

MySQL高级应用(二进制日志、备份和还原、复制、查询优化)
一、MySQL二进制应用
1.1 启动二进制日志
使用MySQL命令“show variables like 'log_bin';”可以查看二进制日志是否开启,默认为OFF,表示没有开启二进制日志。在MySQL配置文件my.ini的[mysqld]选项组中,添加"log_bin=D:\db_data\mysqllog\binary_log"可以开启二进制日志。参数log_bin的值定义了二进制日志文件名。二进制日志参数一旦开启,MySQL将自动创建二进制日志文件,如binary_log.000001。每次重启MySQL服务后,都会生成一个新的二进制文件,扩展名数字一次递增,如binary_log.000002、binary_log.000003等。
另外,MySQL还会创建一个二进制日志索引文件,使用MySQL命令“show variables like 'log_bin_index';”,可以查看二进制日志索引文件名(如binary_log.index)。二进制日志索引文件的内容时所有二进制日志文件的清单,它记录了所有二进制日志文件的绝对路径。
1.2 查看二进制日志文件的内容
由于二进制日志文件的内容以事件的方式进行存储,数据库管理人员可以使用MySQL命令"show binlog events"方便地查看二进制日志文件的内容,语法格式如下:
show binlog events in '二进制日志文件名' [from position] [end position] [length]
show binlog events in '二进制日志文件名' [from position] [end positino] [length]
选项解析如下:
(1)from position:position指定查看二进制日志文件的起始位置,不指定就是将该二进制日志文件的首个位置作为起始点。
(2)end position:position指定查看二进制日志文件的位置终止点,不指定就是将该二进制日志文件的末尾位置点作为终止点。
(3)length:查询总条数,不指定就是查询所有行。
1.3 使用二进制日志文件恢复数据库
二进制日志文件的内容是符合MySQL语法格式的更新语句,当数据库遭到破坏时,数据库管理人员可以借助mysqlbinlog工具,读取二进制日志文件中指定的日志内容,并将该日志内容复制、粘贴到MySQL客户机中直接运行,将数据库恢复到正确的状态。也可以使用管道操作符"|",直接将指定的二进制日志内容导入到MySQL客户机中运行,管道操作符"|"的使用方式如下:
mysqlbinlog 日志文件 | mysql -u 用户 -p
mysqlbinlog 日志文件 | mysql -u 用户 -p
例如,基于操作点恢复被删除的数据,
mysqlbinlog --no-defaults D:\db_data\mysqllog\binary_log.000001 -- stop-position=725 | mysql -uroot -p
二、MySQL备份和还原
2.1 数据备份的意义
数据丢失对企业而言都是个噩梦,业务数据与企业日常业务运作唇齿相依,损失这些数据,即使是暂时性的,也会威胁到企业辛苦得来的竞争优势,更可能摧毁公司的声誉并引发安规的诉讼和索偿费用。
制定一套合理的备份策略尤为重要,可以让数据库管理员全局掌控数据库的备份和恢复,以下时数据库管理员可以思考的一些影响备份合理性因素。
(1)数据库要定期备份,备份的周期应当根据应用数据系统可承受的恢复时间来确定,而且定期备份的时间应当在系统负荷最低的时候运行。对于重要的数据,要保证在极端情况下的损失都可以正常恢复。
(2)定期备份后,同样需要定期做恢复测试,了解备份的正确可靠性,确保备份是有意义的、可恢复的。
(3)根据系统需要来确定是否采用增量备份,增量备份只需要备份每天的增量数据,备份花费的时间少,对系统负载的压力也小。
(4)确保MySQL打开了log_bin选项,MySQL在做完整恢复或者基于时间点恢复时都需要binlog。
(5)可以考虑异地备份。
2.2 逻辑备份
(1)使用mysqldump备份数据库
MySQL命令“select...into outfile...”产生的副本文件中仅包含了表记录数据,不包含数据库表结构的定义。有时不仅需要备份表记录,还需要备份表结构,可以选用MySQL转储数据库时常用的自带工具mysqldump来备份表结构。
1)备份所有数据库
打开cmd窗口,执行以下mysqldump命令:
mysqldump -uroot -p --all-database>d:\db_backup\alldb.sql
接着输入root账户的密码,打开alldb.sql,可以发现所有数据库、数据表的创建,以及表中记录的新增insert语句都包含在alldb.sql文件中。
2)备份部分数据库
