

转:http://mt.sohu.com/20160628/n456602429.shtml
我是来自Kyligence的李扬,是上海Kyligence的联合创始人兼CTO。今天我主要来和大家分享一下来Apache Kylin 1.5的新功能和架构改变。

Apache Kylin是什么

Kylin是最近两年发展起来的开源项目,在国外的知名度不是很高,但是在中国广为人知。Kylin的定位是Hadoop大数据平台上的多维分析工具,最早是由eBay在上海的研究实验室孵化的,提供ANSI-SQL接口,支持非常大的数据集,未来期望能够在秒级别返回查询结果。Kylin于2014年10月开源,现在已经成为为数不多的全部由华人主导的Apache顶级项目。
1.SQL Interface

大多数的Hadoop分析工具和SQL是友好的,所以Apache Kylin拥有SQL接口这一点就显得尤为重要。Kylin的ANSI SQL可以替代HIVE的很大一部分工作,如果不使用HIVE本地方言的话,那么Kylin和HIVE几乎完全兼容,也是SQL on Hadoop的一员。
Kylin和其它SQL ON Hadoop的主要区别是离线索引。用户在使用之前先选择一个HIVE Table的集合,然后在这个基础上做一个离线的CUBE构建,CUBE构建完了之后就可以做SQL查询了。SQL数据下的关系表模型和原本的HIVE Table的一模一样,所以原来的HIVE查询可以原封不动的迁移到Kylin上面直接运行。
用离线计算来代替在线计算,在离线过程当中把复杂的、计算量很大的工作做完,在线计算量就会变小,就可以更快的返回查询结果。通过这种方式,Kylin可以有更少的计算量,更高的吞吐量。
2.Big Data
2015年eBay公布Kylin已经有接近千亿的数据规模,2016年肯定已经稳稳的超过千亿了。但是这也可能不是Kylin的最大案例,因为根据我们在中国移动得到的数据,他们每天可能就有百亿的增量数据要放到Kylin的系统里面,可能十天就超过千亿了。国内很多一线互联网企业也都在使用Kylin技术来进行多维数据分析。
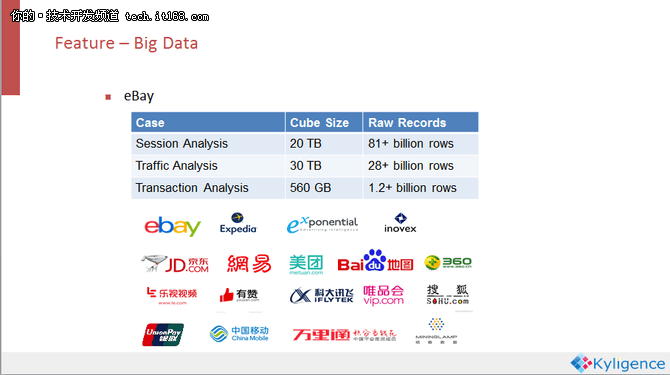
3.Low Latency
Kylin的查询性能相当不错,这也是当初它的设计目标。我们的目标是在秒级别能够返回查询结果,在实际生产系统里面,Kylin 90%的查询都可以在稳定的三秒内返回,而且这并不是一条两条特别的SQL可以做到这个性能,而是在数万条不一样的、在各种复杂的查询下的SQL都可以做到这样。
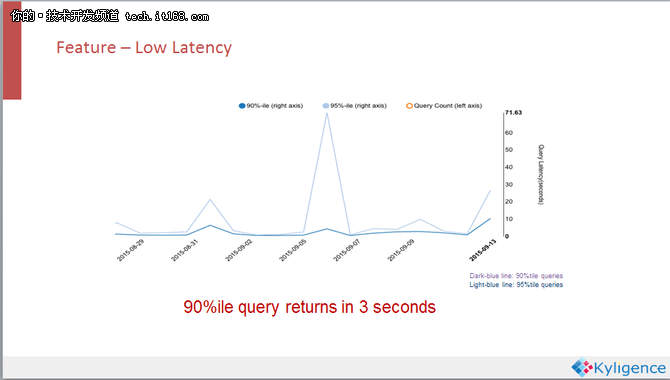
