

零, 消息队列的两种模式和应用场景, 以及Kafka 消息队列的特点
零, 消息队列
自问自答环节:
[0.什么是消息队列(MQ) ?]
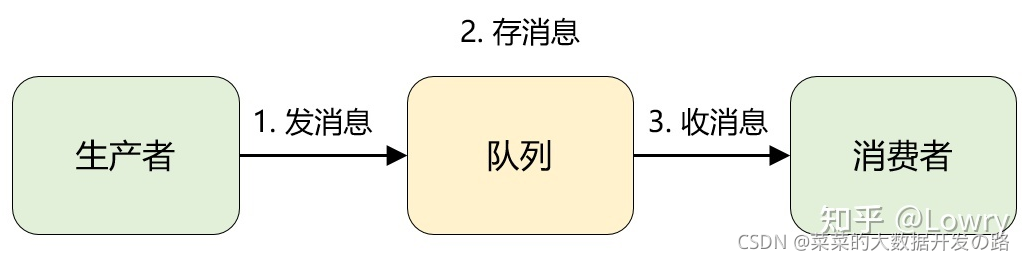
- 消息队列从实质上来说就是一个包含了消息发送接收对象, 存放消息队列的结构, 可归结为:
一发一存一消费,. - 综上来看, 消息队列就是: 生产者将消息投递到一个叫队列的容器中, 然后再从这个容器中取出消息, 最后转发给消费者.
- 消息队列MQ 最常用的模式有两种, 点对点模式 和 发布/订阅模式.
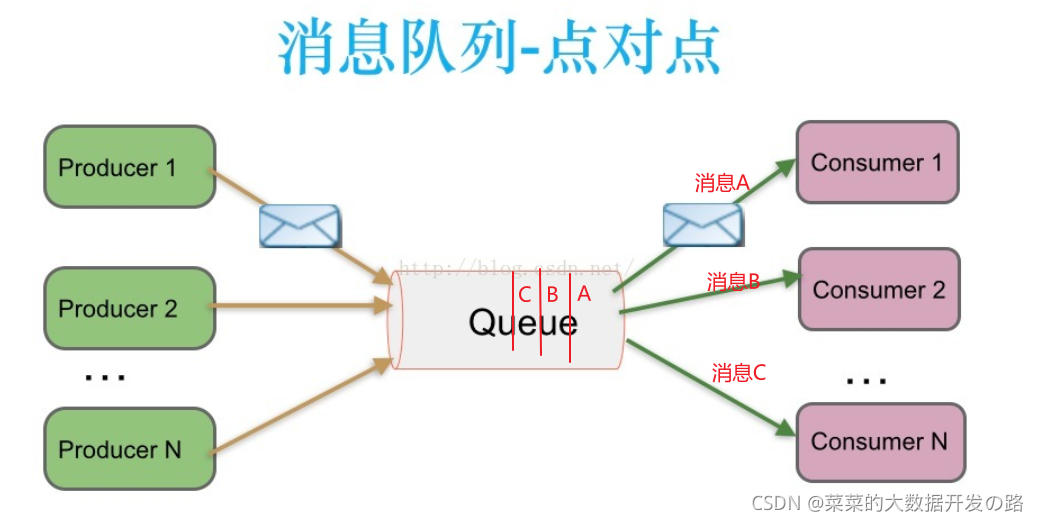
[1. 什么是点对点模式?]
- 就是前面提到的最原始的消息队列,生产者把消息存储到队列中, 消费者从队列中取出消息, 如果存在多个生产者, 那么他们之间是竞争的关系, 每一条消息被一个消费者消费后会被删除掉, 所以
点对点模式是不可以重复消费信息的.
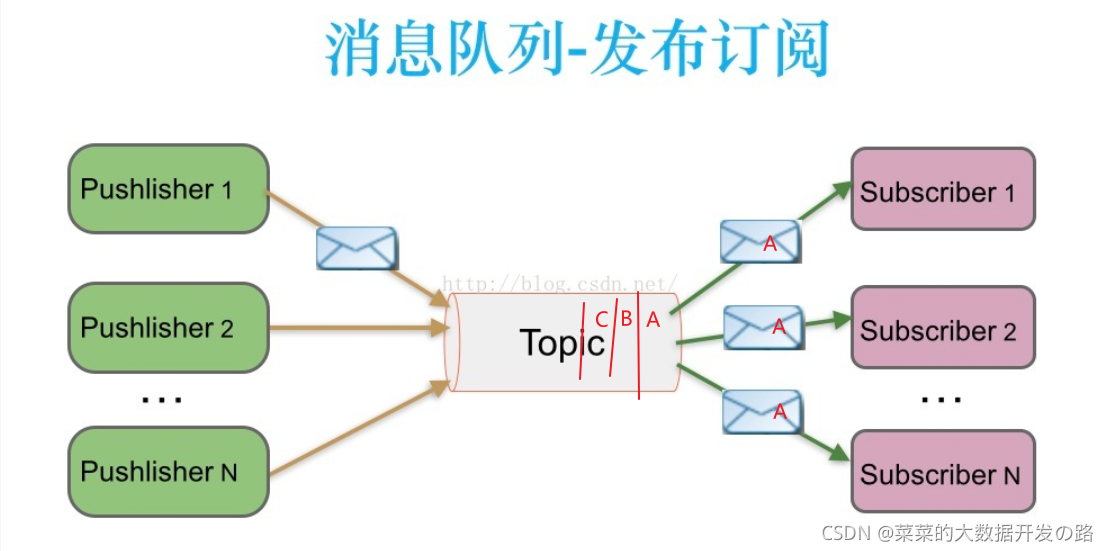
[2. 什么叫 发布/订阅模式? ]
-
如果需要将同一份消息数据分发给多个消费者, 并且每个消费者都要求收到全量的消息, 点对点模式无法满足要求.