mysqldump -uroot -p --database novel>d:\db_backup\novel.sql mysqldump -uroot -p --database user>d:\db_backup\user.sql
mysqldump -uroot -p --database novel user>d:backup\novel_user.sql
3)备份数据库中的表
例如,备份数据库novel的book表,如下:
mysqldump -uroot -p novel book>d:\db_backup\book.sql
(2)备份数据库时的一致性问题
1)同一时刻取出所有数据
对于事务支持的存储引擎,如Innodb或BDB等,可以通过控制将整个备份过程保持在同一个事务中,使用“--single-transaction”选项,具体如下:
(1)在同一时刻备份数据库novel,命令如下:
mysqldump -uroot -p --single-transaction -- database novel>d:\db_backup\novel.sql
(2)在同一时刻备份数据库novel的数据表book,命令如下:
mysqldump -uroot -p --single-transaction novel book>d:\db_backup\novel_book.sql
2)数据库中的数据处于静止状态
通过以下锁表参数,可以保证数据库中的数据处于静止状态。
(1)--lock--tables每次锁定一个数据库的表,此参数默认为true。
(2)--lock-all-tables一次锁定所有的表,适用于dump的表分别处于各个不同的数据库中的情况。
2.3 使用source命令还原数据库
语法:source filename.sql
例如,使用source命令还原novel数据库,代码如下:
source d:\db_backup\novel.sql
注意:
(1)执行source命令前必须使用use语句选择好数据库。
(2)只能在cmd界面执行,不能在mysql工具里面执行source命令,否则会报错。因为cmd时直接调用mysql.exe来执行命令的,而这些诸如Navicat for MySQL的编辑工具,只是利用MySQL Connector连接MySQL来管理MySQL,并不是直接调用mysql.exe。
2.4 MySQL存储引擎和物理备份
数据库中的数据以文件的方式组织在一起,物理备份最简单的实现方法就是对这些文件进行复制、粘贴。但是如果在物理备份期间,MySQL服务实例没有关闭,备份过的数据可能已经发生变化,此时需要借助热备份工具实现物理备份。
InnoDB和MyISAM是许多人在使用MySQL时最常用的两个表类型,这两个表类型各有优劣,视具体应用而定。基本的差别为MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。MyISAM类型的表强调的是性能,其执行速度比InnoDB类型更快,但是不提供事务支持;而InnoDB提供事务支持以及外部键等高级数据库功能。
(1)MyISAM存储引擎
MyISAM表的所有数据存放在数据库目录中,每个MyISAM表都存在3个文件:FRM文件、MYD文件以及MYI文件,它们分别为数据定义文件、数据文件和数据索引文件。备份MyISAM表时,只需备份每个标的FRM文件、MYD文件以及MYI文件即可。
(2)InnoDB存储引擎
每个InnoDB表都存在FRM文件和表空间文件(分为独享表空间和共享表空间)。表空间文件的后缀为ibd,InnoDB引擎开启了独立表空间(my.ini中配置innodb_file_per_table=1)产生的存放该表的数据和索引的文件。
由于InnoDB时一个事务安全的存储引擎,事务安全主要是通过重做日志以及回滚日志实现。默认情况下,重做日志的信息记录在ib_logfile0文件以及ib_logfile1文件中,回滚日志的信息记录在表空间文件中。因此,备份innoDB表时,不仅需要备份表空间文件、FRM文件,还需要备份重做日志文件,如ib_logfile0文件和ib_logfile1文件。
(3)物理备份的3种方式
1)冷备份
进行物理备份时,如果关闭MySQL服务实例,只需复制上面列举的文件到指定盘符,即可实现数据库的物理备份,这种备份称作冷备份。
2)温备份
MySQL服务实例一旦关闭,将无法为数据库用户提供更新服务,甚至无法为数据库用户提供数据查询服务。在MySQL服务实例开启的情况下,使用MySQL命令"flush tables with read lock;"锁定所有数据库表后,再复制上面列举的文件到指定盘符,即可实现数据库的物理备份,这种备份称作温备份。温备份期间MySQL服务实例仅可以为数据库用户提供查询服务。一旦所有数据库表施加读锁操作,MySQL服务实例将无法为数据库用户提供数据更新服务。
3)热备份
在MySQL服务实例开启的情况下,在数据备份的同时,数据库的查询和更新均不受影响,这种备份称作热备份。MySQL以及第三方公司提供了热备份工具,如mysqlhotcopy、Xtrabackup等,这些工具帮助数据库管理员实现MySQL数据库的物理备份。
