

五-2, Scala集合常用函数全总结
五-2, 集合常用函数
在学习本文之前, 必须掌握以下知识点
- 函数的最简化原则
- 元组的概念和使用方法
- 函数柯里化
- 隐式参数(可选)
1. 集合的基础方法/函数
| 用法 | 解释 | Array, List, Set, Map使用区别 |
|---|---|---|
| xx.length 或 xx.size | 获取集合长度(大小) | (Array, List均有length, size方法, 而Set, Map只有 size方法) |
| xx.foreach(println) | 循环遍历 | 均可使用 |
| xx.iterator | 迭代器 | 均可使用 |
| xx.mkString(连字符) | 输出集合内容, 添加连字符 | 均可使用, 这四个类就Array没有实现toString, 用arr.mkString("Array(",",",")")可以达到别的集合调用toString的效果 |
| xx.contains(k) | 是否包含某key | 均可使用 |
| 用法 | 解释 | Array, List, Set, Map使用区别 |
|---|---|---|
| xx.head | 获取集合的第一个元素 | 均可使用, map.head是第一个键值对 |
| xx.last | 获取集合的最后一个元素 | 均可使用, 由于Array不存在tostring() ,array.last返回的是地址值 |
| xx.tail | 获取集合的尾部, 注意这里的尾部是指除了集合头部第一个值的部分 | array.tail返回的是地址值 |
| xx.reverse | 反转集合 | Set和Map不可使用 |
| xx.take(n) 和 xx.takeRight(n) | 取前(后)n个元素 | 均可使用, array.take(n) 返回的是地址值 |
| xx.drop(n) 和 xx.dropRight(n) | 去除前(后)n个元素 | 均可使用, Array.take(n) 返回的是地址值 |
| xx.union(yy) | 求前后两个集合的并集,并集一般需要去重 | map使用 ++ 合并不可变map, 没有union方法 |
| xx.diff(yy) | 返回的是xx中与yy不同的数据, 即差集 | map不可用 |
| xx.zip(yy) | 拉链, 把xx和yy中的数两两结合, 多出的数据直接省略 | 均可使用 |
| xx.sliding(窗口长度, 步长) | 滑动窗口, 返回的是一个迭代器对象, 需要用迭代器或者增强for循环遍历出结果; 步长是指窗口每次滑动的距离, 即每个窗口之间的距离; 当滑动窗口大小跟步长一样是时, 各个窗口之间就不会有交集 !! | 均可使用 |
2. 集合的简单计算函数
| 用法 | 解释 | Array, List, Set, Map使用区别 |
|---|---|---|
| xx.sum | 获取集合中数字的和 | Map不可直接使用 |
| xx.product | 获取集合中数字的乘积 | Map不可直接使用 |
| xx.min 和 xx.max | 获取单列集合中数字的最小值和最大值 | map不可直接使用 |
| xx.minBy((tuple: (数据类型)) => 元组中的第几个进行比较) | 获取带有复合数据(元组)的集合中的最小元组 | 均可使用, map1.minBy((tuple:(String, Int)) => tuple._2) |
| xx.maxBy((tuple: (数据类型)) => 元组中的第几个进行比较) | 获取带有复合数据(元组)的集合中的最大元组 | 同上 |
| xx.sorted | 对单列集合进行自然排序 | Map不可直接使用, map不可直接排序, 所以通常都是转为List再排序, xx.toList |
| xx.sortBy(f) | 对复合数据进行排序 | Map不可使用,转为List再排序 |
| xx.sortWith(f) | 对复合数据进行自定义排序, sortWith(lt: (A, A) => Boolean | Map不可使用,转为List再排序 |
[代码示例]
/// 集合常用函数 sum, min, max, sortBy(sortWith)
println(arr1.sum)
println(list1.sum)
println(set1.sum)
//println(map1.sum()) ??