-
那么, 为每个消费者传建一个单独的消息队列, 让生产者发送多份相同消息? 不太行, 辣么多消息队列,还存相同数据, 多浪费存储空间呀.
-
在发布/订阅模型中, 存放消息的队列容器变成了主题(topic), 每个消费者变成了订阅者, 在消费信息之前需要先订阅主题, 最终每个订阅者都可以收到一份相同的数据.所以,
发布/订阅模式是可以多次消费一份数据的
-
仔细对比下它和 “队列模式” 的异同:生产者就是发布者,队列就是主题,消费者就是订阅者,无本质区别。唯一的不同点在于:一份消息数据是否可以被多次消费。
参考资料和补充:
[3. 消息队列的好处和应用场景? ]
1. 解耦
- A需要B接口的特定数据, 如果直接A调用B接口, 那么当B接口宕机了, A也就处于停摆的状态, 此时A与B就处于耦合的状态.
当使用了消息队列时, B只需要把A需要的特定数据放在队列中, 无论是后面C需要了还是A不需要B的数据了, B都不关心, 这个时候B与其他使用他数据的对象就是解耦的了.
- 举个栗子:

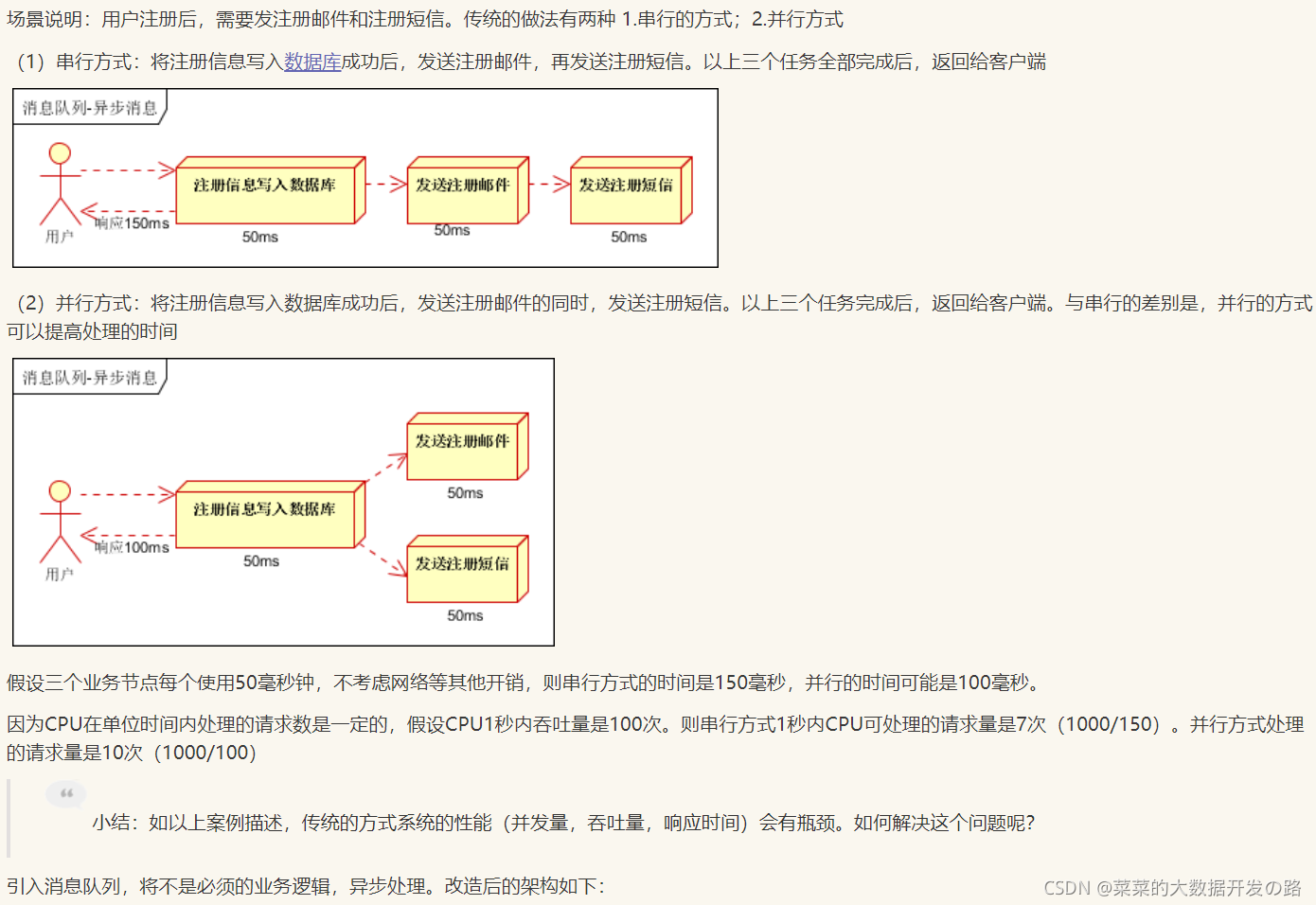
2. 异步
一个系统有主要的业务和次要的业务,如果我们想要提高主要业务的响应速度, 可以在主要业务完成后立马返回,而把次要业务写入消息队列,稍后处理.