三、MySQL复制
3.1 复制的概念
MySQL支持一台主服务器同时向多台从服务器进行复制操作,从服务器同时可以作为其他服务器的主服务器。如果MySQL主服务器的访问量比较大,通过复制技术,可使从服务器来响应用户的查询操作,从而降低了主服务器的访问压力,同时从服务器也可以作为主服务器的备份服务器。
一般而言,数据库复制技术可以从以下几个方面改善分布式数据库集群系统的功能和性能。
(1)可用性。数据库集群系统具有多个数据库节点,在单个或多个节点出现故障的情况下,其他正常节点可以继续提供服务。
(2)性能。多个节点一般可以并行处理请求,从而避免单个节点出现性能瓶颈,一般至少可以提高度操作的并发性能。
(3)可扩展性。单个数据库节点的处理能力毕竟有限,增加节点数量可以显著提高整个集群系统的吞吐率,实现数据库的分布和负载均衡。
(4)备份。可以在从服务器上进行备份,以避免备份期间影响主服务的服务。
3.2 复制的实现
MySQL数据库复制操作可以分为以下几个步骤:
(1)master启用二进制日志功能。
(2)slave的I/0进程与master进行连接,并请求指定日志文件中指定位置(或从最开始位置)之后的日志内容。
(3)master接收来自slave的I/O进程的请求之后,通过负责复制的I/O进程,根据请求消息读取指定日志指定位置之后的日志信息,返回给slave的I/O进程。返回信息除了日志所包含的信息之外,还包括来自master端的二进制日志文件的名称以及操作点的位置(position)。
(4)slave的I/O进程接收到消息后,将接收到的日志内容依次添加到slave端的中继日志文件的最末端,并将读取到的master端的二进制日志文件的文件名和操作点位置记录到master info文件中。
(5)slave的SQL进程检测到中继日志文件中新增加的内容后,会马上解析中继日志文件的内容,并执行中继日志文件中新增加的SQL脚本。
3.3 MySQL主从复制步骤
(1)master主服务器配置。
1)配置主服务器数据库配置文件。
修改主服务器MySQL数据库的my.ini配置文件(在Linux系统中,该文件为my.cnf),一般情况下该文件位于MySQL主安装目录下。具体配置内容如下:
(1)server_id=1。server_id属性值为数据库ID,此ID唯一不能重复,否则主从复制会发生错误。
(2)log_bin= binary_log。log_bin属性值为MySQL二进制日志文件名。此项为必填项,否则不能实现主从复制;如果该项值为空,则以计算机名字加编号来命名二进制日志文件名。
(3)binlog_do_db=novel。binlog_do_db属性值为需要同步的数据库名。如果需要同步另外的数据库,则重复设置binlog_do_db。如果未设置binlog_do_db,则默认同步所有的数据库。
(4)binlog_ignore_db=mysql。binlog_ignore_db属性值为不需要同步的数据库名。
2)重启主服务器数据库
修改完主服务器MySQL数据库配置文件后,需要重启MySQL服务。停止MySQL服务的命令是“net stop mysql”,启动MySQL服务的命令是“net start mysql”。
3)在主服务器数据库添加用于同步的账号
在主服务器数据库添加用于同步的账号test1,该账号密码为123456,并仅能从192.168.1.87登录master服务器。为了实现主从复制,必须要求test1账户拥有replication slave权限,该权限将直接授予slave服务器。具体命令如下:
grant replication slave on *.* to test1@'192.168.1.87' identified by '123456';
或者授予test1账户所有的权限,具体命令如下:
grant all privileges on *.* to test1@'192.168.1.87' identified by '123456' with grant option;
“with grant option”表示该用户可以给其他用户授权。
4)显示主服务器最新状态信息
执行“show master status;”命令,可以查看master数据库当前正在使用的二进制日志文件及当前执行二进制日志文件的位置。其中file值为当前使用的二进制日志文件名,position值为当前执行的二进制日志文件的位置。
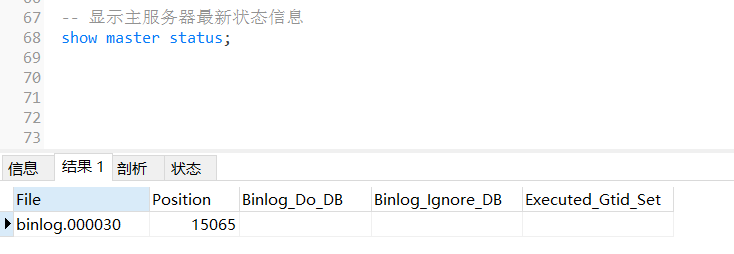
master主服务器把对数据库操作的指令都记录到binary_log.000030中,slave从服务器通过读取该文件来对slave服务器数据库中的数据进行修改,从而达到主从同步的效果。
(2)slave从服务器配置。
1)配置从服务器数据库配置文件
只需要配置从服务器数据库配置文件的server_id即可,需要注意的是该server_id的值不能与主服务器数据库配置文件的server_id的值相同。(注意:凡是修改了数据库配置文件,必须重启数据库)
