

lstm+crf
1.介绍
基于神经网络的方法,在命名实体识别任务中非常流行和普遍。在文献【1】中,作者提出了Bi-LSTM模型用于实体识别任务中,在模型中用到了字嵌入和词嵌入。本文将向你展示CRF层是如何工作的。
如果你不知道Bi-LSTM和CRF是什么,你只需要记住他们分别是命名实体识别模型中的两个层。
1.1开始之前
我们假设我们的数据集中有两类实体——人名和地名,与之相对应在我们的训练数据集中,有五类标签:
B-Person, I- Person,B-Organization,I-Organization, O
假设句子x由五个字符w1,w2,w3,w4,w5组成,其中【w1,w2】为人名类实体,【w3】为地名类实体,其他字符标签为“O”。
1.2BiLSTM-CRF模型
以下将给出模型的结构:
第一,句子x中的每一个单元都代表着由字嵌入或词嵌入构成的向量。其中,字嵌入是随机初始化的,词嵌入是通过数据训练得到的。所有的嵌入在训练过程中都会调整到最优。
第二,这些字或词嵌入为BiLSTM-CRF模型的输入,输出的是句子x中每个单元的标签。
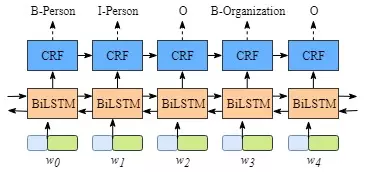
图1. Bi-LSTM结构图
尽管一般不需要详细了解BiLSTM层的原理,但是为了更容易知道CRF层的运行原理,我们需要知道BiLSTM的输出层。
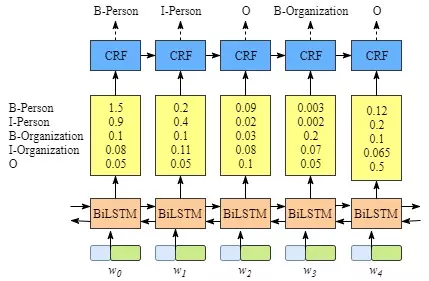
图2.Bi-LSTM标签预测原理图
如上图所示,BiLSTM层的输出为每一个标签的预测分值,例如,对于单元w0,BiLSTM层输出的是1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) and 0.05 (O). 这些分值将作为CRF的输入。
1.3 如果没有CRF层会怎样
你也许已经发现了,即使没有CRF层,我们也可以训练一个BiLSTM命名实体识别模型,如图3.所示:
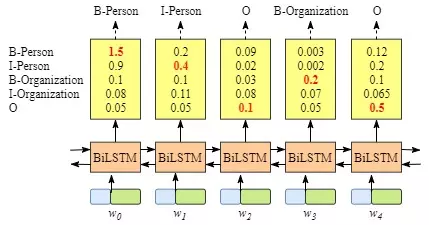
图3.去除CRF的BiLSTM命名实体识别模型
由于BiLSTM的输出为单元的每一个标签分值,我们可以挑选分值最高的一个作为该单元的标签。例如,对于单元w0,“B-Person”有最高分值—— 1.5,因此我们可以挑选“B-Person”作为w0的预测标签。同理,我们可以得到w1——“I-Person”,w2—— “O” ,w3——“B-Organization”,w4——“O”。
虽然我们可以得到句子x中每个单元的正确标签,但是我们不能保证标签每次都是预测正确的。例如,图4.中的例子,标签序列是“I-Organization I-Person” and “B-Organization I-Person”,很显然这是错误的。
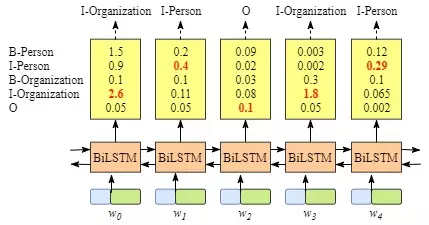
图4. 去除CRF层的BiLSTM模型
1.4CRF层能从训练数据中获得约束性的规则
CRF层可以为最后预测的标签添加一些约束来保证预测的标签是合法的。在训练数据训练过程中,这些约束可以通过CRF层自动学习到。
这些约束可以是:
I:句子中第一个词总是以标签“B-“ 或 “O”开始,而不是“I-”
II:标签“B-label1 I-label2 I-label3 I-…”,label1, label2, label3应该属于同一类实体。例如,“B-Person I-Person” 是合法的序列, 但是“B-Person I-Organization” 是非法标签序列.
III:标签序列“O I-label” is 非法的.实体标签的首个标签应该是 “B-“ ,而非 “I-“, 换句话说,有效的标签序列应该是“O B-label”。
有了这些约束,标签序列预测中非法序列出现的概率将会大大降低。
原文:https://blog.csdn.net/qq_41853758/article/details/82749981

 浙公网安备 33010602011771号
浙公网安备 33010602011771号