

PHP实现中文字符串截取无乱码

在我们学习PHP知识的过程中,PHP截取字符串应该是一个非常常见的字符串基础操作了,想必大家都比较熟悉这方面知识点。 但是有些新手朋友们可能遇到过,当截取中英文字符串时出现乱码的情况,其实这个也是非常容易解决的。 首先我们要了解关于中英文占多少字节的问题。 ASCII码:一个中文汉字占两个字节的空间。 UTF-8编码:一个中文(含繁体)等于三个字节。 Unicode编码:一个中文(含繁体)等于两个字节。 下面我们就通过几个简单的代码示例为大家详细介绍关于PHP截取中英字符串且无乱码的相关知识。 一、关于substr函数截取字符串 <?php echo substr("PHP中文网", 0, 5); substr:返回字符串的子串。 substr()中第一个参数表示要截取的字符串,第二个参数表示从0位置开始截取,第三个参数表示截取长度。 截取“PHP中文网”前5个字节,结果如下:
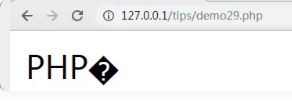
如图显示乱码,也就是说当我们使用substr函数进行中英文字符串截取时,会出现乱码。 二、关于mb_substr函数截取字符串 <?php echo mb_substr("PHP中文网", 0, 5); mb_substr:获取部分字符串。 截取“PHP中文网”前5个字符,结果如下:
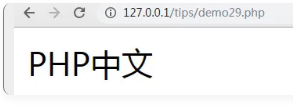
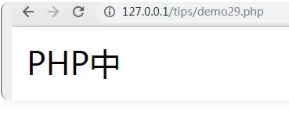
如图截取了前五个字符,并且没有出现乱码。 注:mb_substr是根据字符数来执行截取字符串。 三、关于mb_strcut函数截取字符串 <?php echo mb_strcut("PHP中文网", 0, 7); 截取“PHP中文网”前7个字节,结果如下:
从图中可以看到,我们要截取7个字节,但是只显示截取了“PHP中”这6个字节。由于一个汉字等于三个字节,那么这里第7个字节就不会显示了。
综上所述,如果大家遇到要截取中文字符串并无乱码的需求时,可以选择后两种方法(mb_substr()和mb_strcut())


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架