从图中可以看到,在某一天Kylin的查询延迟有一个山峰,所以不是说只要用了Kylin所有的查询就一定快,但是经过调优大多数的查询都会很快速。
4.BI工具的集成
Kylin提供了标准的ODBC和JDBC接口,能够和传统BI工具进行很好的集成。分析师们可以用他们最熟悉的工具来享受Kylin带来的快速。
5.Scalable Throughput
Kylin是用离线计算来代替在线计算,相比于其他的工具,在线计算量较小,能够在固定的硬件配置上面拥有更高的吞吐率。
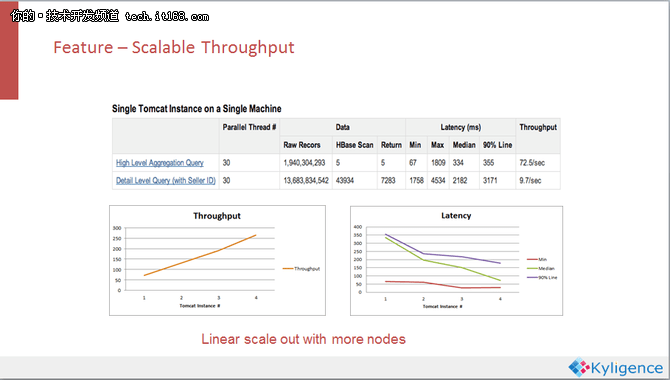
这是在两条比较复杂的查询下查看Kylin的线性扩展能力的实验。我们在一个比较简单的机器上面增加Kylin的查询引擎的个数,从图中可以看出Kylin在从一个实例加到四个实例的过程中吞吐量是呈线性上涨的,Kylin每秒可以支持大约250个查询。当然,这个实验还没有探测到整个系统的瓶颈,根据理论,Kylin系统的瓶颈最后会落在他的存储引擎上面。所以,在存储有保障的前提下,我们可以通过扩展存储引擎来扩展Kylin的吞吐量。
Apache Kylin 1.5新特性
1.可扩展架构
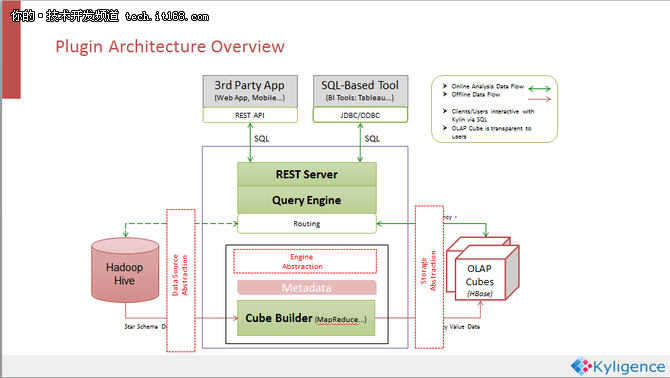
Kylin采用的是一个可扩展的架构。用户的数据首先是落在HIVE里面,然后根据META DATA定义的CUBE描述,进行离线CUBE构建,构建完成的CUBE结果存放在HBase里面。当查询从顶部过来的时候,不管是SQL接口或者是Rest API接口,查询引擎都会把这个查询引导到构建好的CUBE当中去返回结果,不需要再去查原本的HIVE数据,这种方式大大的提高了系统性能。
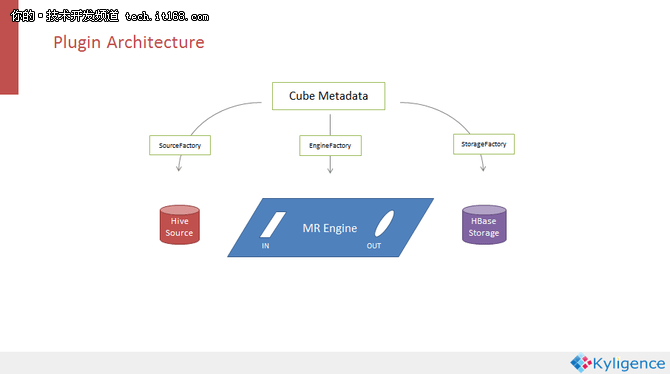
所谓可扩展的架构是指把Kylin三个依赖的接口抽象出来,从而在一定程度上替换它们。Kylin的三大依赖分别是HIVE Source、MapReduce分布式计算引擎以及存储引擎HBase,它们都是通过原数据来驱动的,即需要在CUBE原数据上声明数据源、构建引擎和存储系统。通过工厂类初始化三个依赖,它们之间是没有关联的,彼此不能够了解对方的存在,所以也不能一起工作。后面用个适配器的模式,想象下面MapReduce Engine作为一个主板,它有一个输入槽和一个输出槽,分别用来连接左侧DataSource和右侧的Storage。从HIVE和HBase分别产生构造出一个适配器部件,把它们插在主板上以后,这三个部件就联通了,数据就可以从左侧流到右侧,完成实现整个CUBE构建的过程。

