

MySQL全总结一-基础知识和DQL语言 2
文章目录
一,基础知识
1.1, 数据库的特点: ✔
- 将数据放到表中,表再放到库中;
- 一个数据库可以有多张表,每个表都有一个名字用于标识自己.
表名具有唯一性; - 表具有一些特性,这些特性定义了数据在表中如何存储;
- 表由列组成,我们也称为
字段.所有表都是由一个或多个列组成的. - 表中的数据是按行存储的.
数据库管理软件(DBMS)的种类:
- 基于共享文件系统的DBMS(Access)
- 基于C-S(客户端-服务器)的DBMS(Mysql, SqlServer,Oracle)
1.2, 数据库的好处 ✔
持久化数据到本地- 可以实现
结构化查询,方便管理
1.3, MySQL服务的启动和停止 ✔
方式一:计算机——右击管理——服务
方式二:通过管理员身份运行
net start mysql(启动服务)
net stop mysql(停止服务)
1.4, MySQL服务的登录和退出 ✔
方式一:通过mysql自带的客户端,只限于root用户
方式二:通过windows自带的客户端(管理员模式)
- 登录:
mysql 【-h 主机名 -P 端口号 】-u 用户名 -p 密码 - 退出:
exit或ctrl+c
示例:
mysql [-h localhost -P 3306] -u root -p(本机可省略可选操作)
1.5, Mysql的最基本操作 ✔
#1.查看当前所有的数据库
SHOW databases;
#2. 打开指定的库
USE 数据库名;
#3. 查看当前库的所有表
SHOW TABLES;
#4. 查看其它库的列表
SHOW TABLES FROM 数据库名;
#6.查看表结构(上下两条命令作用完全相同)
DESC 表名;
SHOW columns FROM 表名;
#7.查看服务器的版本
方式一:登录到mysql服务端
SELECT version();
方式二:没有登录到mysql服务端
mysql --version
或
mysql --V


1.6, Mysql语法规范 ✔
不区分大小写,但是
最好关键字全大写,表名,列名全小写;
每条命令最好用分号结尾;
每条命令根据需要,可进行 换行或缩进;
注释:单行注释: #注释文字
单行注释: – 注释文件
多行注释: /* 注释文字*/
1.7, SQL的语言分类 ✔
DQL(Data Query Language):数据查询语言
select
DML(Data Manipulate Language):数据操作语言
insert 、update、delete
DDL(Data Define Languge):数据定义语言
create、drop、alter
TCL(Transaction Control Language):事务控制语言
commit、rollback
二, Mysql命令之DQL语言:
DQL: Data Query Language(数据查询语言)
2.1 基础查询 ✔
2.1.1 基本格式: ✔
SELECT
要查询的字段|表达式|常量值|函数
[DISTINCT] 去重
FROM
表
[LIMIT] 限制查询结果
select查询结果是一个虚拟表;
2.1.2 具体命令:
#9. 查看表的具体信息
SELECT * FROM 表名;
SELECT 字段1, 字段2 FROM 表名;
#10.(DISTINCT)对列名A中的数据进行去重后查询
SELECT DISTINCT 列名A FROM 表名;
#11.(LIMIT)限制输出结果的个数
# 注意:select 检索出来的第一行的行号是0!!!!!!
SELECT * FROM 表名 LIMIT num;
SELECT * FROM 表名 LIMIT a,b; #限制输出的结果为包括第(a+1)行在内的下面b行;
#上面第二行语句的替代用法.
SELECT * FROM 表名 LIMIT b OFFSET a; #限制输出的结果为第a+1行的下面b行;
#12. 给列名起别名(使用 AS 别名, 或者 空格 别名)
SELECT 字段1 AS 别名 FROM 表名;
LIMIT 输出查询从索引0开始, a=5在表中实际为第六行.
注意: 如果没有明确排序查询结果,则返回数据的顺序没有任何意义,其查询结果有可能是添加到表中的顺序,也有可能不是,只要返回相同数目的行,就是正常的奥;
2.2 条件查询(WHERE) ✔
2.2.1 基本格式 ✔
SELECT
要查询的字段|表达式|常量值|函数
FROM
表
WHERE
筛选条件
2.2.2 适用于WHERE的操作符 ✔
| 操作符 | 含义 |
|---|---|
| > | 大于 |
| < | 小于 |
| <= | 小于等于 |
| >= | 大于等于 |
| <> 或 != | 不等于 |
| <=> | 安全等于 |
| AND | 组合条件 |
| BETWEEN…AND… | 检查范围值 |
| NOT | 取反 |
| IS NULL | 判空 |
| OR | 任一条件 |
| IN | 指定条件范围,跟IN()中字符相吻合的可以匹配 |
| LIKE | 模糊匹配 |
Mysql中的NOT:Mysql 只能使用NOT对BETWEEN,IN和 EXSITS取反,这与其他DBMS允许NOT对各种条件取反有很大差别.
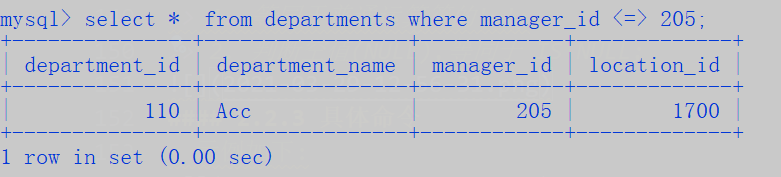
安全等于 <=>:
- 普通运算时,等同于’=’;
- 判断空值(NULL)时,等同于 IS NULL;
-
is null 和 <=>的区别:

-
安全等于, IS NULL的示例:


2.2.3 条件查询的使用 ✔
- 示例如下:
-
> 运算符

-
BETWEEN … AND …运算符

BETWEEN … AND …等价于 >= && <=

- IN()操作符, 指定条件范围,
范围中的每个字符串都可以匹配,()中是单个条件!!! 不是具体的范围!!! IN()跟 OR的作用是类似的;



2.2.4 操作符的计算次序 ✔
SQL(像其他语言一样),在处理OR操作符前,优先处理AND操作符,当然为了消除歧义,我们引入了(),此时的计算优先级为
() > AND > OR.
我们不要过分依赖于默认优先级,而选择常用括号去消除歧义.
2.3 排序查询(ORDER BY) ✔
2.3.1 基本格式
SELECT
要查询的字段|表达式|常量值|函数
FROM
表
WHERE
筛选条件
ORDER BY
排序列表 [ASC(默认升序) | DESC(降序)]
2.3.2 排序查询的使用 ✔
-
降序输出工资

-
按照多个列名进行排序

- DESC 只应用到直接位于他前面的列名.
- 多个列名排序优先对第一个进行排序(或字母大小,或数字大小排序),仅仅在第一个列名
完全相同时,才会对后面的列名进行排序;
注意:
排序列表 支持 单个字段、多个字段、函数、表达式、别名
order by的位置一般放在查询语句的最后(除limit语句之外)
2.4 通配符和正则表达式查询(REGEXP)
2.4.1 LIKE和通配符
- 通配符(Wildcard)是用来匹配值的一部分的特殊字符;
- 搜索模式(SearchPattern): 即搜索条件, 由字面值,通配符或两者一起组成;
为在搜索字句中使用通配符,必须使用LIKE操作符.
LIKE告诉SQL,其后跟的搜索模式是利用通配符匹配而不是直接相等匹配进行比较;
| 通配符 | 用途 |
|---|---|
%百分号通配符 | %表示任何字符出现任意次数 |
_下划线通配符 | _只匹配一个字符! |
我们也可以
自定义通配符哦! (通过使用ESCAPE关键字)

Mysql 搜索默认是不区分大小写的;
栗子堆如下:




"_"通配符总是匹配一个字符,不能多也不能少;
使用通配符需要注意:
- 通配符搜索的处理一般比其他搜索所花的时间更长;
- 尽量不要把通配符放在匹配模式的开始处,因为这种搜索是最慢的!
- 注意通配符的位置;
2.4.2 正则表达式(REGEXP) (▲)
正则表达式的作用是匹配文本,将一个模式(正则表达式)与一个文本串进行比较.
Mysql用WHERE子句对正则表达式提供支持,允许你通过"REGEXP"关键字过滤 SELECT检索出的数据.
基本格式: SELECT 列名 FROM 表 WHERE 类名 REGEXP '搜索模式';
正则匹配默认不区分大小写, 如果想要大小写! REGEXP 后面加 BINARY关键字即可;
2.4.2.1 基本字符匹配
| 模式 | 描述 |
|---|---|
| ^ | 匹配以指定字段开始的字符串, 例如,’^ac’是匹配以ac开头的字符串 |
| $ | 匹配以指定字段结束的字符串, 例如,'ST$'是匹配以ST结尾的字符串 |
| . | 匹配除’\n’之外的任何单个字符, 比如 REGXP '.s' 即搜索任意包含字母s的数据 |
举个栗子:

LIKE 和 REGEXP 的不同:
-
LIKE匹配整个字段,如果一个字符串只是这个字段的一部分,那么LIKE不会返回结果; -
REGEXP匹配字段中的任意字符组合. -
举个栗子:


2.4.2.2 进行 OR 匹配
使用 | 从功能上类似于在SELECT语句中WHERE条件后使用OR语句;
| 模式 | 描述 |
|---|---|
| abc|xyz|bmp | 匹配包含abc或xyz或bmp的字符串,例如,‘z|food’ 能匹配 “z” 或 “food”。’(z|f)ood’ 则匹配 “zood” 或 “food”。 |
举个栗子:


2.4.2.3 匹配几个字符之一(▷)
| 模式 | 描述 |
|---|---|
| [abc] | 匹配任何包含a或b或c的字符串 |
| [^abc] | 匹配未包含a或b或c的字符串 |
举个栗子:

Q:[^abc]的使用???
2.4.2.4 匹配范围
集合可以用来定义要匹配的一个或多个字符.
如: [0-9]匹配数字, [a-z]匹配字母;
2.4.2.5 匹配特殊字符
多数正则表达式实现使用单个反斜杠转义特殊字符以便能使用这些字符本身.但
Mysql要求,两个反斜杠(MySQL自己解释一个,正则表达式库解释另一个);
注意此处的双反斜杠\\ 仅适用于正则表达式匹配中, 其他地方还是 单个反斜杠\
举个栗子:
'\\\'表示使用反斜杠;
'\.'表示使用.;
'\-'表示使用-;
2.4.2.6 匹配字符类 (待补充)
2.4.2.7 匹配多次(▷)
| 模式 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次,例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次,例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的一个字符零次或一次 |
| {n} | n是一个非负整数,匹配确定的n次.例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,m} | m,n均为非负整数,其中n<=m. 最少匹配n次且最多匹配m次 |
举个栗子:
? 匹配0或1次
*匹配0或多次
+ 匹配1或多次
🌰
2.5 常见函数 (★)
2.5.1 字符函数
| 函数 | 说明 |
|---|---|
| Left() | 返回串左边的字符 |
| Right() | 返回串右边的字符 |
| Length() | 返回串的字节个数 |
| Locate(子串,串或列名) | 找出串的一个子串 |
| Lower() | 将串转换为小写 |
| Upper() | 将串转换为大写 |
| LTrim() | 去掉串左边的空格 |
| RTrim() | 去掉串右边的空格 |
| SubString() | 返回子串的字符 |
| Concat() | 拼接字符串 |
subString, INSTR 的索引都是从1开始的!!!!
subString(字符串, pos, length) 中 length是指打印出的长度;
# 1. Upper()/Lower()-----------大小写函数
SELECT CONCAT(UPPER(first_name),'-',LOWER(last_name)) FROM employees;
# 2. CONCAT()-------------字符串拼接
#示例同上;
# 3. Length()------------------求字符串的长度
SELECT length("啊哈哈大SB") "字符串长度";
# 4. Trim()----------------消除字符的左右空格( LTrim(), RTrim())
SELECT TRIM(" 我饭呢? ") AS "trim()消除空格";
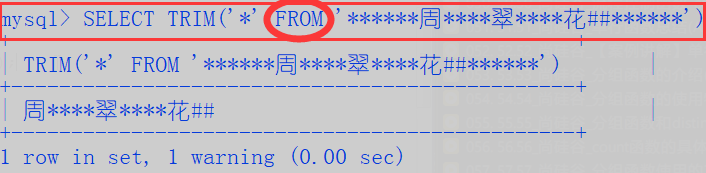
##下面这句意思是从FROM后面的语句中删除左右两边的字符*,记住,只是左右两边的噢!
SELECT TRIM('*' FROM '******周****翠****花##******');
# 5. Replace(字符串,被替换字符,替换字符)-----------替换字符
#用z去替换字符串中的d
SELECT Replace('abcdefg','d','z') AS 'replace替换字符';
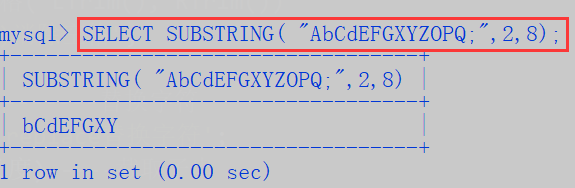
# 6. SubString/Substr(字符串,开始位置,截取长度)-----截取子串(mysql 的去子串函数从索引1开始的!)
SELECT SUBSTRING( "AbCdEFGXYZOPQ;",2,8);
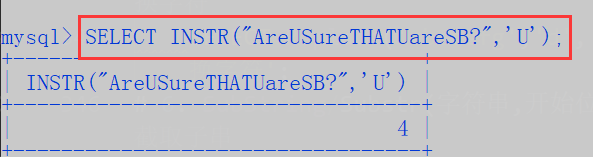
# 7. InStr-----------获取字符第一次出现时的位置;
SELECT INSTR("AreUSureTHATUareSB?",'U');
# 8. LPAD("字符串",替换次数,要被填充的字符), RPAD-------------左边或右边填充字符
## 注意! 填充的字符数量为[替换次数-字符串长度] 噢!!! 记清楚咯
SELECT LPAD('周翠花',6,'*');
举个🌰:
- trim()消除空格

- SubString() 截取子串
- InStr() 获取子串在字符串中的索引
- LPAD() 左填充;

举个栗子:



2.5.1.1 字符函数之 拼接字段(concat())
拼接(concatenate): 将多个字段连接在一起构成单个值;
CAUTION: 多数的DBM使用’+‘或’||'来实现拼接,但是在Mysql中使用concat()函数实现拼接!
举个栗子:


拓展:
- Mysql中的 '+'操作符

- 使用concat()时,
如何处理NULL值?
举个栗子:
Q: 显示出表employees的全部列,各个列之间用逗号连接,列头显示为’OUTPUT’;
SELECT concat(first_name,',',last_name,',',job_id,',' ,commission_pct) AS OUTPUT
FROM employees;
- 输出如下:

如何处理?
使用 IFNULL(待处理的列名,替换NULL的值)函数.补充: IFNULL函数;
功能:判断某字段或表达式是否为null,如果为null 返回指定的值,否则返回原本的值
如: select ifnull(commission_pct,0) from employees;
再来个栗子:
- 查询员工号为176的员工的姓名,部门号和年薪;

2.5.2 数学函数
MySQL支持基本算数操作符, + - * /.
- 举个栗子:

常用的几个数学函数
1. ROUND(数值,指定保留到小数点后几位)----四舍五入
2. Truncate(数值,保留位数)------保留小数点若干位
3. MOD(A,B)---- AmodB 取余
## AmodB 等价于 A-A/B*B, 记住其结果是 A为负数,则值为负数; A正则值为正;
4. ceil() ---向上取整(返回大于等于该参数的数);
floor()---- 向下取整(小于等于);
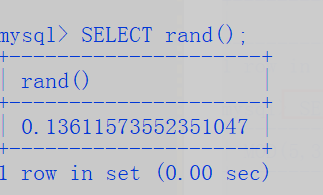
5. rand() 获取随机数,返回0-1之间的小数


2.5.3 日期函数(▷)
-
格式符

-
常见用法



-举个栗子:
### h 12小时制, H 24小时制
#### 前后的间隔符需要一一对应!
SELECT STR_TO_DATE('20-02.1989 20:02:23','%d-%m.%Y %H:%i:%s');
SELECT STR_TO_DATE('08.09.2008 08:09:30', '%m.%d.%Y %h:%i:%s'); -- 2008-08-09 08:09:30


2.5.4 流程控制函数(★)
-
IF函数–等同于Java中的 if else 语句.
/*
基本格式: IF(条件判断, 条件为真的表达式1, 条件为假的表达式2)
*/
#栗子1:
SELECT IF(10>1, '大于', '小于');
#栗子2:
SELECT last_name, commission_pct,IF(commission_pct is NULL,'我没有,好烦','哈哈.我有') AS '奖金' FROM employees;

- 2.
CASE函数1(类似于Java的switch…case语句)
一般用于等值判断
- when中的常量都是case中字段可能的值
用在SELECT中, case后是表达式或字段,而then后是值用在函数或存储过程中, case后面是语句, then后是语句
case 要判断的变量,字段或表达式
when 常量1 then 要显示的值1或语句1;
when 常量2 then 要显示的值2或语句2;
...
else 要显示的值n或语句n;
end
举个栗子:
/* 案例1: 查询员工的工资,要求:
部门号=30, 显示的工资为1.1倍;
部门号=40, 显示的工资为1.2倍;
部门号=50, 显示的工资为1.3倍;
其他部门,显示的工资为原工资;
*/
SELECT salary 原始工资, department_id,
CASE department_id
WHEN 30 THEN salary*1.1;
WHEN 40 THEN salary*1.2;
WHEN 50 THEN salary*1.3;
ELSE salary
END AS 新工资
FROM employees;
# 案例2: 查询奖金的档次
SELECT last_name, commission_pct,
CASE commission_pct
WHEN 0.1 THEN '聊胜于无'
WHEN 0.15 THEN '马马虎虎'
WHEN 0.2 THEN '还凑合吧'
ELSE '就是比0.2强'
END AS 奖金档次
FROM employees
WHERE commission_pct IS NOT NULL
- 3.
CASE函数2(类似于Java的多重if语句)
一般用于区间判断
CASE
WHEN 条件1 THEN 要显示的值1或语句1
WHEN 条件2 THEN 要显示的值2或语句2
...
ELSE 要显示的值n或语句n
END
举个栗子:
/* 案例: 查询员工的工资情况,要求:
如果工资>20000, 显示A级别,
如果工资>15000, 显示B级别,
如果工资>10000, 显示C级别,
否则,显示D级别
*/
SELECT employee_id, salary,
CASE
WHEN salary>20000 THEN 'A'
WHEN salary>15000 AND salary<=20000 THEN 'B'
WHEN salary>10000 AND salary<=15000 THEN 'C'
ELSE 'D'
END AS 工资级别
FROM employees;
2.6 汇总数据
- 我们经常需要汇总数据而不用把它们实际检索出来,为此MySQL提供了专门的函数. 使用这些函数,MySQL查询可用于检索数据,以便分析和报表的生成.这些类型的检索例子包括:
- 确定表中行数
- 获得表中行组的和;
- 找出表列的最大值,最小值和平均值.
- 为了方便这种类型的检索,MYSQL提供了以下五个函数;
SQL聚集函数
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
聚集函数的特点
- 1.SUM, AVG一般用于处理数值型; MIN, MAX, COUNT可以处理任何类型;
- 2.所有的聚集函数
都忽略NULL值; - 3.也都可以
和DISTINCT关键字搭配实现去重运算;
- AVG()的使用, 单个列, 必须给出列名
- 只用于
单个列. AVG()只能用来确定特定数值列的平均值,而且列名必须作为函数参数给出. 为了获得多个列的平均值,必须使用多个AVG()函数; - AVG()函数
忽略列值为NULL的行;
举个栗子:

- COUNT()的使用
- 使用COUNT(),可以确定表中
行的数目或符合特定条件的行的个数; - 一般使用count(*)用于统计行数;
COUNT()函数有两种使用方法:
- 使用
COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值;- 使用
COUNT(列名)对特定列中具有值的行进行计数,忽略NULL值.

- 返回特定列的最大值(MAX())或最小值(MIN())

- MAX()和MIN()同样可以比较字符串大小;
- 使用SUM()计算给定列的和
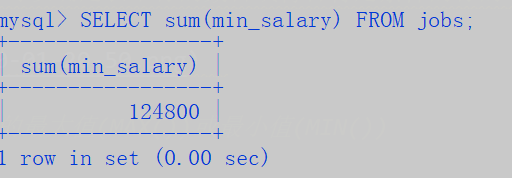
- sum() 同样可以用来合计计算值;

和聚集函数一同查询的字段要求是 GROUP BY 后的字段;
2.7 分组数据
- 格式:
SELECT 分组函数| 分组后的字段
FROM 表
[WHERE] 筛选条件
GROUP BY 分组的字段
[HAVING] 分组后的筛选
[ORDER BY] 排序列表
分组数据需要死记的几个关键点
- 对谁分组,谁就可以出现在SELECT中.
WHERE关键字的位置在 GROUP BY之前.即在分组前进行筛选,WHERE 筛选对象是原始表中的列名.`HAVING关键字的位置在 GROUP BY之后.即在分组后筛选,HAVING 筛选对象是分组后的结果.- 分组函数(即聚集函数 MAX,MIN,SUM,AVG,COUNT)作为筛选条件的,一定是放在HAVING字句中.
- 能用分组前筛选的,就优先考虑分组前筛选.
🌰栗子如下:
先看employees表结构:

- # 邮箱中包含a字符的每个部门的平均工资
SELECT department_id 部门, AVG(salary) 平均工资
FROM employees
Where email LIKE '%a%';
GROUP BY department_id;
- # 有奖金的每个领导手下员工的最高工资
SELECT manager_id, MAX(salary)
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY manager_id;
- # 查询哪个部门的员工数>2
# WHERE是筛选行, HAVING是删选组
SELECT department_id 部门, count(*) 员工数
FROM emlpoyees
GROUP BY departement_id
HAVING count(*)>2
- # 查询每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
SELECT job_id 工种, MAX(salary) 最高工资
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary) > 12000
- # 查询领导编号>102的每个领导手下的最低工资>5000的领导编号是哪个,以及其最低工资
SELECT manager_id, MIN(salary)
FROM employees
WHERE manager_id > 102
GROUP BY manager_id
HAVING MIN(salary) > 5000;
- # 按员工姓名的长度分组,查询每一组的员s工个数,筛选员工个数>5的有哪些
SELECT length(last_name), COUNT(*) 个数
FROM employees
GROUP BY length(last_name)
HAVING COUNT(*) >5;
- # 查询每个部门每个工种的员工的平均工资
SELECT department_id 部门, job_id 工种, AVG(salary) 平均工资
FROM employees
GROUP BY department_id, job_id;