//1. min,max
println(arr1.min + " ;" + arr1.max)
println(list1.min+ " ;" + list1.max)
println(set1.min+ " ;" + set1.max)
//1.1 minBy, maxBy
// 对待复合数据类型进行排序(元组)
val list: List[(String, Int, Double)]= List(("小狗", 18, 172.5), ("小周", 13, 168.2), ("小陈", 23, 188), ("王二", 48, 156))
println(list.minBy(tuple => tuple._2)) //最低年龄 (小周,13,168.2)
println(list.maxBy(tuple => tuple._3)) //最高身高 (小陈,23,188.0)
println(list.minBy(_._3)) //对函数进行最简化, 最低身高 (王二,48,156.0)
//2 sorted 自然排序
println("sorted 自然排序: " + list1.sorted)
传入隐式参数, 倒序排序
println("sorted+ 隐式参数, 自然排序: " + list1.sorted(Ordering[Int].reverse))
//2.1 sortBy(f) 默认顺序排序
println(list.sortBy((tuple: (String, Int, Double)) => tuple._2)) //按照元组的第二个元素排序
println(list.sortBy(tuple => tuple._2)) //简化
println(list.sortBy(_._2)) //进一步简化
//2.2 借助隐式参数(? 柯里化)
println(list.sortBy(_._2)(Ordering[Int].reverse))
//2.3 sortWith 自定义排序, sortWith(lt: (A, A) => Boolean)
println("自定义排序" + list.sortWith((tuple1, tuple2) => tuple1._2 > tuple2._2))
println("自定义排序: " + list.sortWith(_._2 > _._2)) //简化
3. 集合的高级计算函数
- 相当于Hadoop的Map过程的函数, 对数据进行过滤和修改
注意: 对于这些函数, 掌握每个函数操作的元素类型(一般是调用集合的子元素类型), 以及对这些元素操作的语句是如何影响到最终结果, 这两点非常重要!
| 用法 | 说明 | Array, List, Set, Map使用情况 |
|---|---|---|
| xx. filter(f) | 过滤, 通过指定函数过滤掉集合中的某些数从而组成一个新集合, 留下的是满足函数f的数 | |
| xx.map(f(elem=> 对elem操作的语句)) | 转化/映射, 通过函数把集合中的每一个elem转换为新的集合, elem代指的是xx集合中的每一个组成元素, elem的类型就是xx集合的亲儿子类型, 如list.map((elem:Array[String]) => 对elem的转换函数), list 的类型是 List[Array[String], map后的结果就是对elem操作的转换函数的结果 | |
| xx.flatten | 扁平化, 先把集合中的元素拆成独立个体(不可再拆分的个体), 再合并一个新集合 | |
| xx.flatMap(f(elem => 对elem转化的语句)) | 先转化再扁平化, 即先通过map函数转化xx的每一个元素(即elem), 再剥离成独立个体并合并一个大集合, elem的界定同上 | |
| xx.groupBy(f: (elem => 对elem进行操作)) | 分组,按照指定的规则对集合的元素进行分组, groupBy生成的是一个Map集合,这个map 的key是对elem的操作的结果, 而value是 符合这个操作结果的元素集合, elem的界定同上 |
- 相当于Hadoop的Reduce过程的函数, 对集合数据进行归一化计算(聚合)
| 用法 | 说明 | Array, List, Set, Map使用情况 |
|---|---|---|
| xx.reduce(op:(A1-聚合后的元素, A1-下一个遍历的元素) => A1) | 简化(规约), 从左边, 两两计算, 计算得到的结果作为一个数再和第三个数进行计算, 如此往复, 直至得到最终的一个结果 | |
| xx.reduceRight(op:(A1-聚合后的元素, A1-下一个遍历的元素) => A1) | 简化(规约), reduceRight(op:(A,A) => A) 从右向左两两计算, 采用了递归实现 | |
| xx.fold(z-初始状态: A1)(op: (A1-聚合后的元素, A1-下一个遍历的元素) => A1) | 折叠, 与reduce一样, 也是两两计算进行归一化,只是多了一个指定初始值参数(z指定的就是初始值) | |
| xx.fold(z-初始状态: B)(op: (A-聚合后的元素, B-下一个遍历的元素) => B) | 折叠, 与reduce一样, 也是两两计算进行归一化,只是多了一个指定初始值参数(z指定的就是初始值) | |
| xx.foldRight(z-初始状态: B)(op: (A-聚合后的元素, B-下一个遍历的元素) => B) | 折叠, 与reduceRight一样, 也是从右边两两计算进行归一化,只是多了一个指定初始值参数(z指定的就是初始值) |
[案例实操]
filter, map, flatten, flatMap, groupBy
package advancedfunctiondemo
object AdvancedFunctionDemo {
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9)
val list3: List[Array[Int]] = List(Array(0,2,3), Array(2,45,656,7), Array(2,5,6,7))
val nestedList: List[List[Int]] = List(List(1, 2, 3), List(4, 5, 6), List(7, 8, 9))
val wordList: List[String] = List("hello world", "hello sb", "hello fellow")
val wordList1: List[String] = List("apple", "banana", "orange", "oil", "alice")