有了上述的基础,我们就可以在Kylin系统上面来尝试不一样的构建引擎、数据源以及存储引擎。我们曾经尝试将Spark作为Kylin CUBE的构建引擎,但是从实验结果来看,Spark引擎暂时并没有带来特别高的性能提升。目前,数据源除了HIVE以外,现在也可以连接Spark和Kafka。存储引擎是大家最为关注的,一开始,选用HBase作为Kylin的存储引擎时,大家都很不解,也有很多人表示为什么不试一下Kudu或者其他的存储引擎呢,有了这个可扩展架构,大家可以亲自来尝试不同的存储引擎。

整个可扩展架构带来了很多好处,首先就是自由度,之前Kylin等于是绑死在Hadoop平台上面,依赖HIVE,MapReduce和HBase。有了这个架构以后,就可以尝试一些不一样的替代技术。其次是可扩展性,系统可以接受各种数据源,例如Kafka,也可以接受更好的分布式计算引擎Spark等。第三是灵活度,不一样的构建算法适合不一样的数据集。有了灵活度以后,就可以在整个系统中同时存在很多种不一样的CUBE构建算法,用户可以根据自己数据集的特性来指定当中的某一个。
2.Layered Cubing
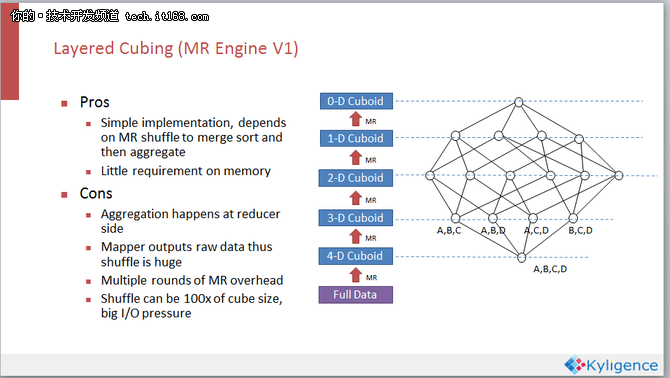
MRv1是一个比较老的CUBE的引擎,采用的是一个非常质朴的CUBE构建算法。上图所示是一个分层的CUBE构建的过程,先Group by A、B、C、D四个维度,算完了这个四级维度的一层以后,再用四级维度的结果来算三级维度的一层,依此类推,分别算出二级和一级维度的结果。
这种分层模式可以利用MapReduce的 shuffling 和 merge sort 做完了很多Aggregation,从而减少开发量。但同时也带来了一些问题,因为Aggregation都发生在Reduce端,Map端是直接把原数据给扔在网络上,然后靠MapReduce的shuffling让数据汇总到Reduce端,所以这就带来了很大的网络开销,而网络又偏偏是大多数Hadoop系统的瓶颈。相关数据显示了这样的Layered Cubing给网络的压力相当于一百个CUBE的大小,也就是说如果CUBE有10T的话,那么网络的压力可能就是一千个T。
3.Fast Cubing
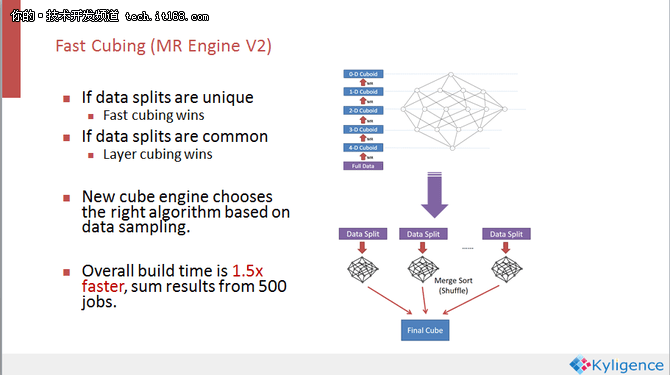
如何解决这个瓶颈问题,下面为大家分享一个新算法Fast Cubing,它是逆向思考,既然数据在Reduce端做聚合会有很多网络压力,那么可不可以把聚合放到Map端来做,然后把聚合完的结果通过网络进行传输,在Reduce端做最终的聚合,这样的话,Reduce端收到的数据就会变少,网络压力就会变轻。目前比较经典的多维分析多是用内存来做多维计算,我们采用类似的技术在Map端分配比较大的内存,用比较多的CPU做In-mem cubing,这样做的效果类似于Layered发生在Map端。这些过程完成之后得到的是已经聚合过的数据,再通过网络分发到Reduce端做最终的聚合。这种方式的缺点是算法较为复杂,开发和维护比较困难,但是可以减轻网络压力。