- 举个栗子:
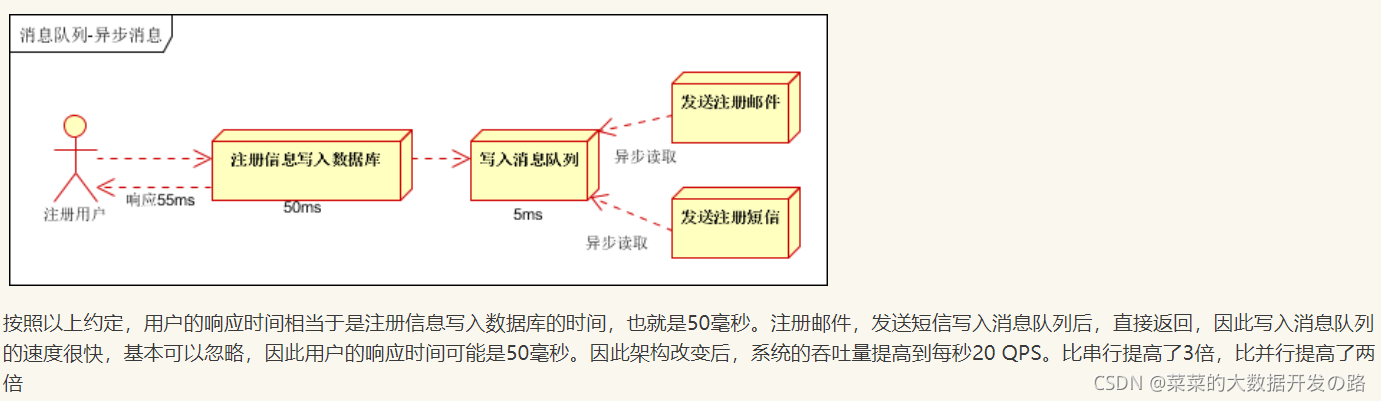
3. 削峰
- 当系统要处理的请求数暴增时, 为了避免系统宕机, 我们可以把请求写到消息队列中, 然后让系统从消息队列中取出一次性能处理的请求数
- 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
- 举个栗子:

4. 缓冲
- 有助于控制和优化数据流过系统的速度, 解决生产消息和消费消息的处理速度不一致的情况.
5. 可恢复性
- 系统的一部分组件失效时, 不会影响到整个系统. 消息队列降低了进程间的耦合度, 所以即使一个处理消息的进程挂掉, 加入队列中的消息仍然可以在系统恢复后被处理.
6, 日志处理, 消息通讯
参考资料和补充:
壹, Kafka消息队列的特点
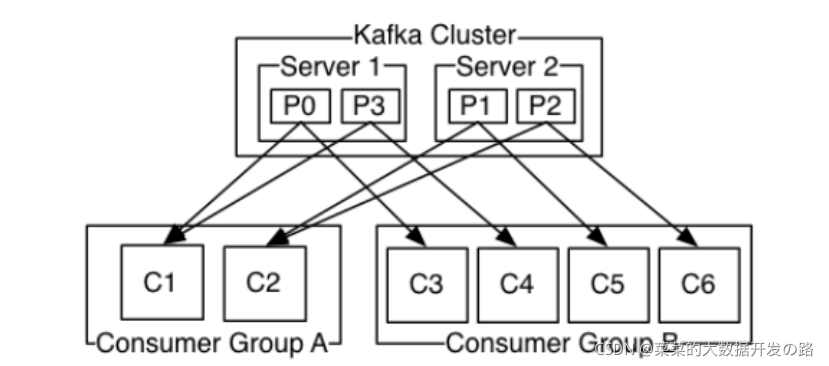
- 传统的消息队列通常最少提供上面提到的两种消息模型, 即点对点模式(P2P)和发布/订阅模式(PUB/SUB), 而Kafka并没有这么做, 而是巧妙的提出了一个消费者组的概念.
- 在Kafka消息队列中, 一个消息可以被多个消费者组消费, 但是只能该被一个消费者组里的一个消费者消费, 这样的话,
- 当只有一个消费者组的时候, 就等用于点对点模式(消费者组的每个消费者单独消费其中的一条数据);
- 当存在多个消费者组时候, 就是发布/订阅模式(多个消费者组同时消费多个topic中的多条数据)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)