Python——LOL官方商城皮肤信息爬取
# -*- coding utf-8 -*- import urllib import urllib.request import json import time import xlsxwriter from asyncio.tasks import sleep import re # 根据第一页数据创建信息表头 header = [] url = "http://apps.game.qq.com/daoju/v3/api/hx/goods/api/list/v54/GoodsListApp.php?view=biz_cate&page=1&pageSize=8&orderby=dtShowBegin&ordertype=desc&cate=17&appSource=pc&appSourceDetail=pc_lol_revison&channel=1001&storagetype=6501&plat=0&output_format=jsonp&biz=lol" data = json.loads(urllib.request.urlopen(url).read().decode("gbk").replace("var ogoods_list_api = ","").replace("\n","")) goods_info = data["data"]["goods"][0]["valiDate"][0] for i in range(len(goods_info)): header.append(''.join((re.findall("\w",str(str(goods_info).split(",")[i]).split(":")[0]))).strip()) # 创建工作簿,写表头 workbook = xlsxwriter.Workbook("E:/lol_sales.xlsx") sheet = workbook.add_worksheet("result") for i in range(len(header)): sheet.write(0,i,header[i]) # 获取数据 row_index = 1 for page_index in range(1,61): url = "http://apps.game.qq.com/daoju/v3/api/hx/goods/api/list/v54/GoodsListApp.php?view=biz_cate&page=" + str(page_index) + "&pageSize=8&orderby=dtShowBegin&ordertype=desc&cate=17&appSource=pc&appSourceDetail=pc_lol_revison&channel=1001&storagetype=6501&plat=0&output_format=jsonp&biz=lol" data = json.loads(urllib.request.urlopen(url).read().decode("gbk").replace("var ogoods_list_api = ","").replace("\n","")) for goods_index in range(6): try: for col_index in range(len(header)): if header[col_index] == "award": pass else: sheet.write(row_index,col_index,data["data"]["goods"][goods_index]["valiDate"][0][header[col_index]]) row_index += 1 except: pass print("page" + str(page_index)) workbook.close() print("finish")
获取的数据内容如下:
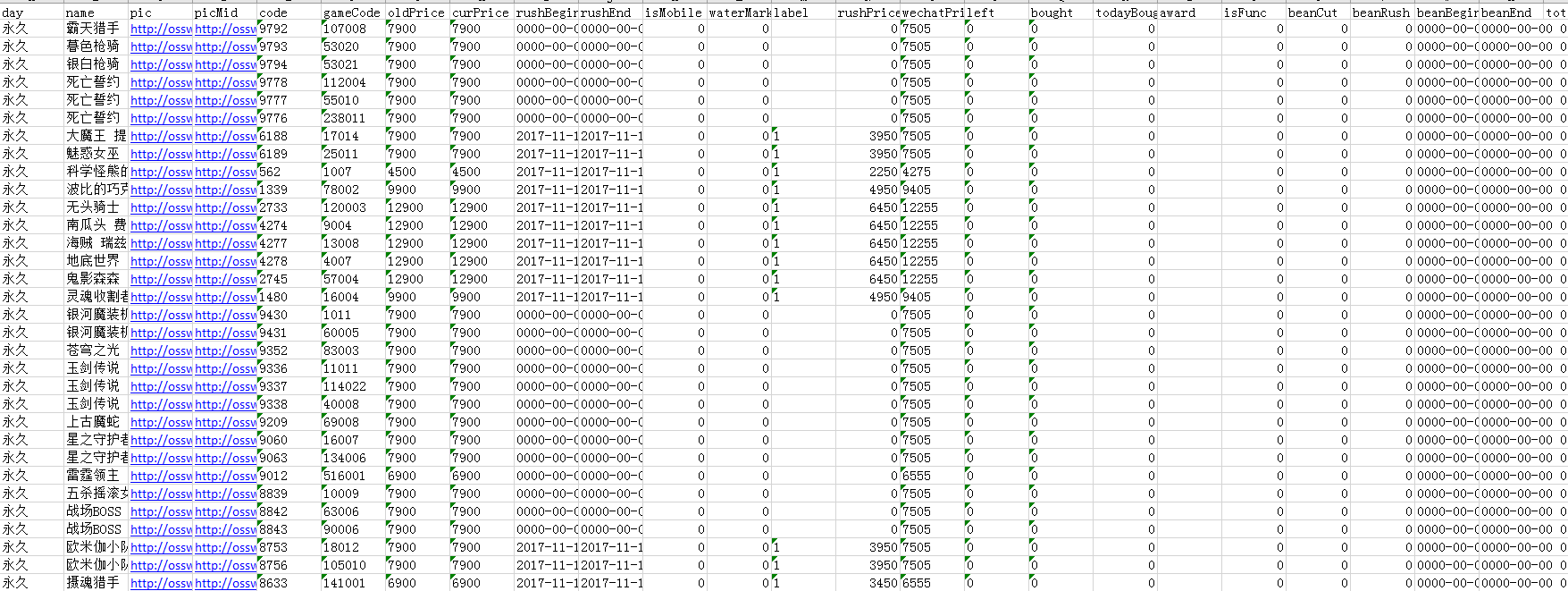
总结:
1.表头的获取方式。
不要再自己编写表头啦,一是太费事,二是不灵活。
通过创建空的列表,读取示范页面(如第一页)的信息表头,使用.append即可创建所需表头。
2.多数网站的数据格式都是json,但是其返回的还附带了json数据的表头,注意删除掉。
如.replace("var ogoods_list_api = ","").replace("\n","")。这样才是符合格式要求的json(可以用这个网站测试json格式是否标准:Be JSON),否则无法用json.loads()读取,因为会被识别成字符串。
3.json.loads(s),中读取的是字符串数据。
4.即使读取出来的数据编码是unicode,但是写入excel的时候就被解码了。(使用了多种方式仍无法对数据解码,故打算提取后单独解码,后发现写入excel的是解码后的数据。意外发现。)
5.关于表头的提取:
- 首先使用两次split,分别是“,”和“:”将json的key提取出来。
- 接下来使用正则表达式提取{'ret'中的ret。在这里使用了这样的方法:用\w提取英文字符,再用''.join()合并起来

 浙公网安备 33010602011771号
浙公网安备 33010602011771号