我们把两个算法放到实际的生产环境当中去比较,发现其实并不总是Fast Cubing会更快。我们期望Map端的预先聚合可以减少网络shuffling,但其实不一定是这样,因为这取决于数据分布。例如我们的期望结果是李扬在十月一号一共买了多少东西,消费总金额是多少,那么这取决于消费记录是只出现在一个data splits里面还是出现在所有的Map的data splits里面。如果记录只出现在一个Map上,那么聚合完的结果不需要去和其他的Map做第二次的聚合,网络分发比较快。但是如果不幸,交易记录被均匀分散到了所有的Map上,那么还是要通过网络分发很多次,然后在Reduce再做第二次的聚合,这样的话相比前面的Layered Cubing没有多少的改进。
如果Map的data splits是比较独特,每个Map会生成不同的CUBE数据,然后分发也不会重复,那么Fast Cubing确实会减少网络的传输。但是反过来,如果每个Map的数据都有雷同,那么就还是会造成网络的压力,所以在MRv2里面最后搭载的是一个混合算法。先对数据做采样,根据数据样本来判断这个数据集在Map上面的分配是独特的还是有重复,然后根据这样的特性来选择采用Layered Cubing 还是Fast Cubing。我们通过在500个不一样的生产环境中的测试发现这种混合算法要比原来的MRv1快1.5倍。
4.Parallel Scan
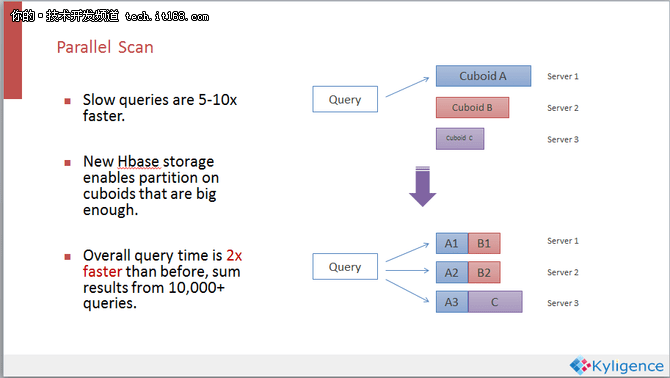
并行扫描是一个十分直观的改进。在之前的Kylin版本里面数据聚合完以后密度非常高,而且因为数据聚合过,返回集很小,不需要扫描太大的数据集就能够返回SQL查询的结果。但是对于一些比较复杂或者本身比较慢的查询,尽管经过了聚合,但是数据还是有百万、千万条,那么在运行时候还是要扫描很多数据,这时候简单的串行扫描显然就不适合了。如果调整一下数据的存储结构,做一些分区。通过扫描物化视图来产生查询结果,把存在一个结点上的物化视图均匀的分散在多个结点上,那么串行扫描就变成了并行扫描。
这个改进可以使慢的查询速度提升五到十倍左右,不过从实际情况来看提升并没有那么多,因为原本大多数Kylin的查询已经比较快了,扫描数据本来就不多。通过对一万条左右生产状态查询结果的比较,我们发现,引入并行扫描的技术之后,速度大概会提升两倍左右。