2)停止从服务器的slave线程
使用命令“stop slave;”可以停止从服务器的slave线程。
3)设置从服务器实现主从复制
使用命令“change master to”可以设置从服务器实现主从复制,代码如下所示:
change master to master_host='192.168.1.87',master_user='test1',master_password='123456',master_log_file='binary_log.000030',master_log_pos='15065';
命令参数说明如下:
(1)master_host:主服务器IP。
(2)master_user:连接主服务器的账户。
(3)master_password:连接主服务器的账户密码。
(4)master_log_file:当前主服务器正在使用的二进制日志文件。
(5)master_log_pos:当前主服务器正在使用的二进制日志文件的操作点位置。
注意:这里的master_log_file、master_log_pos的值要与master主服务器的值一致,否则将无法实现主从复制(同步)。
4)开启从服务器的slave线程
使用命令“start slave;”可以启动从服务器的slave线程。
5)显示从服务器最新状态信息
执行“show slave status \G;”命令,用于显示从服务器的最新状态信息。Slave_IO_Running和Slave_SQL_Running的值均为YES,表明从服务器的I/O进程和SQL进程均处于运行状态。Slave_IO_Running和Slave_SQL_Running是从服务器上的两个关键进程,Slave_IO_Running负责与主服务器通信,Slave_SQL_Running负责从服务器自身的MySQL进程,只有这两个都开启了才能实现主从同步。
6)测试主从复制的正确性
在主服务器上执行一个更新操作(insert、update和delete),观察是否在从服务器上同步执行更新。
四、MySQL查询优化
4.1 数据库查询优化介绍
查询优化就是选择一个高效的查询处理策略。
查询优化有许多方法,按照优化的层次一般可以分为代数优化和物理优化。代数优化是指关系代数表达式的优化,即按照一定的规则,改变代数表达式中操作的次序和组合,使查询执行更高效;物理优化则是指存取路径和底层操作算法的选择。选择的依据可以是基于规则的,也可以是基于代价的,还可以是基于语义的。
4.2 基于索引的优化
索引是依赖于表建立的,它包含索引键值及指向数据所在页面和行的指针。通常,索引页面相对于数据页面而言要小得多。当进行数据检索时,系统先搜索索引页面,从中找到所需数据的指针,然后再直接通过指针从数据页面中读取数据。可以通过一下规则对MySQL索引进行优化:
(1)前导模糊查询不能使用索引。
(2)union、in、or都能够命中索引,建议使用in。
(3)负向条件查询不能使用索引,可以优化为in查询。
(4)满足联合索引最左前缀原则。
(5)使用范围列查询可以使用索引。
(6)把计算放到业务层而不是数据库层。
(7)尽量避免强制类型转换,因为这将导致全表扫描。
(8)更新十分频繁、数据区分度不高的字段上不宜建立索引。
(9)被查询列要被所建的索引覆盖。
(10)如果有order by、group by的场景,请注意利用索引的有序性。
(11)业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。
(12)单索引字段数不允许超过5个。
注意:
在使用索引字段作为条件时,如果该索引是组合索引,那么必须使用该索引中的第一个字段作为条件,才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能地让字段顺序与索引顺序一致。
4.3 where子句优化
(1)避免在where子句中对字段进行null值判断。在where子句中对字段进行null值判断,这将导致数据库引擎放弃使用索引而进行全表扫描,而全表扫描耗费数据库资源,延长检索时间。
(2)避免在where子句中使用 != 或 <> 操作符。应避免在where子句中使用!=或<>操作符,否则数据库引擎将放弃使用索引而进行全表扫描。
(3)慎用 in 和 not in 。in和not in会使系统无法使用索引,而只能直接搜索表中的数据。如果in范围内的值是连续的,可以用“between...and”替换in。如果必须用in,则应将in后面值的列表中可能出现最频繁的值放在最前面,出现得最少的放在最后面,这样可以减少判断的次数。
例如:
select id from user where num in (1,2,3);
应改写为:
select id from user where num between 1 and 3;