Map操作
>>> //1. xx. filter 过滤, 通过指定函数过滤掉集合中的某些数从而组成一个新集合
val list1: List[Int] = list.filter(x => x % 3 == 0)
println(list1)
///1.1 反向过滤
println(list.filterNot(x => x % 3 == 0))
println(list.filterNot(_ % 3 == 0)) //化简
>>> //2. xx.map 映射/转化, 通过函数把集合中的每一个元素转换为新的集合
println(list.map(x => x * 2))
//map是对集合list3中的每一个元素进行相关操作. 什么操作? 求每个元素的min值, 什么类型的元素? lists3存储的数据及Array[Int]元素
println( list3.map(x => x.min)) //List(0, 2, 2)
>>> //3. xx.flatten 扁平化, 先把集合中的元素拆成独立个体, 再合并成新的集合
println(nestedList.flatten)
println(list3.flatten) //List(0, 2, 3, 2, 45, 656, 7, 2, 5, 6, 7)
>>> //4. xx.flatMap 扁平映射, 先转化再扁平化, 即先通过函数转化, 再剥离成独立个体并合并一个大集合
4.1哎, 我先进行转化看下
//我把wordlist中的每个元素(如hello world)按照空格进行切分 split(" "), 每个元素切分的结果是String数组
// 所以map的结果是生成了以String数组为元素的List
var words: List[Array[String]] = wordList.map(word => word.split(" "))
//words的形式就是: List[Array[hello, word], Array[hello, sb], Array[hello, fellow]]
//验证方法: println(words.foreach(x => print(x.mkString("Array(",",",")"))))
///4.2哎, 然后我再把转化后的结果进行扁平化
// 扁平的过程就是把 words中的每个元素(string数组为元素的List), 转化为一个一个的string(也就是每个单词), 然后把这个数组放到大集合中返回
println(words.flatten)
//简单点
println(wordList.flatMap(x => x.split(" ")))
//再来个栗子
println(list3.flatMap(_.map(_ + 2))) //List(2, 4, 5, 4, 47, 658, 9, 4, 7, 8, 9)
println(list3.flatMap(x => x.map(y => y + 2))) //List(2, 4, 5, 4, 47, 658, 9, 4, 7, 8, 9)
>>> //5. xx.groupBy(f) 根据函数的值(余数/布尔)进行分组,
// 组名作为key, 本组内的元素作为value, 形成一个Map
println(list.groupBy(x => x % 3 == 0))
// groupBy(x => 对x的操作), 注意,
// groupBy生成的是一个Map集合,
// 这个map 的key对x的操作的结果,
// 而value是 符合这个操作结果的元素集合,
// 这个元素就是list的组成元素噢
println("lllllll: " + nestedList.groupBy((x:List[Int]) => {
x.takeRight(1)
}))
5.1 分组自定义组名
val map: Map[String, List[Int]] = list.groupBy((x: Int) => {
if (x % 2 == 0) "偶数"
else "奇数"
})
println(map)
5.2 按照单词的首字母进行分组
//注意哦, x 一般指代的是前面调用集合对象的元素
val map1 = wordList1.groupBy((x: String) => {
x.charAt(0)
})
//化简: wordList1.groupBy(_.charAt(0))
println(map1)
reduce, fold
Reduce操作
//6. xx.reduce
//所有的元素保持一个状态, 然后进行叠加处理
/6.1 reduce((A1, A1) => A1) 意思是 第一个数和第二进行规约生成一个数a,
// 再把这个数a和第三个数进行规约, reduce的底层是reduceLeft, 即从左向右两两规约
// 从左边, 两两计算, 计算得到的结果作为一个数再和第三个数进行计算, 如此往复, 直至得到最终的一个结果
val list2: List[Int] = List(3, 4, 5, 8, 10)
val i = list2.reduce((x, y) => x - y) // (((a-b)-c)-d)...) 结果为 24
println(i)
/6.2 reduceRight((A,A) => A) 从右向左规约, 采用了递归实现,
// 简单点, 可以看作是ReduceLeft的反向操作,
val j = list2.reduceRight(_ - _) // (a-(b-(c-d))) 结果为6
println((j))
//7. xx.fold(z: B)(op: (A, B) => B)
//fold与reduce基本一样,只是多了一个指定初始值参数,
// 注意这个时候计算从初始值z开始,而不是第一个元素开始, 初始值在最左边
val i1: Int = list2.fold(10)(_ - _) // (((((10 - 3) - 4) - 5)-8) -10) 为 -20
println(i1)
//同样的, foldRight 为 fold或foldLeft的反向操作, 初始值在最右边
val j1: Int = list2.foldRight(10)(_ - _) // (3-(4-(5-(8-(10-10)))))) 为 -4
println(j1)
}
}
4. 对合并Map利用函数进行改进 (*)
- 先前我们使用
map1 ++ map2来合并两个map, 存在的问题是如果两个map的key相同, 那么map1的value就会被map2覆盖掉 - 有什么办法能让两个map中key相同的进行value的叠加呢?