5.近实时

Apache Kylin 1.5的另一个特性就是近实时的构建,它是延续之前的增量构建。Kylin和很多大数据系统一样,在对数据做预处理的时候,会对数据做一个增量的预处理,即不是把过去所有的数据每天都算一遍,而是每天只计算今天的数据,再去和历史数据做匹配。所以首先要把整个数据集按照时间线来做分割,时间距离最远的数据会比较大块,可能是按年的,中间的可能是按月,最小的一个数据集是今天的。如果要做到近实时的话,只需要把每天增量构建的时间力度进一步的切小,可以从天缩小到小时,小时缩小到分钟,按照这个思路就可以很顺畅的完成近实时的CUBE构建。
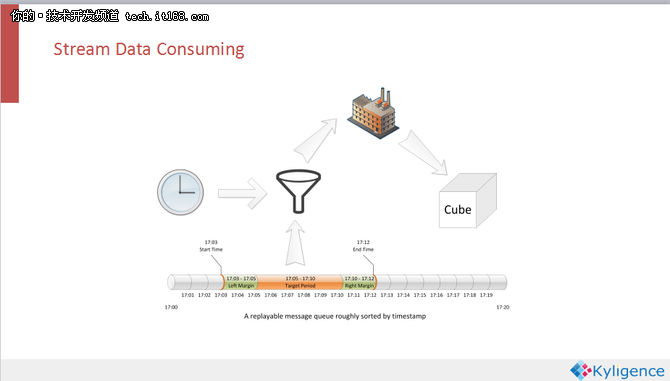
这是我们在1.5里面尝试的一个案例,其中数据源来自Kafka的Source,算法使用Fast Cubing 。这样的搭配看起来很完美,其实不然,它会产生很多的CUBE碎片,例如今天的五分钟就是一个独立的数据集,它会产生一个独立的CUBE碎片。当这个碎片越来越多的时候,查询性能就会下降,一个查询命令需要命中很多个碎片,每一个都要执行存储层的一次Scan的操作。
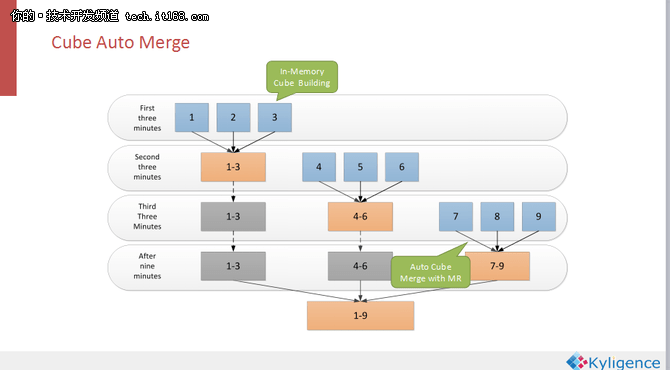
解决的方法也很简单,那就是合并CUBE碎片,但是这个合并是自动的常态,不需人为手工来触发。新版本里用户可以配置自动合并,把五分钟的碎片合并成半小时,半小时合并到四小时,四小时合并到一天,天合并到周,周合并到月。
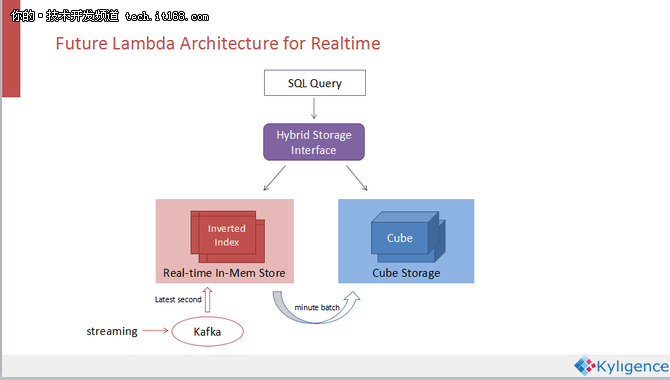
如果五分钟的近实时仍然不满足需求的话,可以把他近化成一个Lambda架构,即在CUBE的存储之外再配上一个实时的内存存储系统来记录最后五分钟的数据。CUBE五分钟近实时离真正的实时就差五分钟的数据,把这些数据放在内存里面,用一个混合的查询接口来同时击中内存引擎和CUBE存储,那么汇总的结果就是一个真实实施的结果集了。但是,遗憾的是目前这个想法还未实现。
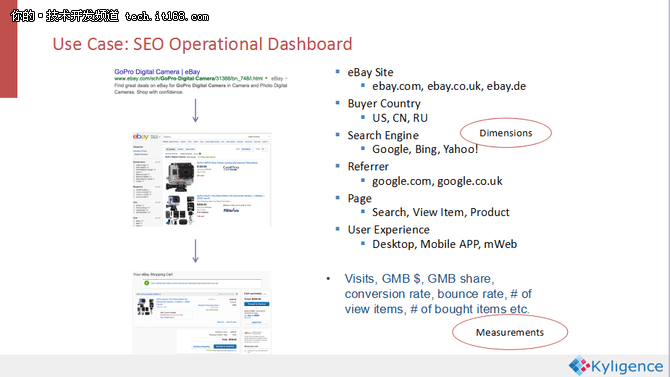
在eBay公布的使用案例里面有一个Kylin新版本近实时CUBE构建的案例——SEO Dashboard,它是对查询引擎导入的用户流量进行监控。实时监控从谷歌或者雅虎进来的消费者的记录,实时监控流量起伏,一旦发现用户流量在五分钟内有抖动的话,立即采取相应的措施,从而保证eBay的交易量营收的稳定。
6.用户自定义聚合类型