(4)避免在where子句中对字段进行表达式操作。应尽量避免在where子句中对字段进行表达式操作,否则数据库引擎将放弃使用索引而进行全表扫描。
例如:
select * from product where current_price/2=20;
应改写为:
select * from product where current_price=20*2;
例如:
select * from record where substring(card_no,1,4)='1234';
-- 库函数substring(str,start,length)的作用是从字符串str的第start个位置开始获取length长度的字符串。
应改写成:
select * from record where card_no like '1234%';
(5)避免在where子句的“=”左边进行运算。避免在where子句的“=”左边进行函数运算、算术运算或其他表达式运算。
(6)尽量使用exists。
例如:
select title, current_price from product where area_id in (select area_id from area where area_name='南湖' or area_name='西湖');
可以替换成使用exists,这样查询效率会提升。
select title, current_price from product where exists (select 1 from area where (area_name='南湖' or area_name='西湖') and area_id=product.area_id);
4.4 子查询性能优化
(1)尽量使用连接查询代替子查询。
(2)not in、not exists子查询可以改为left join代替。
(3)in、exists子查询可以用inner join代替。
(4)in子查询用exists代替。
(5)使用left join或exists判断是否存在记录。不要用含有count(*)的子查询判断是否存在记录,最好使用left join或exists。
例如,
select area_name from area where (select count(*) from product) where area_id=area.area_id)=0;
应改写成:
select area_name from area left join product on area.area_id=product.area_id where product.area_id is null;
(6)尽量避免嵌套(nest)子查询。查询嵌套层次越多,效率越低,因此应当尽量避免嵌套子查询。
(7)过滤(filter)记录行。子查询中尽量过滤出尽可能多的记录行。
4.5 其他SQL语句优化
(1)查询时按需取材。
(2)避免或简化排序。
(3)尽量在group by子句、having子句之前剔除多余的行。
(4)消除对大型表数据的顺序存取。
(5)尽量用distinct(唯一),不要用group by。如果group by的目的不包括计算,只是分组,那么使用distinct速度更快。
(6)避免困难的正规表达式。
like关键字支持通配符匹配,技术上称为正规表达式,但这种匹配特别耗费时间,例如,
select * from customer where zipcode like '98_ _ _';
即使在zipcode字段上建立了索引,但在这种情况下也还是采用顺序扫描的方式,如果将语句修改为:
select * from customer where zipcode > '98000';
在执行查询时就会利用索引来处理查询,显然会大大提高检索速度。
(7)尽量使用存储过程。因为存储过程将数据的处理工作放在服务器上,减少了网路的开销。
(8)尽量少用视图,特别是嵌套视图。
由于对视图操作比直接对表操作慢,所以在执行逻辑复杂的查询时,可以考虑使用存储过程来代替视图。使用视图时,有下列两点要注意:
1)尽量不要使用嵌套视图,因为嵌套视图增加了寻找原始资料的难度。
2)对单个表检索数据,不要使用指向多个表的视图,应该直接从表或仅包含该表的视图上读取。
(9)SQL语句中的字段值要与数据类型精确匹配
select emp_name from employee where salary>3000;
分析此语句,若salary时float(或decimal)类型的,则数据库对其自动执行类似语句“convert(float,3000)”用于将int转为float型的3000。因此当salary为float类型时,为了避免等到运行时才让DBMS进行转化而影响执行效率,应改写为:
select emp_name from employee where salary > 3000.0;
本文来自博客园,作者:爱吃糖的橘猫,转载请注明原文链接:https://www.cnblogs.com/sglblog/p/15240377.html