- 这里我们用到了归一化(reduce/fold), 用map1的kv不断的去更新map2的kv, 即 map2是作为了初始值, 所以我们对map1进行归一化, 由于有了初始状态, 所以使用fold
- 然而前面我们提到, fold(z: A1(初始状态))((A1(聚合后的元素), A1(下一个遍历的元素)) => A1), 聚合后的元素和下一个遍历的元素的数据类型要求必须相同, 我们使用两个map聚合时, 聚合后的元素是一个map, 而下一个遍历的元素是kv对, 这就不能用fold, 而选用 foldLeft(z:A1)((A1, B1) => A1)
package mergemapdemo
import scala.collection.mutable
object MergeMap {
def main(args: Array[String]): Unit = {
//
val map1: Map[String, Int] = Map(("a", 15), "b" -> 18, "c" -> 22, "d" -> 23)
val map2: Map[String, Int] = Map(("x", 32), "y" -> 38, "z" -> 28, "p" -> 45)
println(map1 ++ map2)
// 为什么使用可变的map? 因为map2是不断更新的, 用可变map不是更好吗
val mutableMap2: mutable.Map[String, Int] = mutable.Map(("x", 32), "y" -> 38, "z" -> 28, "p" -> 45)
//mergeMap是两两聚合后的map, kv指的是下一个待聚合的键值对
//kv不断的被遍历
val map = map1.foldLeft(mutableMap2)((mergeMap, kv) => {
// kv是谁的kv? 由于map2是初始值, 所以需要遍历map1去比对map2, 更新后的map用mergeMap指代
// kv是map1的kv哦
val key = kv._1
val value = kv._2
//每次遍历map1, 用map1的key获取map2的值, 并把map1的value和这个值叠加, 然后更新(mergeMap(key))
mergeMap(key) = mergeMap.getOrElse(key, 0) + value
mergeMap
})
println(map)
}
}
4. 普通的WordCount案例
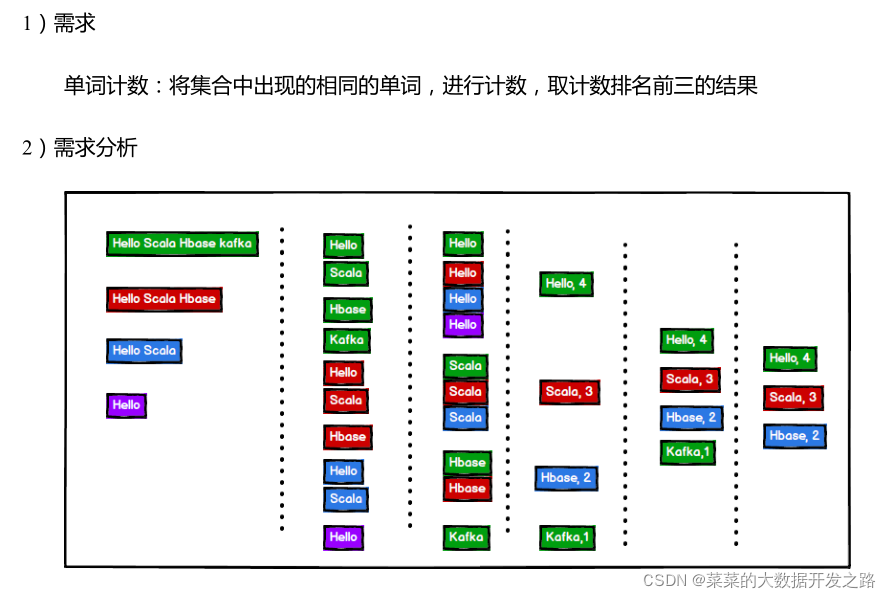
[代码示例]
package wordcountdemo
object SimpleWordCount {
def main(args: Array[String]): Unit = {
//定义集合
val list:List[String] = List("Hello Scala Hbase Kafka", "Hello Scala Hbase", "Hello Scala", "Hello")
//相同单词进行计数
//0. 老方法, 易于理解的方法, 先转化, 即把list中的string 转化为每一个单词的string
val words:List[Array[String]] = list.map(x => x.split(" ")) //把集合list中的每个大string切割为一个一个的单词的string
//注意噢! x.split(" ")生成的是List[Array[String]]类型的list, 这样的话, 再用map才会生成一个个的Array[String], 即一个个单词!!!!
