中文词频
下载一长篇中文文章。
从文件读取待分析文本。
news = open('gzccnews.txt','r',encoding = 'utf-8')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20
import jieba
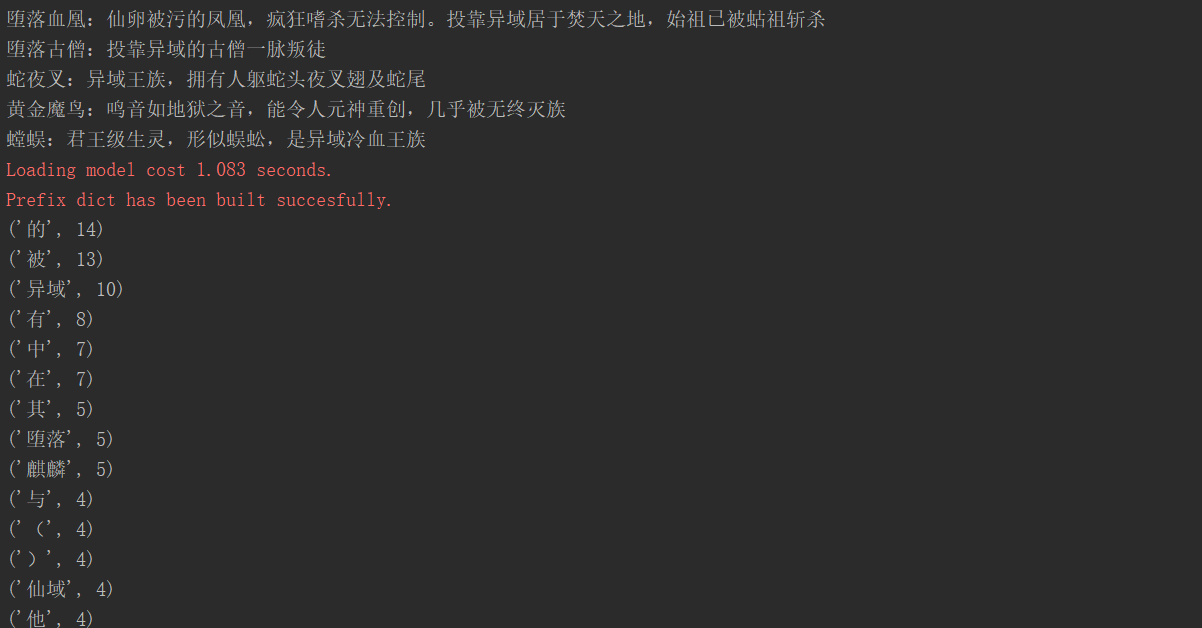
f=open('C:/Users/user/Desktop/122.txt','r',encoding='gbk')
s=f.read()
f.close()
print(s)
s1=list(jieba.lcut(s))
miss={',','。',' ',':','“','”','','!','、','?',';','\n'}
s2={}
for b in s1:
s2[b]=s2.get(b,0)+1
for a in miss:
if a in s2:
del s2[a]
s3=sorted(s2.items(),key=lambda x:x[1],reverse=True)
for c in range(20):
print(s3[c])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号