Python——正则表达式初步应用(一)
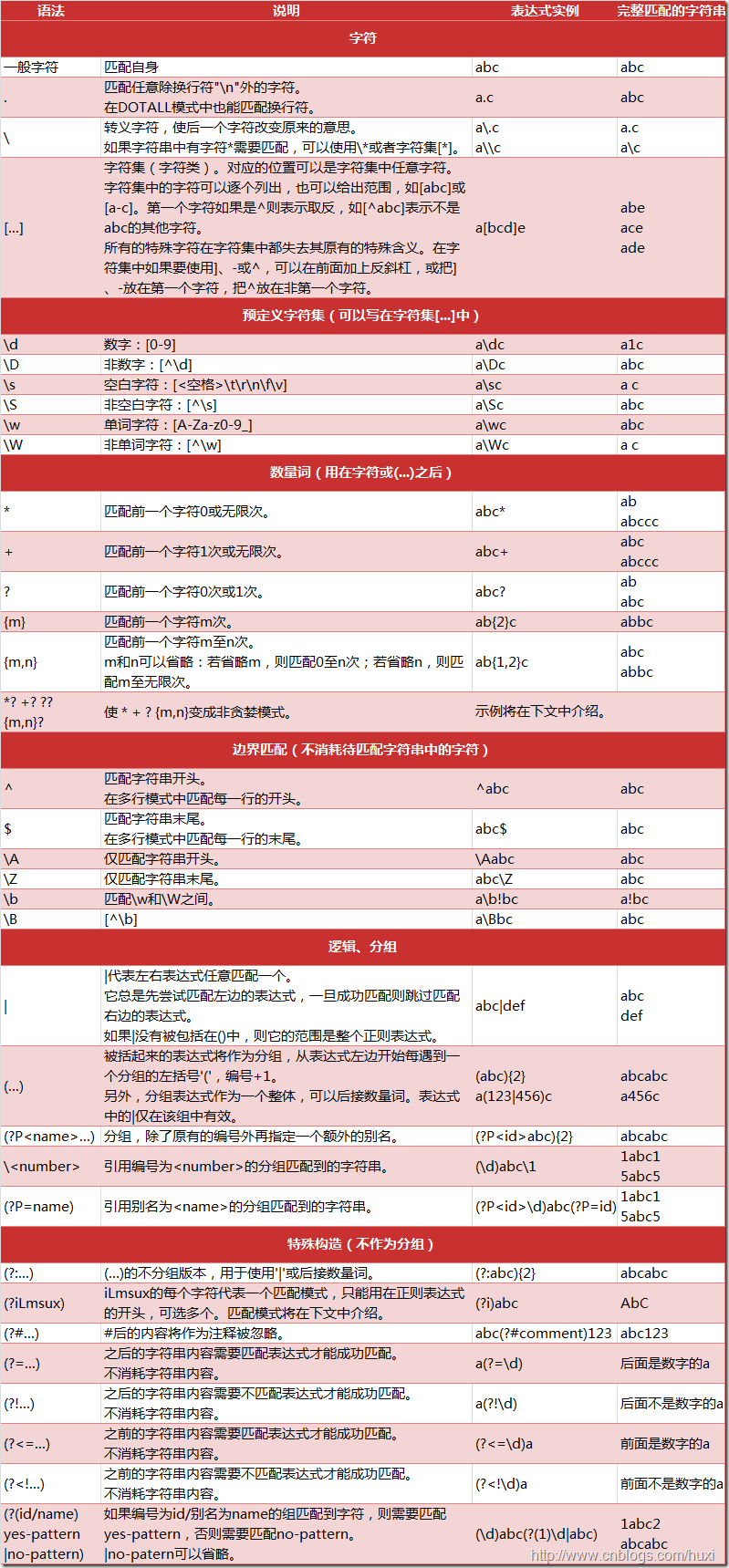
1、先附上转载(www.cnblogs.com/huxi)的一张图,有重要的参考价值,其含义大家请通过阅读来理解。
2、附上初步学习Python时编写的一个爬糗事百科段子的代码。
1 # -*- coding: utf-8 -*- 2 import urllib 3 import urllib.request 4 import re 5 import os 6 from os import makedirs 7 8 if __name__ == '__main__': 9 print('Start getting data...') 10 for i in range(1,13): 11 url = 'https://www.qiushibaike.com/text/page/'+str(i)+'/' 12 #url = 'https://www.qiushibaike.com/text/page/1/' 13 user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36 QIHU 360SE' 14 headers = {'User-Agent':user_agent} 15 request = urllib.request.Request(url = url,headers = headers) 16 response = urllib.request.urlopen(request) 17 #print(response) 18 content = response.read() 19 content = content.decode('utf8') 20 #print(content) last step proves to be necessary 21
'''这里是本片内容表述的重点''' 22 patternArticleNum =re.compile('(?<=<a href="/article/)[1-9][0-9]{7,}(?=" target=")',re.S) 23 patternArticle =re.compile('<div class="content">\s<span>(.*?)\s</span>',re.S) 24 #print(re.findall(pattern,content)) 25 itemsArticleNum = re.findall(patternArticleNum,content) 26 lenItemsArticleNum =len(itemsArticleNum) 27 #print(lenItemsArticleNum) 28 itemsArticle = re.findall(patternArticle,content) 29 #itemsArticle = itemsArticle.encode('utf8') 30 #lenItemsArticle = len(itemsArticle) 31 #print(lenItemsArticle) 32 #items = re.split(pattern,content) 33 #print(items) type(item)=tuple 34 #print(itemsArticleNum[0]) 35 print(itemsArticle) 36 path = 'qiubai' 37 if not os.path.exists(path): 38 os.makedirs(path) 39 while lenItemsArticleNum > -1: 40 lenItemsArticleNum = lenItemsArticleNum - 1 41 file_path = path + '/' + itemsArticleNum[lenItemsArticleNum]+ '.txt' 42 f = open(file_path,'w') 43 