//words.iterator.foreach(x => println(x.mkString("Array(",",",")")))
/** 上面的words是这样的形态
* Array(Hello,Scala,Hbase,Kafka)
Array(Hello,Scala,Hbase)
Array(Hello,Scala)
Array(Hello)
*/
val wordsList: List[String] = words.flatten
println()
/** 对words扁平化后的状态
* List(Hello, Scala, Hbase, Kafka, Hello, Scala, Hbase, Hello, Scala, Hello)
*/
//1. 切分单词, 即扁平映射/扁平映射 xx.flatMap
val wordList1: List[String] = list.flatMap(x => x.split(" "))
println(wordList1)
//2. 相同单词进行分组
// groupBy的结果是一个MAP, x代表着被分组集合中的每个元素, 对x操作的结果是生产的map的key
// 所以x就是集合wordlist中的一个个的单词, 我们直接按照x分组就是按照单词分组
val wordsGroupMap = wordsList.groupBy((x) => {
x
})
println(wordsGroupMap)
//3. 对Map中的某一列元素进行计数, 即
val wordCountMap: Map[String, Int] = wordsGroupMap.map((tuple: (String, List[String])) => (tuple._1, tuple._2.size))
//4. 排序
// map不可直接排序, 所以通常都是转为List再排序
println(wordCountMap)
val list1 = wordCountMap.toList
println(list1)
val orderedList = list1.sortBy((tuple: (String, Int)) => tuple._2)
println(orderedList)
//5. 取出前三个
val res = orderedList.take(3)
println(res)
}
}
我们一般不会对map进行直接排序, 而是先map.toList, 把map转为list之后再进行排序
5. 复杂的WordCount案例(待掌握)
- 同上面的问题一直, 按照单词分组并统计出现频次
- 下图给出了每个字符串出现的频次

package chapter07
object Test18_ComplexWordCount {
def main(args: Array[String]): Unit = {
val tupleList: List[(String, Int)] = List(
("hello", 1),
("hello world", 2),
("hello scala", 3),
("hello spark from scala", 1),
("hello flink from scala", 2)
)
// 思路一:直接展开为普通版本
val newStringList: List[String] = tupleList.map(
kv => {
(kv._1.trim + " ") * kv._2 //*对于字符串就是把字符串复制了 `字符串 * 次数`次
}
)
println(newStringList)
// 接下来操作与普通版本完全一致
val wordCountList: List[(String, Int)] = newStringList
.flatMap(_.split(" ")) // 空格分词
.groupBy( word => word ) // 按照单词分组
.map( kv => (kv._1, kv._2.size) ) // 统计出每个单词的个数
.toList
.sortBy(_._2)(Ordering[Int].reverse)
.take(3)
println(wordCountList)
println("================================")
// 思路二:直接基于预统计的结果进行转换
// 1. 将字符串打散为单词,并结合对应的个数包装成二元组
val preCountList: List[(String, Int)] = tupleList.flatMap(
tuple => {
val strings: Array[String] = tuple._1.split(" ")
strings.map( word => (word, tuple._2) )
}
)
println(preCountList)
// 2. 对二元组按照单词进行分组
val preCountMap: Map[String, List[(String, Int)]] = preCountList.groupBy( _._1 )
println(preCountMap)
// 3. 叠加每个单词预统计的个数值
// mapValues是对map中的每个value值进行一定的转化, 可以保证key不会变化
val countMap: Map[String, Int] = preCountMap.mapValues(
tupleList => tupleList.map(_._2).sum //tupleList是一个 List: (String, Int)
//使用map(_._2)我们可以去除List每个元素的第二个值, 然后进行相加, 就能够把
//Map( hello -> List((hello,1), (hello,2), (hello,3), (hello,1), (hello,2)))
//变为了 Map(hello -> 1+2+3+1+2)
)
println(countMap)
// 4. 转换成list,排序取前3
val countList = countMap.toList
.sortWith(_._2 > _._2)
.take(3)
println(countList)
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)