1.5的另外一个新功能是User Defined Aggregation Types,即用户自定义聚合类型,以前Kylin有HyperLogLog(近似的Count Distinct算法)。在这个基础上面,新版本又加入了TopN以及社区贡献的基于Big Map的精确Count Distinct和保存最底层原始数据的记录Raw Records。用户可以实现抽象接口扩展自己想要的聚合函数。例如,通过它来聚合很多用户的事件,提取出用户的访问模型,或者做一个很多点样本的一个聚类,也可以把他预计算好,存成一个聚合的数据类型,所以这个自定义的函数可以扩展到很多领域。
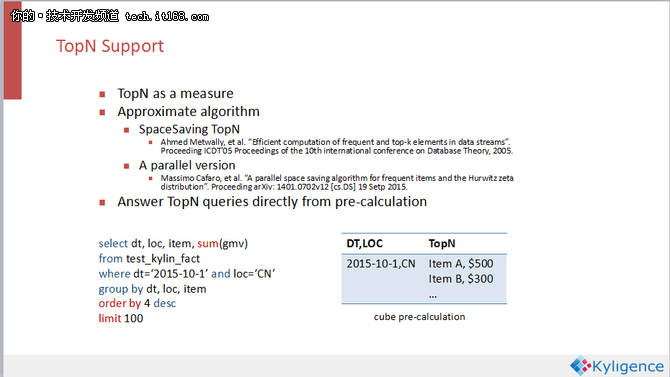
TopN用的是一个很经典的算法,叫SpaceSaving,在很多的流式处理里面都有用到。我们把TopN介入到Kylin里面,定义成一个自定义的聚合函数。一般的SpaceSaving是一个单线程的算法,但是Kylin采用的是并行算法。
用户TopN的查询,例如抓取100个数据,写成SQL语句如上图所示。而Kylin会自动适配这样的SQL来直接使用预聚合好的结果,所以在运行时候Kylin只是把预先算好的一千个,一万个item直接返回就好了,这当中几乎就没有在线计算,速度就会很快。
7.分析工具的集成
在新版本里面Kylin也增加了ODBC的一些接口,主要是实现了对Tableau 9的集成,以及和MS Excel、MS Power BI的集成。
Zeppelin 的集成模块也已经共享在Zeppelin 开源社区,大家可以在Zeppelin 最新的发布版里面找到,另外,直接从Zeppelin 里面也可以调用Kylin的数据。
总结

总的来说,Apache Kylin 1.5有以下几个新亮点:1.可扩展的架构,这个新的架构等于是打开了Kylin对于其他的可替换技术的一个大门,我们可以选择除了MapReduce之外的其他并行计算引擎,比如Spark,也可以选择不一样的数据源,甚至不一样的storage。这样可以保证Kylin可以和其他的并行计算、大数据技术一起来演化而不是锁死在某个平台上面。2.新的CUBE引擎,因为引入了一个新的Fast Cubing的算法,速度提升大概达到原来的1.5倍左右,3.并行扫描,存储结构的改良使查询的速度提升了大约两倍。4.近实时分析,尽管还在产品测试的阶段,但是,大家可以来社区使用,发现问题可以和我们及时沟通。5.用户自定义聚合类型,这个部分在未来应该有很大的发展空间。6.集成了更多的分析工具。
以上就是我想和大家分享的内容,Kylin是个开源产品,所以欢迎大家有兴趣的来使用,并且跟我们在社区上面互动,有任何问题我们社区都是很乐意来帮助大家解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号