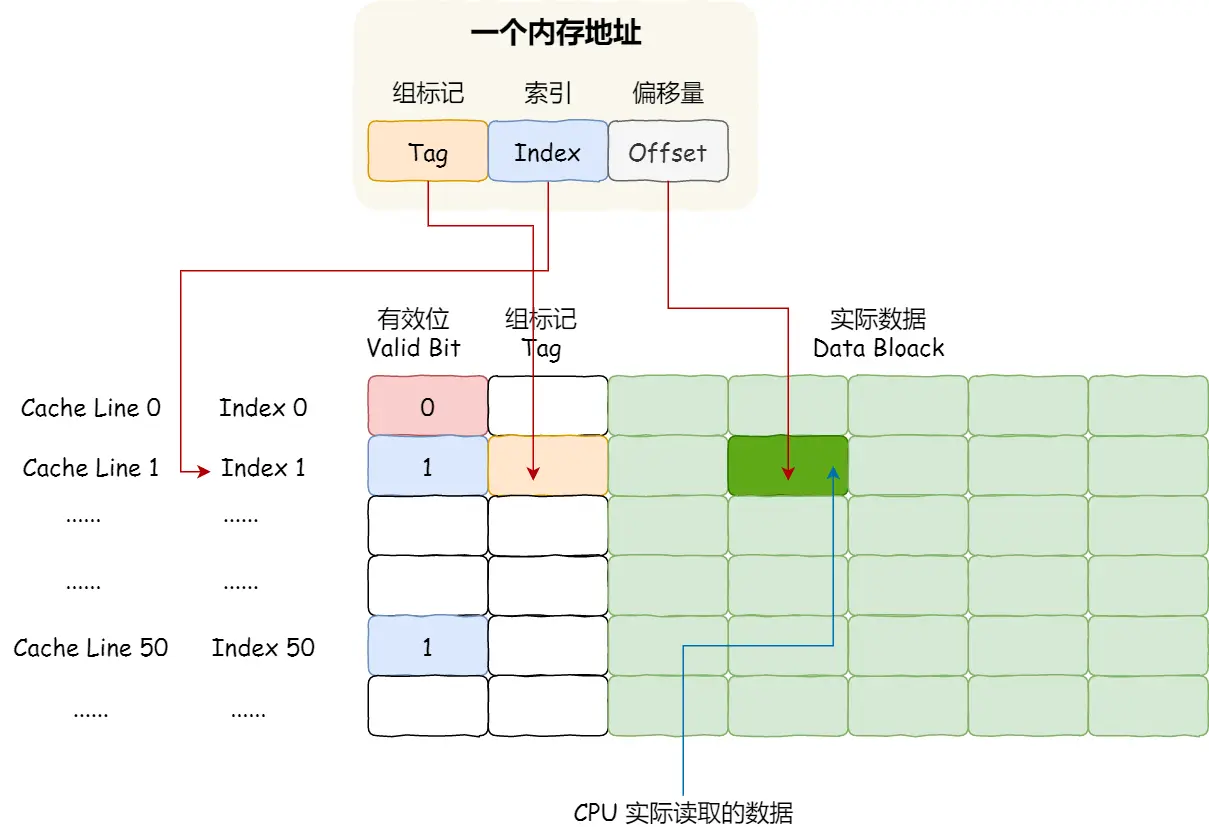
CPU Cache的数据结构和读取过程?