itemsArticle[lenItemsArticleNum] = itemsArticle[lenItemsArticleNum].replace('\n','').replace('<br/>','').replace('\u261e','') .replace('\u261c','').replace('\u0ca5','').replace('\ufffc','').replace('\u26bd','').replace('\uff78','').replace('\uff9e','').replace('\uff6f','') 44 #itemsArticle[lenItemsArticleNum] = str(str(itemsArticle[lenItemsArticleNum]).encode('gb2312') 45 f.write(itemsArticle[lenItemsArticleNum]) 46 f.close() 47 #file_path = path + '/' + item[0]+ '.txt' 48 #for itemArticle in itemsArticle: 49 # print(itemsArticle) 50 print('Data acquireing compnished...') 51
3、查看网页源代码,发现我们所需要的内容具备如下的结构:
<a href="/article/119488591" target="_blank" class="contentHerf" onclick="_hmt.push(['_trackEvent','web-list-content','chick'])"> <div class="content"> <span> 今天看见的新闻:古有凿壁偷光,今有男子凿壁偷窥。杭州闸弄口派出所接到一名年轻姑娘报警,称隔壁男子在墙上挖了一个洞偷窥她。据民警介绍,男子自己交代,他是看到姑娘后起了歹念,洞是用手抠出来的…… </span> </div>
标黄的使我们关注的两部分内容,一是文章编号,提取后名为文本文件名称,二是段子内容,为文本文件内容。
4、如何提取文章编号:
patternArticleNum =re.compile('(?<=<a href="/article/)[1-9][0-9]{7,}(?=" target=")',re.S)
(?<=<a href="/article/):筛选前缀包含:<a href="/article的文本
[1-9][0-9]{7,} 筛选第一位是1-9,第二位是0-9,的,九位数及以上数字。{7,}表示匹配前一个字符7次及以上。
(?=" target=") 筛选后缀包含" target="的文本内容。
5、如何提取段子文本
<div class="content">\s<span>(.*?)\s</span>
<div class="content">\s<span> 筛选前缀包含<div class="content">\s<span>的文本,\s代表空白字符。
\s</span> 筛选后缀包含\s</span>的文本,
(.*?) 代表两者之间的所有字符,要用()括起来。
6、提取的公式
patternArticleNum =re.compile('(?<=<a href="/article/)[1-9][0-9]{7,}(?=" target=")',re.S) itemsArticleNum = re.findall(patternArticleNum,content)
patternArticle =re.compile('<div class="content">\s<span>(.*?)\s</span>',re.S) itemsArticle = re.findall(patternArticle,content)
需要调用re库,使用compile和正则表达式生成所需的pattern,利用re.findall在content内容里面匹配并读取出来。
备注1:content的获得:
(1)、根据Headers和User Agenturllib.request.Request()设置一个request。
(2)、用urllib.request.urlopen()根据这个request生成一个response。
(3)、最后用response.read()读取出来。
备注2:Python3.6中取消了urllib2,取而代之是自带的urllib.request。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号