取模运算
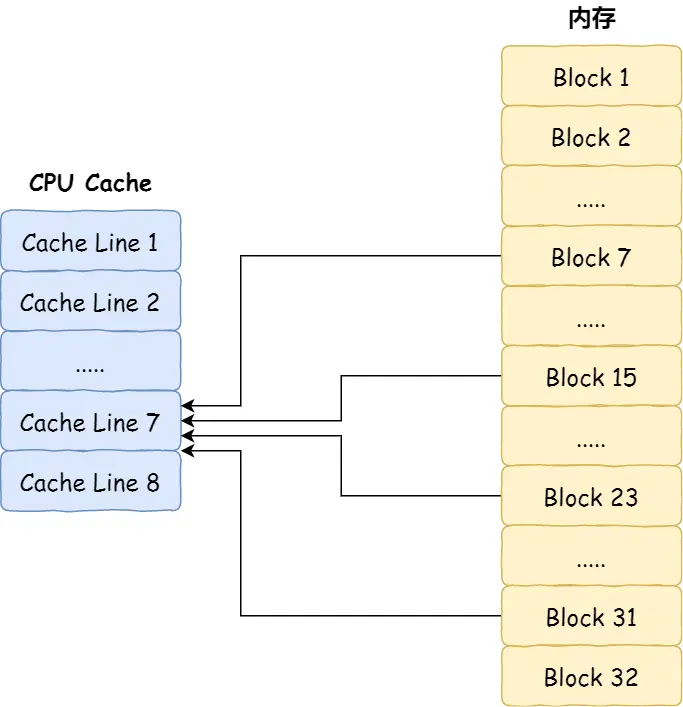
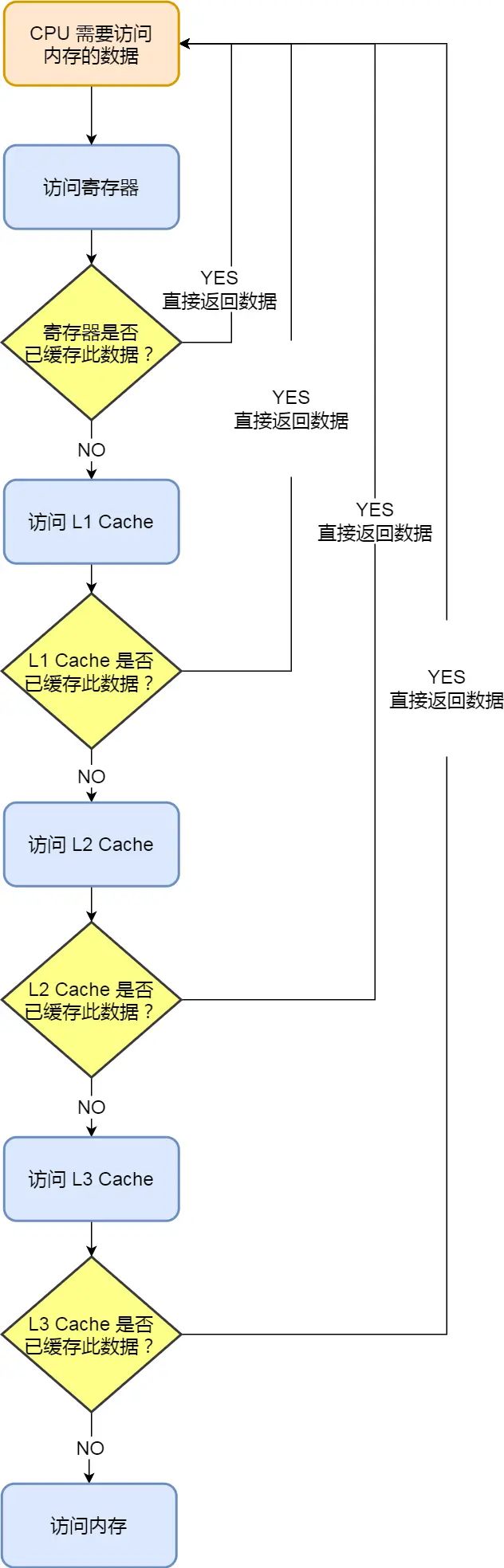
如果内存中的数据已经在 CPU Cache 中了,那 CPU 访问一个内存地址的时候,会经历这 4 个步骤:
- 根据内存地址中索引信息,计算在 CPU Cache 中的索引,也就是找出对应的 CPU Cache Line 的地址;
- 找到对应 CPU Cache Line 后,判断 CPU Cache Line 中的有效位,确认 CPU Cache Line 中数据是否是有效的,如果是无效的,CPU 就会直接访问内存,并重新加载数据,如果数据有效,则往下执行;
- 对比内存地址中组标记和 CPU Cache Line 中的组标记,确认 CPU Cache Line 中的数据是我们要访问的内存数据,如果不是的话,CPU 就会直接访问内存,并重新加载数据,如果是的话,则往下执行;
- 根据内存地址中偏移量信息,从 CPU Cache Line 的数据块中,读取对应的字。
如何写出让CPU跑得更快的代码?
提升数据缓存的命中率
提升指令缓存的命中率
多核CPU的缓存命中率
还有什么办法写出让cpu跑的更快的代码?
命令集
// 查看所有信息 sysctl machdep.cpu sysctl hw.cachelinesize sysctl hw.cachesize // hw.cachesize: 3707699200 65536 4194304 0 0 0 0 0 0 0 // L1数据 数据缓存 sysctl hw.l1dcachesize // L1指令缓存 sysctl hw.l1icachesize // L2 缓存 d i 不能指定,猜测L2缓存没有区分;mac m1 没有L3 sysctl hw.l2cachesize // // 硬件基本信息 system_profiler SPHardwareDataType
参考资料
本文来自博客园,作者:shafujiu,转载请注明原文链接:https://www.cnblogs.com/shafujiu/p/17726976.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现